در اصول اولیه طراحی API، قابلیت کش شدن (Cacheability) به چه معناست؟

طراحی یک API با در نظر گرفتن قابلیت کش شدن، مجموعهای منطقیتر و بهتر تفکیکشده از منابع ایجاد میکند، و اتفاقاً نتیجهاش این است که API پرفورمنس بالاتری دارد، ارزانتر است و برای محیط زیست هم بهتر است.
کش کردن API میتواند مقدار قابل توجهی از کار سرورها را کم کند، هزینهها را پایین بیاورد، و حتی به کاهش اثر کربنی یک API کمک کند. با این حال، اغلب بهعنوان یک بهینهسازی در نظر گرفته میشود نه چیزی که واقعاً هست: بخشی جداییناپذیر از طراحی API.
یکی از بخشهای بنیادی REST این است که APIها «قابلیت کش شدن» منابع را اعلام کنند. هنگام کار با HTTP گزینههای شگفتانگیز زیادی برای کش کردن از طریق HTTP Caching در دسترس است؛ مجموعهای از استانداردها که نحوه کارکرد کل اینترنت را ممکن میکنند. از این قابلیت میتوان برای طراحی APIهای مفیدتر استفاده کرد، و در عین حال سریعتر، ارزانتر و پایدارتر هم بود.
کش کردن HTTP چیست؟
کش کردن HTTP به کلاینتهای API (مثل مرورگرها، اپهای موبایل، یا سایر سیستمهای بکاند) میگوید آیا لازم است بارها و بارها همان داده را درخواست کنند، یا میتوانند از دادهای که از قبل دارند استفاده کنند. این کار با هدرهای HTTP روی پاسخها انجام میشود که به کلاینت میگویند تا چه مدت میتواند آن پاسخ را «نگه دارد»، یا چطور بررسی کند که هنوز معتبر هست یا نه.
این موضوع کاملاً متفاوت از ابزارهای کش سمت سرور مثل Redis یا Memcached است که داده را روی سرور کش میکنند.
کش HTTP در سمت کلاینت یا روی پراکسیهای میانی مثل شبکههای توزیع محتوا (CDNها) اتفاق میافتد؛ یعنی بهعنوان یک واسطه بین کلاینت و سرور عمل میکنند و تا جایی که ممکن باشد پاسخها را برای استفاده مجدد ذخیره میکنند.
کش سمت سرور را اینطور تصور کنید: راهی برای رد کردن کارهای اپلیکیشن مثل فراخوانی دیتابیس یا درخواستهای HTTP خروجی، با گرفتن نتایج از پیش محاسبهشده از Redis یا Memcached. کش کردن HTTP ترافیک و بار محاسباتی را حتی بیشتر کاهش میدهد؛ چون تعداد درخواستهایی را کم میکند که اصلاً به سرور میرسند، و تعداد پاسخهایی را هم کاهش میدهد که باید تولید شوند.
چطور کار میکند؟
کش HTTP توسط cache headers هدایت میشود. در سادهترین حالت، وقتی یک API پاسخ ارسال میکند، دستورالعملهایی هم ضمیمه میکند که به کلاینت و سایر اجزای شبکه مثل CDNها میگوید آیا مجاز هستند پاسخ را کش کنند یا نه، و اگر بله برای چه مدت.
راهنمای پاسخهای API بهطور خلاصه هدر Cache-Control را معرفی کرد:
HTTP/2 200 OK
Content-Type: application/json
Cache-Control: public, max-age=18000
{
"message": "I am cached for five minutes!"
}اینجا سرور به کلاینت (و هر پراکسی کش) میگوید که میتوانند این پاسخ را به مدت ۵ دقیقه کش کنند، و حتی میتوانند آن را با سایر کلاینتها هم به اشتراک بگذارند. یعنی یک کلاینت میتواند تا ۵ دقیقه از این داده استفاده کند بدون این که دوباره به سرور سر بزند، و وقتی آن زمان تمام شد، یک درخواست جدید ارسال میکند.
گرفتن داده، پردازش آن، و ارسالش به کلاینت زمان و منابع مصرف میکند. حتی وقتی همه این فرآیندها تا حد ممکن بهینه شده باشند، اگر داده تغییر نکرده، چرا باید این درخواستها را تکرار کرد؟ بهجای این که منابع را صرف پاسخ دادن مکرر به درخواستهای یکسان کنیم، سرور میتواند درخواستهای مفیدتری را پردازش کند، انرژی ذخیره کند، و با کاهش ظرفیت غیرضروری سرور پول بیشتری هم ذخیره کند.
هدر Cache-Control
این هدر در RFC 9111: HTTP Caching تعریف شده و قوانین را مشخص میکند. به کلاینتها میگوید با پاسخ چه کار کنند:
- Cache-Control: max-age=3600 — کلاینت میتواند تا یک ساعت (۳۶۰۰ ثانیه) از این داده استفاده کند بدون این که با سرور چک کند.
- Cache-Control: no-cache — کلاینت باید قبل از استفاده از نسخه کششده، با سرور چک کند.
- Cache-Control: public or private — مشخص میکند فقط کلاینت یا همه (مثل پراکسیها) میتوانند آن را کش کنند.
این دستورها را میتوان در ترکیبهای مختلف کنار هم گذاشت تا کنترل بیشتری ایجاد شود، و گزینههای پیشرفته مفیدی مثل s-maxage هم وجود دارد که تعیین میکند داده روی کشهای اشتراکی مثل CDNها چه مدت زنده بماند.
برخی APIهای ساده فقط از Cache-Control برای مدیریت کش استفاده میکنند، اما یک ابزار قدرتمند دیگر هم در جعبه ابزار کش وجود دارد: ETag.
هدر ETag
ETagها (مخفف “Entity Tags”) مثل اثر انگشت یک نسخه خاص یا یک نمونه مشخص از یک منبع هستند. وقتی منبع تغییر میکند، ETag هم تغییر میکند. هیچ دو نسخهای از یک منبع نباید ETag یکسان داشته باشند، و ETag نسبت به URL منبع یکتا است.
وقتی سرور یک پاسخ ارسال میکند، میتواند هدر ETag را هم اضافه کند تا آن نسخه از منبع را مشخص کند:
HTTP/2 200 OK
Content-Type: application/json
ETag: "abc123"
{
"message": "Hello, world!"
}بعد وقتی به هر دلیل همان درخواست دوباره تلاش میشود، کلاینت یک درخواست میفرستد که ETag را داخل هدر If-None-Match دارد. این کار عملاً میگوید: «فقط وقتی پاسخ را دانلود کن که ETag با این متفاوت باشد.»
GET /api/resource HTTP/2
If-None-Match: "abc123"اگر سرور با 304 Not Modified پاسخ بدهد، به کلاینت میگوید: «آن پاسخ هنوز معتبر است. از آن زمان چیزی تغییر نکرده، پس لازم نیست دوباره دانلودش کنی.»
اگر داده تغییر کرده باشد، سرور داده جدید را همراه با یک ETag جدید برمیگرداند.
این موضوع بهویژه برای پاسخهای بزرگ که زیاد تغییر نمیکنند خیلی مفید است، مخصوصاً وقتی با Cache-Control ترکیب شود. ارسال همزمان Cache-Control و ETag به کلاینت اجازه میدهد با اطمینان برای مدتی از داده استفاده مجدد کند بدون این که حتی لازم باشد یک درخواست HTTP به سرور بفرستد، و بعد از پایان آن مدت بهجای دانلود دوباره کل پاسخ، فقط یک بررسی تغییرات انجام دهد.
همه اینها بدون این انجام میشود که کلاینت لازم باشد چیزی درباره داده بداند، یا بداند داده کجا ذخیره شده، یا چطور تولید میشود. سرور همه چیز را مدیریت میکند و کلاینت فقط به درخواست کردن ادامه میدهد، و این باعث میشود HTTP client که «cache-aware» است کار سنگین را انجام دهد.
استفاده از Cache-Control و ETagها در کد
بیایید این هدرها را به یک API ساده Express.js اضافه کنیم تا ببینیم در سمت سرور ممکن است چه شکلی باشد.
ETag با هش کردن داده ساخته میشود، سپس سرور بررسی میکند آیا کلاینت آخرین نسخه را دارد یا نه. اگر داشته باشد، پاسخ 304 Not Modified میدهد، و اگر نداشته باشد، داده را همراه با هدرهای ETag و Cache-Control ارسال میکند.
در یک کدبیس واقعی، معمولاً کارهایی مثل گرفتن داده از یک منبع داده (datasource) یا محاسبه چیزی که زمانبر است انجام میشود، پس این که صبر کنیم همه آنها انجام شود فقط برای این که یک ETag بسازیم ایدهآل نیست. بله، از تبدیل داده به JSON و ارسالش روی شبکه جلوگیری میکند، اما اگر API قرار است آن را نادیده بگیرد و یک هدر 304 Not Modified بدون بدنه پاسخ بدهد، داده بیدلیل load و هش شده است.
بهجای آن، میتوان ETag را از metadata ساخت، مثل timestamp آخرین بهروزرسانی یک رکورد دیتابیس.
این مثال یک هش SHA1 از زمان بهروزرسانی میسازد که هر بار رکورد تغییر کند بهطور خودکار تغییر میکند. لازم نیست نام منبع Trip را مشخص کنید یا حتی trip ID را ذکر کنید، چون ETag نسبت به URL یکتا است و URL خودش از قبل یک شناسه یکتا محسوب میشود.
وقتی با منابعی کار میکنید که مفهوم نسخهبندی مخصوص خودشان را دارند، چرا همان شماره نسخه را بهعنوان ETag استفاده نکنیم، بهجای این که از چیز دیگری تولیدش کنیم.
در هر صورت، ETagها فوقالعادهاند و تطبیقشان آسان است. اگر کلاینتها از آنها استفاده نکنند، هیچ اثری ندارد، اما اگر از یک HTTP client با middleware کش فعال استفاده کنند، هم کلاینت و هم سرور میتوانند مقدار زیادی زمان و منابع ذخیره کنند.
کشهای عمومی، خصوصی و اشتراکی
با استفاده از هدرهای Cache-Control میتوان مشخص کرد آیا پاسخ میتواند توسط همه کش شود، فقط توسط کلاینت، یا فقط توسط کشهای اشتراکی. این موضوع از نظر امنیت و حریم خصوصی، و همچنین از نظر کارایی کش مهم است.
- public — پاسخ میتواند توسط همه، از جمله CDNها کش شود.
- private — پاسخ فقط میتواند توسط کلاینت کش شود.
- no-store — پاسخ اصلاً نباید کش شود.
وقتی یک پاسخ شامل هدر Authorization باشد، بهطور خودکار بهعنوان private علامتگذاری میشود تا از کش شدن دادههای حساس در کشهای اشتراکی جلوگیری شود. این یکی دیگر از دلایل استفاده از هدرهای استاندارد احراز هویت است، بهجای استفاده از هدرهای سفارشی مثل X-API-Key.
کدام منابع باید کش شوند؟
بعضیها فکر میکنند هیچ دادهای در API آنها قابل کش نیست چون «ممکن است چیزها تغییر کنند.» بهندرت پیش میآید که همه دادهها آنقدر سریع تغییر کنند که کش HTTP هیچ کمکی نکند. همه دادهها ذاتاً قبل از این که سرور ارسالشان را تمام کند هم کمی قدیمی شدهاند، اما سؤال این است که چه مقدار قدیمی بودن قابل قبول است؟
برای مثال، یک پروفایل کاربری احتمالاً خیلی زیاد تغییر نمیکند، و واقعاً چقدر لازم است بهروز باشد؟ فقط چون یک کاربر ممکن است سالی یک بار بیوگرافیاش را عوض کند، به این معنا نیست که همه پروفایلهای کاربران باید در هر درخواست بهصورت تازه از سرور گرفته شوند. میتوان آنها را چند ساعت، یا حتی روزانه کش کرد.
وقتی درباره سیستمهای نزدیک به زمان واقعی صحبت میکنیم، یک مثال رایج پلتفرم معاملات سهام است. در واقعیت، بیشتر پلتفرمهای معاملاتی هر ۱۵ دقیقه یک قیمت عمومی جدید منتشر میکنند. یک درخواست به /quotes/ICLN ممکن است هدری مثل Cache-Control: max-age=900 برگرداند که نشان میدهد داده به مدت ۹۰۰ ثانیه معتبر است. حتی وقتی کلاینتها هر ۳۰ ثانیه «polling» میکنند، کش شبکه همچنان میتواند پاسخ را به مدت ۱۵ دقیقه سرو کند، و سرور فقط لازم است به ۱ درخواست از هر ۳۰ درخواست پاسخ بدهد.
برخی منابع ممکن است واقعاً هر ثانیه تغییر کنند، و بسته به الگوی ترافیک، کش شبکه همچنان میتواند مفید باشد. اگر ۱۰۰۰ کاربر همزمان به آن دسترسی داشته باشند، کش شبکه بار را بهطور چشمگیری کم میکند. بهجای پاسخ دادن به ۱۰۰۰ درخواست جداگانه در هر ثانیه، سیستم میتواند از یک پاسخ واحد در هر ثانیه استفاده مجدد کند. این یعنی ۹۹.۹٪ کاهش در بار سرور و ۹۹.۹٪ کاهش در مصرف پهنای باند.
یک پیشفرض امن برای اکثر دادهها این است که مقداری کش مبتنی بر max-age اعمال شود (مثلاً ۵ دقیقه، یک ساعت، یک روز، یا یک هفته، قبل از این که نیاز به تازهسازی داشته باشد) و در کنار آن یک ETag قرار گیرد تا بعد از آن زمان، اگر پاسخ بزرگ است یا تولیدش کند است، بهجای دانلود کامل پاسخ، فقط بررسی تازه بودن انجام شود. اضافه کردن ETagها به API میتواند اعتماد به استفاده از زمانهای انقضای طولانیتر را افزایش دهد.
طراحی منابع قابل کش
همه APIهای جدید باید با در نظر گرفتن قابلیت کش شدن طراحی شوند، یعنی به این فکر کنیم منابع را چطور ساختاربندی کنیم تا کشپذیرتر شوند. تغییراتی که برای کشپذیرتر کردن API لازم است، اغلب همان تغییراتی هستند که API را کارآمدتر و کار با آن را سادهتر میکنند.
ترکیب منابع
یکی از بزرگترین مشکلاتی که طراحان API با آن مواجهاند این است که دادهها را چطور به شکل منطقی در منابع گروهبندی کنند. وسوسهای وجود دارد که تعداد منابع کمتر باشد تا endpoint کمتر باشد و چیزهای کمتری برای مستندسازی وجود داشته باشد. اما این کار باعث منابع بزرگتر میشود که کار کردن با آنها بهشدت ناکارآمد است (بهخصوص وقتی بخشی از دادهها بیشتر از بخشهای دیگر تغییر میکنند).
GET /invoices/645E79D9E14{
"id": "645E79D9E14",
"invoiceNumber": "INV-2024-001",
"customer": "Acme Corporation",
"amountDue": 500.00,
"amountPaid": 250.00,
"dateDue": "2024-08-15",
"dateIssued": "2024-08-01",
"datePaid": "2024-08-10",
"items": [
{
"description": "Consulting Services",
"quantity": 10,
"unitPrice": 50.00,
"total": 500.00
}
],
"customer": {
"name": "Acme Corporation",
"address": "123 Main St",
"city": "Springfield",
"state": "IL",
"zip": "62701",
"email": "acme@example.org",
"phone": "555-123-4567"
},
"payments": [
{
"date": "2024-08-10",
"amount": 250.00,
"method": "Credit Card",
"reference": "CC-1234"
}
]
}این یک الگوی بسیار رایج است، اما خیلی کشپذیر نیست. اگر invoice بهروزرسانی شود، کل invoice بهروزرسانی میشود و کل invoice باید تازهسازی شود. اگر customer بهروزرسانی شود، کل invoice بهروزرسانی میشود و کل invoice باید تازهسازی شود. اگر payments بهروزرسانی شود، کل invoice بهروزرسانی میشود و کل invoice باید تازهسازی شود.
میتوانیم قابلیت کش شدن بخش زیادی از این اطلاعات را با شکستن آن به منابع کوچکتر افزایش دهیم:
GET /invoices/645E79D9E14{
"id": "645E79D9E14",
"invoiceNumber": "INV-2024-001",
"customer": "Acme Corporation",
"amountDue": 500.00,
"dateDue": "2024-08-15",
"dateIssued": "2024-08-01",
"items": [
{
"description": "Consulting Services",
"quantity": 10,
"unitPrice": 50.00,
"total": 500.00
}
],
"links": {
"self": "/invoices/645E79D9E14",
"customer": "/customers/acme-corporation",
"payments": "/invoices/645E79D9E14/payments"
}
}بهجای این که اطلاعات پرداخت را با invoice قاطی کند، این مثال فیلدهای مرتبط با پرداخت را به زیر-کالکشن payments منتقل میکند. این کار نهتنها invoice را بهصورت چشمگیری کشپذیرتر میکند، بلکه جا را برای قابلیتهایی باز میکند که اغلب در سیستمهای فاکتور استفاده میشوند، مثل تلاشهای پرداخت (ردیابی پرداختهای ناموفق) یا پرداختهای جزئی. همه اینها میتواند در زیر-کالکشن Payments انجام شود، و هرکدام از این کالکشنها هم میتوانند جداگانه کش شوند.
داده customer هم از منبع invoice خارج شده است، چون منبع /customers/acme-corporation از قبل وجود دارد و استفاده مجدد از آن جلوی تکرار کد و بار نگهداری را میگیرد. با توجه به جریان کار کاربر در اپلیکیشن، احتمالاً این منبع از قبل در کش مرورگر/کلاینت وجود دارد که زمان لود invoice را کاهش میدهد.
این ساختار API مستقل از این است که ساختار داده در بکاند چه شکلی دارد. شاید همه دادههای پرداخت داخل جدول invoices در یک دیتابیس SQL باشند، اما همچنان endpointهای /invoices و /invoices/{id}/payments وجود داشته باشند. با گذشت زمان و درخواست قابلیتهای اضافی رایج مثل پرداخت جزئی، این endpointها میتوانند ثابت بمانند، اما ساختار دیتابیس میتواند مهاجرت کند تا فیلدهای مخصوص پرداخت به یک جدول payments منتقل شوند.
بسیاری معتقدند این تفکیک بهتری از مسئولیتهاست، کنترل مجوزها برای این که چه کسی مجاز است invoice و/یا payments را ببیند آسانتر میشود، و قابلیت کش شدن API با جدا کردن اطلاعاتی که زیاد تغییر میکند از اطلاعاتی که کم تغییر میکند بهشدت بهبود یافته است.
از ترکیب داده عمومی و خصوصی خودداری کنید
شکستن منابع به بخشهای کوچکتر و قابل مدیریتتر میتواند اطلاعات پرتغییر را از دادههای پایدارتر جدا کند، اما مسائل طراحی دیگری هم وجود دارد که میتواند روی قابلیت کش شدن اثر بگذارد: ترکیب داده عمومی و خصوصی.
مثال یک API رزرو سفر با قطار را در نظر بگیرید. ممکن است یک منبع Booking وجود داشته باشد که مخصوص یک کاربر است و دادههای خصوصی دارد که هیچکس دیگری نباید ببیند.
GET /bookings/1234{
"id": 1234,
"departure": "2025-08-15T08:00:00",
"arrival": "2025-08-15T12:00:00",
"provider": "ACME Express",
"seat": "A12"
}برای این که کاربر بتواند صندلیاش را انتخاب کند، ممکن است یک زیرمنبع برای seating وجود داشته باشد:
GET /bookings/:my_booking_ref/seating{
"my_seat": "A12",
"available_seats": [
"A1", "A2", "A3", "A4", "A5", "A6", ...
]
}ساختن زیرمنبع seating به این شکل باعث میشود برای تکتک کاربران یک نقشه صندلی یکتا ایجاد شود، چون «همه صندلیها» و «صندلی این کاربر» با هم قاطی شدهاند.
این پاسخها همچنان میتوانند کش شوند، اما مجبورند private باشند چون اطلاعات عمومی با داده یکتای هر کاربر «آلوده» شده است. ۱۰,۰۰۰ کاربر یعنی ۱۰,۰۰۰ ورودی کش، و احتمال/اثر استفاده مجدد از آنها خیلی کم خواهد بود، بنابراین فایده زیادی ندارد که کل کش با اینها پر شود.
در نظر بگیرید این را به دو منبع جدا بشکنید:
GET /bookings/:my_booking_ref - مشاهده جزئیات رزرو، شامل صندلی فعلی.
GET /trips/:trip_id/seats - فهرست در دسترس بودن صندلیها در قطار.
PUT /bookings/:my_booking_ref - بهروزرسانی رزرو (مثلاً برای رزرو یک صندلی).
با منتقل کردن اطلاعات صندلی به منبع booking، در دسترس بودن صندلیها به دادهای عمومی و غیرشخصی تبدیل میشود. چون هیچ چیز شخصی در آن وجود ندارد، میتوان آن را برای همه کسانی که در حال رزرو صندلی در این قطار هستند کش کرد.
کش کردن این داده هیچ ضرری ندارد، چون برای همه یکسان است. حتی اگر تغییر کند، بهسادگی میتوان جدیدترین داده را از سرور گرفت و اگر دیگر صندلی موجود نبود، به کاربر پیشنهاد داد صندلی دیگری انتخاب کند. این کار اجازه میدهد داده در دسترس بودن صندلیها برای مدت طولانی کش شود و فقط زمانی نگران تازهسازی باشید که درخواست PUT شکست بخورد چون صندلی دیگر موجود نیست.
شبکههای توزیع محتوا (CDNها)
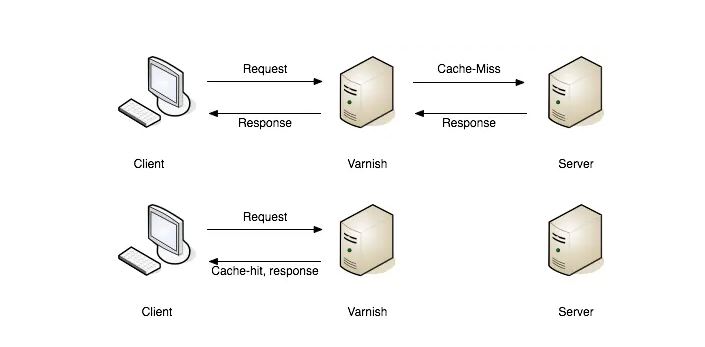
کش HTTP وقتی کلاینتها از آن استفاده کنند خوب کار میکند، و بسیاری از کلاینتها بهصورت خودکار این کار را انجام میدهند، مثل مرورگرهای وب یا سیستمهایی که middleware کش دارند. اما وقتی با ابزارهایی مثل Fastly یا Varnish ترکیب شود حتی قدرتمندتر میشود.
این ابزارها بین سرور و کلاینت قرار میگیرند و مثل نگهبانهای هوشمند عمل میکنند:
کش سمت کلاینت قطعاً مفید است، اما قدرت واقعی کش زمانی نمایان میشود که ترافیک وب API از طریق یک پراکسی کش عبور داده شود. با استفاده از راهکارهای میزبانیشده مثل Fastly یا AWS CloudFront، این میتواند فقط با تغییر تنظیمات DNS انجام شود. برای گزینههای self-hosted مثل Varnish، بهجای این که DNS را به یک سرویس میزبانیشده اشاره دهید، کسی باید یک سرور راهاندازی کند تا نقش پراکسی کش را بازی کند.
بسیاری از ابزارهای API gateway مثل Tyk و Zuplo کش داخلی دارند، بنابراین ممکن است این قابلیت از قبل در اکوسیستم موجود باشد و فقط نیاز به فعالسازی داشته باشد.
با کش HTTP انتشار (و پول) را کاهش دهید
اینترنت (و زیرساخت آن) مسئول ۴٪ از انتشار جهانی CO2 است، و با این که ۸۳٪ از ترافیک وب از طریق APIها میآید، در نظر گرفتن اثر کربنی APIهای جدید حیاتی میشود.
هر درخواست غیرضروری API هزینه منابع سرور، پهنای باند و انرژی دارد. آن انرژی یک ردپای کربنی به همراه دارد، چه دیتاسنتر با انرژی تجدیدپذیر کار کند و چه نه.
جمعبندی
با کاهش درخواستهای تکراری، کش HTTP میتواند:
- بار سرور را کاهش دهد (کاهش هزینههای میزبانی).
- ترافیک شبکه را کم کند (کاهش هزینههای پهنای باند).
- مصرف انرژی را به حداقل برساند (به نفع محیط زیست).
تصور کنید میلیونها کاربر دیگر برای دادهای که تغییر نکرده درخواست غیرضروری ارسال نکنند. طراحی APIها به شکلی که از ابتدا کشپسند باشند نهتنها به محیط زیست کمک میکند، بلکه به APIهای سریعتر، کارآمدتر و کاربرپسندتر هم منجر میشود. این یک برد-برد است: عملکرد بهتر برای کاربران، هزینه عملیاتی کمتر برای ارائهدهندگان، و اثر مثبت برای سیاره.
اشتراک این مقاله
پستهای مرتبط

موارد استفاده API بینش هویتی (Identity Insights) برای پیشگیری از تقلب چیست؟
Erlang چیست؟
دیدگاهها (0)
برای ثبت دیدگاه لطفاً وارد شوید.
ورودهنوز دیدگاهی ثبت نشده است. اولین نفر باشید!