
دو ابزار حیاتی مدیریت داده، پایگاههای داده و انبارهای داده هستند. در حالی که هر دو برای ذخیره و مدیریت دادهها طراحی شدهاند، در رویکرد و عملکردشان متفاوت هستند.
در این مقاله، تفاوتهای بین پایگاه داده و انبار داده را بهطور دقیق بررسی میکنیم. همچنین مزایای رویکرد ترکیبی و ملاحظات برای انتخاب راهحل مناسب را بحث خواهیم کرد.
پایگاه داده چیست؟
پایگاه داده مجموعهای ساختاریافته از دادههاست که به شیوهای خاص سازماندهی شده تا دسترسی، بازیابی و پردازش آسان را تسهیل کند. این پایگاه دادههای جاری مورد استفاده توسط یک برنامه را ذخیره میکند.
پایگاههای داده، دادههای تراکنشی تولیدشده در زمان واقعی توسط عملیات روزانه سازمان را ذخیره و پردازش میکنند. این بهعنوان OLTP (پردازش تراکنش آنلاین) شناخته میشود.
انواع مختلف سیستمهای پایگاه داده برای موارد استفاده متنوعی خدمت میکنند. رایجترین نوع، پایگاه داده رابطهای (RDBMS) است. آنها دادهها را در جداول ذخیره میکنند، جایی که یک ردیف یک رکورد واحد را نشان میدهد و یک ستون یک فیلد یا ویژگی آن رکورد را نشان میدهد. انواع دیگر پایگاههای داده شامل پایگاههای داده NoSQL، پایگاههای داده توزیعشده و پایگاههای داده NewSQL هستند.
ویژگیهای کلیدی پایگاههای داده
- ویژگیهای ACID: پایگاههای داده به ویژگیهای ACID (اتمی بودن، سازگاری، ایزولاسیون، دوام) پایبند هستند و اطمینان میدهند که هر تراکنش بهطور قابلاعتماد و سازگار پردازش میشود.
- تمرکز بر OLTP: برای بارهای کاری OLTP طراحی شدهاند تا دادههای تراکنشی را ذخیره، بازیابی و پرسوجو کنند.
- سازماندهی مبتنی بر شماتیک: اکثر پایگاههای داده از طراحی شماتیک نرمالشده برای کاهش افزونگی و اطمینان از سازگاری استفاده میکنند.
- SQL بهعنوان زبان پرسوجو: SQL زبان پرسوجوی استاندارد است.
- قابلیتهای پردازش بلادرنگ: پایگاههای داده مدرن از دریافت داده جریانی و تحلیل بلادرنگ از طریق پردازش حافظهای و نمایهسازی ستونی پشتیبانی میکنند.
- مقیاسپذیری بومی ابری: سیستمهای پایگاه داده معاصر مقیاسپذیری الاستیک را از طریق کپیهای خوانشی، مقیاسپذیری خودکار و پیکربندیهای بدون سرور ارائه میدهند.
مزایا و معایب پایگاههای داده
مزایا
- پردازش داده بلادرنگ برای سازگاری فوری
- انطباق با ACID یکپارچگی داده را تضمین میکند
- کارآمد برای عملیات خواندن/نوشتن با حجم بالا و مقیاس کوچک
- بهینهشده برای پرسوجوهای نقطهای و اسکنهای محدوده روی ستونهای نمایهشده
- پایگاههای داده مدرن از بارهای کاری تحلیلی از طریق معماریهای ترکیبی پشتیبانی میکنند
- استقرارهای بومی ابری مقیاسپذیری و مدیریت مقرونبهصرفه را ارائه میدهند
معایب
- مقیاسپذیری محدود برای مجموعههای داده بسیار بزرگ
- برای پرسوجوهای تحلیلی پیچیده بهینه نشدهاند
- مقیاسپذیری عمودی میتواند پرهزینه باشد و محدودیتهای فیزیکی دارد
- تغییرات شماتیک میتوانند دشوار باشند و ممکن است نیاز به توقف داشته باشند
- عملکرد با افزایش بارهای کاری تحلیلی همزمان کاهش مییابد
- هزینههای ذخیرهسازی به دلیل نرمالسازی و سربار نمایه بالا میتواند زیاد باشد
پایگاههای داده محبوب
- MySQL: RDBMS رایگان و منبعباز که از تراکنشهای ACID، کلیدهای خارجی و رویههای ذخیرهشده پشتیبانی میکند.
- PostgreSQL: RDBMS منبعباز شناختهشده برای سفارشیسازی و قابلیت گسترش.
- Oracle Database: RDBMS با عملکرد بالا که معمولاً برای سیستمهای تراکنشی استفاده میشود.
- Microsoft SQL Server: RDBMS مورد استفاده برای پردازش تراکنش، BI و تحلیلها.
- TiDB: پایگاه داده SQL توزیعشده مدرن که از هر دو بار کاری OLTP و OLAP از طریق معماری HTAP پشتیبانی میکند.
انبار داده چیست؟
انبار داده یک مخزن داده متمرکز بزرگ است که از فعالیتهای هوش تجاری (BI) مانند گزارشگیری، تحلیل و تصمیمگیری پشتیبانی میکند. این انبار مقادیر عظیمی از دادههای جاری و تاریخی را از برنامهها و منابع مختلف ذخیره میکند.
انبار داده پردازش تحلیلی آنلاین (OLAP) را تسهیل میکند. برای پرسوجو و تحلیل پیچیده مجموعههای داده بزرگ بهینه شده است تا روندهایی را شناسایی کند که تصمیمگیری استراتژیک را آگاه میسازد.
دادهها از منابع مختلف استخراج، تبدیل و از طریق خطوط لوله داده به انبار بارگذاری میشوند. انبارهای داده مدرن بهطور فزایندهای از دریافت داده بلادرنگ از طریق خطوط لوله ETL جریانی و فناوریهای ضبط تغییرات داده (CDC) پشتیبانی میکنند.
ویژگیهای کلیدی انبارهای داده
- تمرکز بر OLAP: از بارهای کاری OLAP پشتیبانی میکند و زمان پاسخ پرسوجو سریع را ارائه میدهد.
- بهینهشده برای ذخیرهسازی و بازیابی در مقیاس بزرگ: از شماتیک ستارهای در مقابل شماتیک برفدانهای برای سازماندهی دادهها برای پرسوجوی کارآمد استفاده میکند.
- ادغام داده از منابع متعدد: مقصد مرکزی که دادهها در آن استخراج، تبدیل و بارگذاری میشوند.
- پشتیبانی از پرسوجوهای پیچیده و تجمیعها: تحلیل عمیق مجموعههای داده در مقیاس بزرگ را امکانپذیر میکند.
- بهینهسازی ذخیرهسازی ستونی: انبارهای مدرن از فرمتهای ذخیرهسازی ستونی استفاده میکنند که فشردهسازی شدید و اسکنهای تحلیلی سریع را امکانپذیر میکنند.
- معماریهای بومی ابری: جداسازی محاسبات و ذخیرهسازی امکان مقیاسپذیری مستقل و بهینهسازی هزینه را فراهم میکند.
- ادغام هوش مصنوعی و یادگیری ماشین: ادغام بومی با چارچوبهای ML مدلسازی پیشبینیکننده و تحلیلهای خودکار را امکانپذیر میکند.
مزایا و معایب انبارهای داده
مزایا
- بهینهشده برای پرسوجوهای تحلیلی پیچیده روی مجموعههای داده بزرگ
- ذخیرهسازی کارآمد دادههای تاریخی
- مقیاسپذیر برای مدیریت پتابایتها از طریق معماریهای توزیعشده
- تجمیعهای سریع و تحلیل چندبعدی
- پردازش پرسوجو موازی با توان بالا
- مقرونبهصرفه برای تحلیلهای در مقیاس بزرگ
- انبارهای مدرن از تحلیلهای بلادرنگ و دادههای جریانی پشتیبانی میکنند
- قابلیتهای یادگیری ماشین داخلی برای بینشهای پیشبینیکننده
معایب
- مناسب برای پردازش تراکنشی با حجم بالا نیست
- راهاندازی اولیه و مدلسازی داده میتواند پیچیده باشد
- پتانسیل برای ایجاد سیلوهای داده در صورت عدم ادغام مناسب
- ممکن است نیاز به مهارتهای مدیریتی تخصصی داشته باشد
- انبارهای سنتی قابلیتهای بلادرنگ محدودی دارند
انبارهای داده محبوب
- Amazon Redshift: انبار داده ابری برای بارهای کاری در مقیاس پتابایت.
- Google BigQuery: انبار کاملاً مدیریتشده Google Cloud Platform برای تحلیلهای سریع.
- Snowflake: پلتفرم داده ابری برای دادههای ساختاریافته و نیمهساختاریافته.
- Microsoft Azure Synapse Analytics: انبار مقیاسپذیر یکپارچه با اکوسیستم Azure.
- Databricks: پلتفرم تحلیل یکپارچه که انبار داده را با قابلیتهای یادگیری ماشین ترکیب میکند.
معماریهای پایگاه داده و انبار داده چگونه مقایسه میشوند؟
تفاوت اصلی بین انبار داده و پایگاه داده این است که انبار داده برای پرسوجوهای تحلیلی بهینه شده و دادههای تاریخی را برای گزارشگیری ذخیره میکند، در حالی که پایگاه داده برای پردازش تراکنشی طراحی شده و دادههای عملیاتی بلادرنگ را مدیریت میکند.
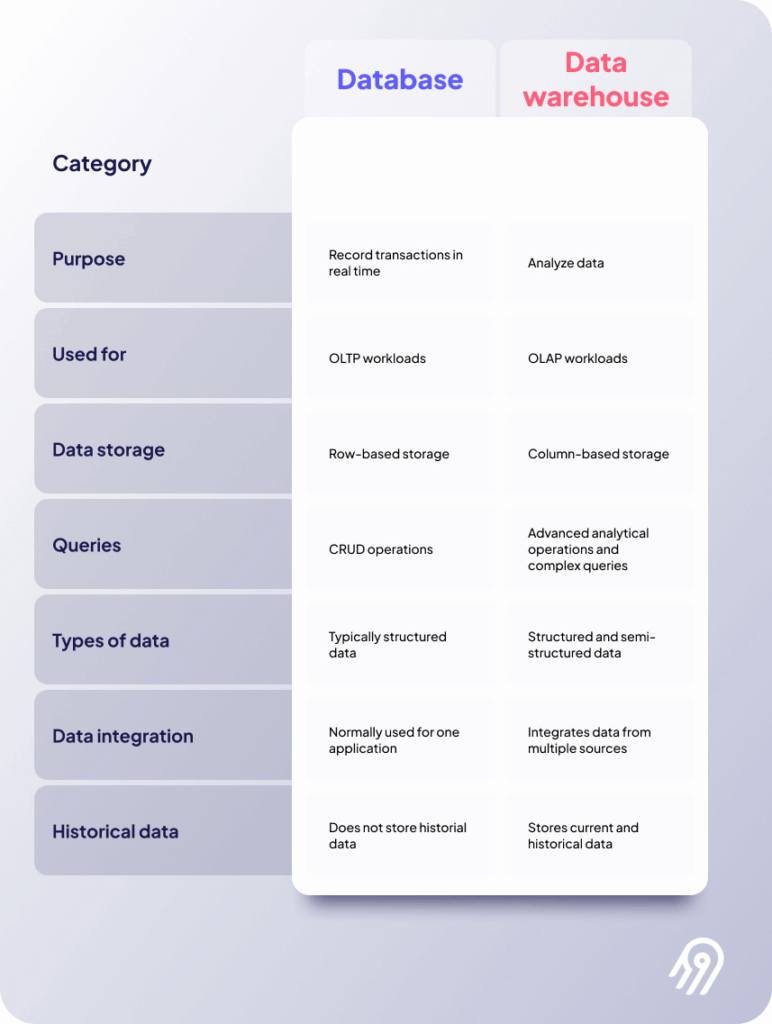
هدف و بارهای کاری
پایگاههای داده عمدتاً برای بارهای کاری پردازش تراکنش آنلاین (OLTP) طراحی شدهاند. آنها در مدیریت عملیات تراکنشی با حجم بالا و بلادرنگ مانند موارد زیر برتری دارند:
- پردازش سفارش مشتری
- مدیریت موجودی
- تراکنشهای مالی
- احراز هویت کاربر و مدیریت جلسه
- بهروزرسانیها و تغییرات داده بلادرنگ
انبارهای داده برای بارهای کاری پردازش تحلیلی آنلاین (OLAP) بهینه شدهاند. آنها در موارد زیر تخصص دارند:
- پرسوجوهای تحلیلی پیچیده در مجموعههای داده بزرگ
- تحلیل دادههای تاریخی و شناسایی روند
- هوش تجاری و گزارشگیری
- تحلیل چندبعدی و دادهکاوی
- پشتیبانی از تصمیمگیری استراتژیک از طریق بینشهای تجمیعی
ذخیرهسازی و سازماندهی داده
پایگاههای داده معمولاً از شماتیکهای نرمالشده استفاده میکنند که برای کاهش افزونگی داده و اطمینان از سازگاری طراحی شدهاند. این رویکرد:
- نیازهای ذخیرهسازی را از طریق حذف دادههای تکراری کاهش میدهد
- یکپارچگی داده را از طریق محدودیتهای ارجاعی حفظ میکند
- برای عملیات درج، بهروزرسانی و حذف مکرر بهینهسازی میکند
- از ذخیرهسازی مبتنی بر ردیف برای الگوهای دسترسی تراکنشی استفاده میکند
انبارهای داده از شماتیکهای غیرنرمالشده مانند شماتیکهای ستارهای یا برفدانهای استفاده میکنند که:
- عملکرد پرسوجو را از طریق ساختارهای داده پیشپیوسته بهینه میکنند
- تجمیعهای سریع و تحلیل چندبعدی را امکانپذیر میکنند
- ذخیرهسازی دادههای تاریخی با ابعاد بهآرامی در حال تغییر را پشتیبانی میکنند
- از فرمتهای ذخیرهسازی ستونی برای تسریع پرسوجوهای تحلیلی استفاده میکنند
عملکرد و مقیاسپذیری
پایگاههای داده اولویتبندی میکنند:
- پاسخهای با تأخیر کم برای تراکنشهای فردی (میلیثانیه)
- پشتیبانی از کاربران همزمان بالا برای برنامههای عملیاتی
- عملکرد سازگار تحت شرایط بار متغیر
- مقیاسپذیری عمودی از طریق ارتقاء سختافزار، هرچند سیستمهای مدرن از مقیاسپذیری افقی پشتیبانی میکنند
انبارهای داده بر موارد زیر تمرکز دارند:
- پردازش با توان بالا برای پرسوجوهای تحلیلی در مقیاس بزرگ
- اجرای پرسوجوی موازی در معماریهای توزیعشده
- مقیاسپذیری به مجموعههای داده در مقیاس پتابایت از طریق معماریهای بومی ابری
- تخصیص منابع الاستیک که محاسبات و ذخیرهسازی را بهطور مستقل مقیاس میکند
ادغام و تبدیل داده
پایگاههای داده ادغام داده را از طریق موارد زیر مدیریت میکنند:
- دریافت داده بلادرنگ از برنامهها و منابع خارجی
- تبدیل حداقل برای حفظ یکپارچگی داده عملیاتی
- ادغام مستقیم برنامه از طریق APIها و اتصالدهندهها
- ضبط تغییرات داده (CDC) برای تکثیر بلادرنگ
انبارهای داده ادغام را از طریق موارد زیر مدیریت میکنند:
- فرآیندهای ETL/ELT که دادهها را از منابع متعدد استخراج، تبدیل و بارگذاری میکنند
- پاکسازی و استانداردسازی داده برای اطمینان از کیفیت تحلیلی
- یکپارچگی دادههای تاریخی از سیستمهای عملیاتی مختلف
- مدیریت تکامل شماتیک برای رسیدگی به ساختارهای داده در حال تغییر
قابلیتهای پرسوجو
پایگاههای داده در موارد زیر برتری دارند:
- پرسوجوهای ساده با جستجوی نقطهای و اسکنهای محدوده
- عملیات پیوستن در جداول نرمالشده
- سازگاری تراکنشی از طریق ویژگیهای ACID
- پاسخهای پرسوجوی بلادرنگ برای برنامههای عملیاتی
انبارهای داده در موارد زیر تخصص دارند:
- پرسوجوهای تحلیلی پیچیده با چندین پیوست و تجمیع
- توابع پنجرهای برای تحلیل سریهای زمانی
- تحلیلهای پیشرفته شامل توابع آماری و یادگیری ماشین
- بهینهسازی پرسوجو از طریق نمایهای مادیشده و دادههای پیشتجمیعی
ساختار داده
پایگاههای داده حفظ میکنند:
- ساختارهای داده نرمالشده که افزونگی را حذف میکنند
- یکپارچگی ارجاعی از طریق محدودیتهای کلید خارجی
- دادههای عملیاتی جاری با زمینه تاریخی محدود
- سازگاری تراکنشی در تغییرات داده مرتبط
انبارهای داده سازماندهی میکنند:
- ساختارهای غیرنرمالشده بهینهشده برای پرسوجوهای تحلیلی
- حفظ دادههای تاریخی با ابعاد متغیر زمانی
- دادهها از منابع متعدد به شماتیکهای یکپارچه تلفیقشده
- دادههای تجمیعی و خلاصهشده برای عملکرد سریعتر پرسوجو
حجم داده و مقیاسپذیری
پایگاههای داده مدیریت میکنند:
- مجموعههای داده متوسط تا بزرگ متمرکز بر نیازهای عملیاتی جاری
- تراکنشهای کوچک مکرر به جای عملیات عمده
- چالشهای مقیاسپذیری با مجموعههای داده بسیار بزرگ به دلیل سربار نرمالسازی
- بهینهسازی عملکرد از طریق نمایهسازی و تنظیم پرسوجو
انبارهای داده مدیریت میکنند:
- مجموعههای داده عظیم که سالها اطلاعات تاریخی را در بر میگیرند
- عملیات داده عمده از طریق پردازش دستهای و جریانی
- ذخیرهسازی در مقیاس پتابایت از طریق معماریهای توزیعشده
- مقیاسپذیری خودکار در محیطهای ابری بر اساس تقاضاهای بار کاری
تازگی داده و فرکانس بهروزرسانی
پایگاههای داده ارائه میدهند:
- بهروزرسانیهای داده بلادرنگ با وقوع تراکنشها
- سازگاری فوری برای برنامههای عملیاتی
- تغییرات با فرکانس بالا در طول عملیات کسبوکاری
- حالت داده جاری که آخرین فعالیتهای کسبوکاری را منعکس میکند
انبارهای داده ارائه میدهند:
- بهروزرسانیهای دورهای داده از طریق فرآیندهای ETL برنامهریزیشده
- حفظ دادههای تاریخی با رکوردهای زمانبندیشده
- پردازش دستهای برای ادغام و تبدیل داده
- دادههای نهایتاً سازگار در محیطهای توزیعشده
انبارهای داده مدرن بهطور فزایندهای از بهروزرسانیهای بلادرنگ از طریق معماریهای جریانی و فناوریهای ضبط تغییرات داده پشتیبانی میکنند.
انعطافپذیری شماتیک
پایگاههای داده نیاز دارند:
- شماتیکهای از پیش تعریفشده با اجرای ساختار سختگیرانه
- چالشهای تکامل شماتیک که ممکن است نیاز به توقف داشته باشند
- حفظ یکپارچگی ارجاعی در تغییرات شماتیک
- هماهنگی برنامه برای تغییرات شماتیک
انبارهای داده ارائه میدهند:
- انعطافپذیری شماتیک در خواندن برای دادههای نیمهساختاریافته
- تکامل شماتیک آسانتر برای الزامات تحلیلی
- پشتیبانی از چندین فرمت داده، از جمله JSON و XML
- شماتیکهای تطبیقی که با نیازهای کسبوکاری تکامل مییابند
همزمانی
پایگاههای داده پشتیبانی میکنند:
- کاربران همزمان بالا برای برنامههای عملیاتی
- مکانیزمهای قفلگذاری برای حفظ سازگاری تراکنشی
- حل تعارض بلادرنگ در طول بهروزرسانیهای همزمان
- کنترل همزمانی چندنسخهای برای سازگاری خواندن
انبارهای داده مدیریت میکنند:
- کاربران تحلیلی همزمان که به دادههای تاریخی دسترسی دارند
- بارهای کاری خوانش-سنگین با بهروزرسانیهای عمده گاهبهگاه
- صفبندی پرسوجو و مدیریت منابع برای تحلیلهای پیچیده
- پردازش موازی در منابع محاسباتی توزیعشده
ملاحظات هزینه
پایگاههای داده شامل موارد زیر هستند:
- هزینههای مجوز برای سیستمهای پایگاه داده سازمانی
- هزینههای زیرساختی برای سختافزار با عملکرد بالا
- هزینههای عملیاتی برای نگهداری و مدیریت
- هزینههای مقیاسپذیری که با حجم داده و بار کاربر افزایش مییابد
انبارهای داده شامل موارد زیر هستند:
- مدلهای قیمتگذاری مبتنی بر ابر با گزینههای پرداخت به ازای استفاده
- هزینههای ذخیرهسازی برای حفظ دادههای تاریخی
- هزینههای محاسباتی برای پردازش تحلیلی
- سربار عملیاتی کمتر از طریق خدمات مدیریتشده
الزامات امنیتی و حاکمیتی سازمانی چگونه تصمیمگیریهای پایگاه داده در مقابل انبار داده را شکل میدهند؟
الزامات امنیتی و حاکمیتی سازمانی نقش حیاتی در تعیین تعادل بهینه بین پایگاههای داده و انبارهای داده ایفا میکنند، زیرا هر سیستم چالشهای امنیتی و فرصتهای حاکمیتی متمایزی را ارائه میدهد که باید با چارچوبهای انطباق سازمانی همراستا شوند.
ملاحظات معماری امنیتی
امنیت پایگاه داده حفاظت بلادرنگ را از طریق رمزنگاری و کنترلهای دسترسی که دادههای عملیاتی را در نقطه ایجاد محافظت میکنند، اولویتبندی میکند. سیستمهای تراکنشی نیاز به بررسیهای سازگاری فوری و پردازش تراکنش اتمی دارند و مکانیزمهای قفلگذاری سطح ردیف دانهریز و نظارت مداوم را برای جلوگیری از نقضهای امنیتی در طول عملیات با سرعت بالا میطلبند. پایگاههای داده مدرن رمزنگاری سطح فیلد را برای رکوردهای فعال و سیستمهای احراز هویت قوی که با پلتفرمهای مدیریت هویت سازمانی ادغام میشوند، پیادهسازی میکنند.
انبارهای داده چالشهای امنیتی متفاوتی را به دلیل ماهیت تحلیلی و الزامات ادغام داده چندمنبعی خود ارائه میدهند. این سیستمها نیازمند ردیابی ریشهشناسی داده جامع و اجرای سیاست بینمنبعی برای حفاظت از داراییهای اطلاعاتی تلفیقی هستند. محیطهای انبار در نقاط ادغام که مجموعههای داده ناهمگن ادغام میشوند، با ریسکهای بیشتری مواجه هستند و نیاز به تشخیص ناهنجاری قوی و ممیزی متاداده برای شناسایی خطوط لوله به خطر افتاده دارند. الگوهای پرسوجوی تحلیلی معمول انبارها متاداده گستردهای تولید میکنند که خود به یک دارایی امنیتی تبدیل میشود و تشخیص زودهنگام تهدید را از طریق شناسایی انحراف الگوی دسترسی امکانپذیر میکند.
پیادهسازی چارچوب حاکمیتی
چارچوبهای حاکمیت داده باید ویژگیهای متمایز هر سیستم را در حالی که اجرای سیاست یکپارچه را در سراسر چشمانداز داده سازمانی حفظ میکنند، جای دهند. پیادهسازی کنترل دسترسی مبتنی بر نقش بهطور قابلتوجهی بین سیستمها متفاوت است: پایگاههای داده از امتیازات سطح شماتیک دقیق همراستا با نقشهای تراکنشی استفاده میکنند، در حالی که انبارها دسترسی همراستا با حوزه کسبوکاری را از طریق کنترلهای مبتنی بر ویژگی که عوامل متعددی از جمله بخش کاربر، حساسیت پرسوجو و تازگی مجموعه داده را ارزیابی میکنند، پیادهسازی میکنند.
چالش حاکمیتی در محیطهای انبار به دلیل ادغام چندمنبعی تشدید میشود و نیاز به مدیریت متاداده پیشرفته و نقشهای نظارتی تخصصی دارد. حاکمیت انبار نیازمند برقراری قراردادهای داده بین تولیدکنندگان و مصرفکنندگان است که شماتیکهای مورد انتظار، معیارهای کیفیت و سطوح خدمات را در سیستمهای عملیاتی متعددی که به محیطهای تحلیلی تغذیه میکنند، تعریف میکند.
استراتژیهای ادغام انطباق
الزامات انطباق نظارتی اساساً انتخاب پایگاه داده در مقابل انبار داده را بر اساس دستورات خاص صنعت و الزامات حوزه قضایی شکل میدهند. انطباق با GDPR رویکردهای متفاوتی را میطلبد: پایگاههای داده محدودیتهای دسترسی مبتنی بر هدف را در ایجاد رکورد از طریق جاسازی متاداده رضایت پیادهسازی میکنند، در حالی که انبارها جریانهای کاری حذف داده خودکار را برای حذف ویژگیهای غیرضروری پس از تبدیلهای تحلیلی برقرار میکنند.
استانداردهای مالی مانند SOX کنترلهای سطح تراکنش را میطلبند که پایگاههای داده جریانهای کاری تأیید دوگانه را برای ورودیهای مادی پیادهسازی میکنند، که توسط انبارهای حاوی مخازن ژورنال تفکیکشده با ویژگیهای فقط-نوشتار که از اصلاح گذشتهنگر جلوگیری میکنند، تکمیل میشود. انطباق مراقبتهای بهداشتی تحت HIPAA پیادهسازیهای تخصصی را میطلبد که پایگاههای داده لاگگیری دسترسی اطلاعات سلامت محافظتشده سختگیرانه با پرسوجوهای زمینهای کاربر را اعمال میکنند، در حالی که انبارها پلهای ناشناسسازی را پیادهسازی میکنند که تحلیل تحقیقاتی را بدون ناشناسسازی کامل امکانپذیر میکنند.
استراتژیهای امنیتی یکپارچه
سازمانها بهطور فزایندهای استراتژیهای امنیتی یکپارچهای را اتخاذ میکنند که از نقاط قوت مکمل هر دو سیستم بهره میبرند در حالی که آسیبپذیریهای فردی آنها را برطرف میکنند. سیستمهای دسترسی پایگاه داده احراز هویت را به محیطهای انبار فدرال میکنند، در حالی که شماتیکهای طبقهبندی داده از سیستمهای تراکنشی به مدلهای تحلیلی انتشار مییابند. پیادهسازیهای پیشرفته دارای همگامسازی کنترل دوطرفه هستند که تحلیل حساسیت انبار نیازمندیهای ماسکینگ پایگاه داده را آگاه میکند، در حالی که الگوهای دسترسی پایگاه داده مدلهای امنیتی سطح ردیف انبار را شکل میدهند.
همگرایی کنترلهای امنیتی فرصتهایی برای تشخیص تهدید پیشرفته از طریق همبستگی رویدادهای پایگاه داده عملیاتی با الگوهای دسترسی انبار تحلیلی ایجاد میکند. این رویکرد یکپارچه شناسایی حملات پیچیدهای که ممکن است هر دو محیط تراکنشی و تحلیلی را در بر گیرند، امکانپذیر میکند و پوشش امنیتی جامعی را در سراسر چرخه حیات کامل داده فراهم میکند.
روشهای ادغام داده مدرن چه نقشی در اتصال محیطهای پایگاه داده و انبار داده ایفا میکنند؟
روشهای ادغام داده مدرن فراتر از رویکردهای پردازش دستهای سنتی تکامل یافتهاند تا چارچوبهای پیچیدهای را ارائه دهند که محیطهای پایگاه داده و انبار داده را بهطور یکپارچه متصل میکنند در حالی که چالشهای معاصر پیرامون تحلیلهای بلادرنگ، کیفیت داده و حاکمیت را برطرف میکنند.
ادغام بلادرنگ از طریق ضبط تغییرات داده
ضبط تغییرات داده نشاندهنده تغییر اساسی از ادغام مبتنی بر دسته به همگامسازی مداوم بین پایگاههای داده تراکنشی و انبارهای تحلیلی است. پیادهسازیهای CDC مدرن عملیات درج، بهروزرسانی و حذف را در سطح لاگ تراکنش پایگاه داده ضبط میکنند و این تغییرات را از طریق صفهای پیام با تأخیر حداقل به انبارهای هدف جریان میدهند. این رویکرد تحلیلهای عملیاتی نیازمند دادههای نزدیک به بلادرنگ را امکانپذیر میکند در حالی که تأثیر عملکرد بر سیستمهای پایگاه داده منبع را به حداقل میرساند.
پارادایمهای ELT پیشرفته و تبدیل داده
تکامل از ETL سنتی به روشهای ELT نحوه رویکرد سازمانها به ادغام پایگاه داده و انبار را اساساً تغییر داده است. پارادایمهای ELT از قدرت محاسباتی انبارهای داده ابری مدرن برای انجام تبدیلها پس از بارگذاری دادههای خام بهره میبرند، مجموعههای داده کامل را برای تحلیل اکتشافی حفظ میکنند در حالی که تبدیلهای درخواستی را برای موارد استفاده تحلیلی خاص امکانپذیر میکنند.
چارچوبهای ادغام مبتنی بر متاداده
چارچوبهای ادغام مبتنی بر متاداده تولید خط لوله را از طریق مخازن متاداده اعلامی که روابط ساختاری و قوانین تبدیل را بین محیطهای پایگاه داده و انبار تعریف میکنند، خودکار میکنند. این چارچوبها مدلهای داده مشترک را برقرار میکنند، سازگاری معنایی را تضمین میکنند در حالی که کاربران کسبوکاری را قادر میسازند جریانهای ادغام را بدون تخصص برنامهنویسی فنی پیکربندی کنند.
استراتژیهای مجازیسازی و فدراسیون داده
مجازیسازی داده لایههای انتزاعی ایجاد میکند که منابع پایگاه داده و انبار توزیعشده را بهعنوان موجودیتهای یکپارچه بدون نیاز به تلفیق فیزیکی داده ارائه میدهد. این رویکرد دسترسی بلادرنگ به دادههای عملیاتی جاری را در حالی که از پرسوجوهای تحلیلی پیچیده که چندین سیستم را در بر میگیرند پشتیبانی میکند، شکاف سنتی بین محیطهای تراکنشی و تحلیلی را پر میکند.
الگوهای ادغام معماری ترکیبی
روشهای ادغام مدرن بهطور فزایندهای از معماریهای ترکیبی پشتیبانی میکنند که قابلیتهای تخصصی پایگاههای داده و انبارهای داده را در خطوط لوله پردازش داده یکپارچه بهره میبرند. این الگوها معمولاً ضبط داده جریانی از پایگاههای داده عملیاتی را با پردازش تحلیلی دستهای در انبارها ترکیب میکنند و جریانهای داده انتها به انتها را ایجاد میکنند که هر دو الزامات عملیاتی بلادرنگ و موارد استفاده تحلیلی پیچیده را پشتیبانی میکنند.
هوش مصنوعی و خودکارسازی چگونه بر انتخاب پایگاه داده در مقابل انبار داده تأثیر میگذارند؟
هوش مصنوعی و خودکارسازی اساساً نحوه رویکرد سازمانها به انتخاب پایگاه داده در مقابل انبار داده را با معرفی قابلیتهایی که قبلاً غیرممکن بودند یا نیاز به مداخله دستی قابلتوجه داشتند، تحول میبخشند.
بهینهسازی پرسوجو و مدیریت عملکرد مبتنی بر هوش مصنوعی
الگوریتمهای یادگیری ماشین برنامههای اجرای پرسوجو، الگوهای توزیع داده و استفاده از منابع را تحلیل میکنند تا عملکرد را بدون مداخله انسانی بهطور خودکار بهینه کنند.
مدیریت داده و حاکمیت خودکار
خودکارسازی هوش مصنوعی وظایف مدیریت دادهای که بهطور سنتی نیاز به تلاش دستی قابلتوجه و تخصص تخصصی داشتند را تحول میبخشد، دادههای حساس را بهطور خودکار طبقهبندی میکند و انطباق را حفظ میکند.
یادگیری ماشین جاسازیشده و تحلیلهای پیشبینیکننده
ادغام قابلیتهای یادگیری ماشین مستقیماً در سیستمهای پایگاه داده و انبار داده نیاز به پلتفرمهای تحلیلی جداگانه را حذف میکند و تحلیلهای پیشبینیکننده بلادرنگ را امکانپذیر میسازد.
ادغام داده هوشمند و مدیریت خط لوله
پلتفرمهای ادغام داده مبتنی بر هوش مصنوعی بهطور خودکار منابع داده را کشف میکنند، روابط شماتیک را نقشهبرداری میکنند و همگامسازی را در محیطهای پایگاه داده و انبار داده حفظ میکنند.
هوش تصمیمگیری بلادرنگ
همگرایی هوش مصنوعی و پردازش بلادرنگ سیستمهای هوش تصمیمگیری را امکانپذیر میکند که قابلیتهای تراکنشی پایگاههای داده را با قدرت تحلیلی انبارهای داده ترکیب میکنند.
مزایای رویکردهای ترکیبی ترکیب پایگاههای داده و انبارهای داده چیست؟
سیستمهای ترکیبی از نقاط قوت هر دو پایگاه داده و انبار داده برای ایجاد معماریهای داده انعطافپذیر و مقیاسپذیر استفاده میکنند که محدودیتهای رویکردهای تکسیستمی را برطرف میکنند.
- دیتامارت: زیرمجموعهای دپارتمانی از انبار داده که برای کارکردهای کسبوکاری خاص بهینه شده است.
- راهحلهای ابری ترکیبی: ترکیب پایگاههای داده داخلی با انبارهای ابری برای تعادل امنیت، هزینه و الزامات عملکرد.
- مجازیسازی داده: دسترسی به دادهها از منابع متعدد بهگونهای که گویی در یک مکان ذخیره شدهاند، پرسوجوی یکپارچه را بدون جابجایی داده امکانپذیر میکند.
- معماریهای HTAP: پردازش تراکنشی را با قابلیتهای تحلیلی در پلتفرمهای یکپارچه ترکیب میکند.
مزایای استفاده از هر دو
- عملکرد – سیستمهای تخصصی بارهای کاری را که برای آنها بهینه شدهاند، مدیریت میکنند.
- مقیاسپذیری – بارهای کاری تراکنشی و تحلیلی میتوانند بهطور مستقل مقیاس شوند.
- انعطافپذیری – معماریها با نیازهای کسبوکاری در حال تغییر سازگار میشوند.
- بهینهسازی هزینه – منابع بهطور مقرونبهصرفه تخصیص مییابند.
- بهبود کیفیت داده – مدیریت یکپارچه حاکمیت بهتری را امکانپذیر میکند.
- تحلیلهای بلادرنگ – بینشهای فوری روی دادههای عملیاتی.
نمونههای راهحلهای ترکیبی
- Microsoft Azure Cosmos DB
- Google Cloud Spanner
- Amazon Aurora
- Snowflake (از طریق ادغامها)
- Databricks Lakehouse
نتیجهگیری
پایگاههای داده و انبارهای داده اهداف متمایز اما مکمل را در معماری داده مدرن ایفا میکنند، با پایگاههای داده بهینهشده برای تراکنشهای بلادرنگ و انبارهای داده طراحیشده برای پردازش تحلیلی دادههای تاریخی. انتخاب بین آنها به الزامات کسبوکاری خاص بستگی دارد، با بسیاری از سازمانها که رویکردهای ترکیبی را اتخاذ میکنند که نقاط قوت هر دو سیستم را بهره میبرند. با پیشرفت فناوریهای ادغام داده، مرزهای بین این سیستمها همچنان محو میشوند و فرصتهایی برای راهحلهای مدیریت داده انعطافپذیرتر، مقیاسپذیرتر و هوشمندتر ایجاد میکنند.
سوالات متداول
تفاوت اصلی بین پایگاه داده و انبار داده چیست؟
پایگاه داده برای پردازش تراکنشی بلادرنگ (OLTP) مانند پردازش سفارش و مدیریت مشتری طراحی شده است و از شماتیکهای نرمالشده برای دادههای جاری استفاده میکند. انبار داده برای پردازش تحلیلی (OLAP) بهینه شده است و حجمهای بزرگی از دادههای تاریخی را برای گزارشگیری، تحلیل روند و تصمیمگیری استراتژیک ذخیره میکند.
چه زمانی باید پایگاه داده را به جای انبار داده انتخاب کنم؟
از پایگاه داده استفاده کنید زمانی که بارهای کاری شما شامل موارد زیر باشند:
- تراکنشها و بهروزرسانیهای بلادرنگ
- برنامههای عملیاتی (موجودی، CRM، پرداختها)
- عملیات خواندن/نوشتن مکرر
- برنامههایی که نیاز به سازگاری سختگیرانه داده (انطباق با ACID) دارند
چرا ممکن است به انبار داده نیاز داشته باشم؟
انبار داده را انتخاب کنید زمانی که کسبوکار شما نیاز به موارد زیر داشته باشد:
- پرسوجوهای تحلیلی پیچیده روی دادههای تاریخی
- تجمیعها و گزارشگیری در مجموعههای داده بزرگ
- داشبوردهای هوش تجاری
- تحلیلهای پیشبینیکننده و یادگیری ماشین در مقیاس
آیا سیستمهای مدرن هنوز بهطور سختگیرانه بین پایگاههای داده و انبارهای داده جدا شدهاند؟
خیر. معماریهای نوظهور مانند HTAP (پردازش تراکنشی/تحلیلی ترکیبی)، دیتا لیکهوسها و پلتفرمهای بومی ابری بدون سرور این خطوط را محو میکنند. بسیاری از سازمانها اکنون هر دو را ترکیب میکنند و استفاده میکنند:
- پایگاههای داده برای عملیات بلادرنگ
- انبارهای داده برای تحلیلها
- سیستمهای ترکیبی برای بینشهای بلادرنگ و تحلیل تاریخی