
پایگاههای دادهی برداری (Vector Databases) انقلابی در نحوهی مدیریت بارهای کاری هوش مصنوعی ایجاد کردهاند؛ بهطوریکه امروزه شرکتها روزانه بیش از ۲ پتابایت دادهی برداری را پردازش میکنند تا سامانههایی مانند تشخیص تقلب در ۳ میلیثانیه یا موتورهای پیشنهاددهی شخصیسازیشده با رشد ۳ برابری درآمد را پشتیبانی کنند. با این حال، بسیاری از متخصصان داده همچنان با چالش بنیادی مدیریت بردارهای با ابعاد بالا (High-Dimensional Embeddings) در مقیاس وسیع و حفظ تأخیر پرسوجوی زیر ۲۰ میلیثانیه در میان میلیاردها بردار روبهرو هستند.
امبدینگها (Embeddings) در قلب کاربردهای مدرن هوش مصنوعی قرار دارند. امبدینگ، برداری با ابعاد بالا است که معنای محتوایی (Semantic Meaning) متنی یا تصویری را بهصورت عددی نمایش میدهد. تعداد ابعاد در این بردارها معمولاً از چند صد تا بیش از هزار بعد متغیر است. این مجموعهی دو قسمتی، مقدمهای کامل دربارهی امبدینگها ارائه میدهد.
بر خلاف پایگاههای دادهی سنتی، جستوجو در یک پایگاه دادهی برداری بر اساس شباهت (Similarity) انجام میشود:
شما یک بردار ورودی ارائه میدهید و پایگاه داده بردارهایی را بازمیگرداند که بیشترین شباهت را با آن دارند. این شباهت بر پایهی یک عملیات ریاضی مانند فاصلهی کسینوسی (Cosine Distance) سنجیده میشود. علاوه بر شباهت، میتوان محدودیتهایی بر اساس فیلدهای فراداده (Metadata) نیز اعمال کرد.
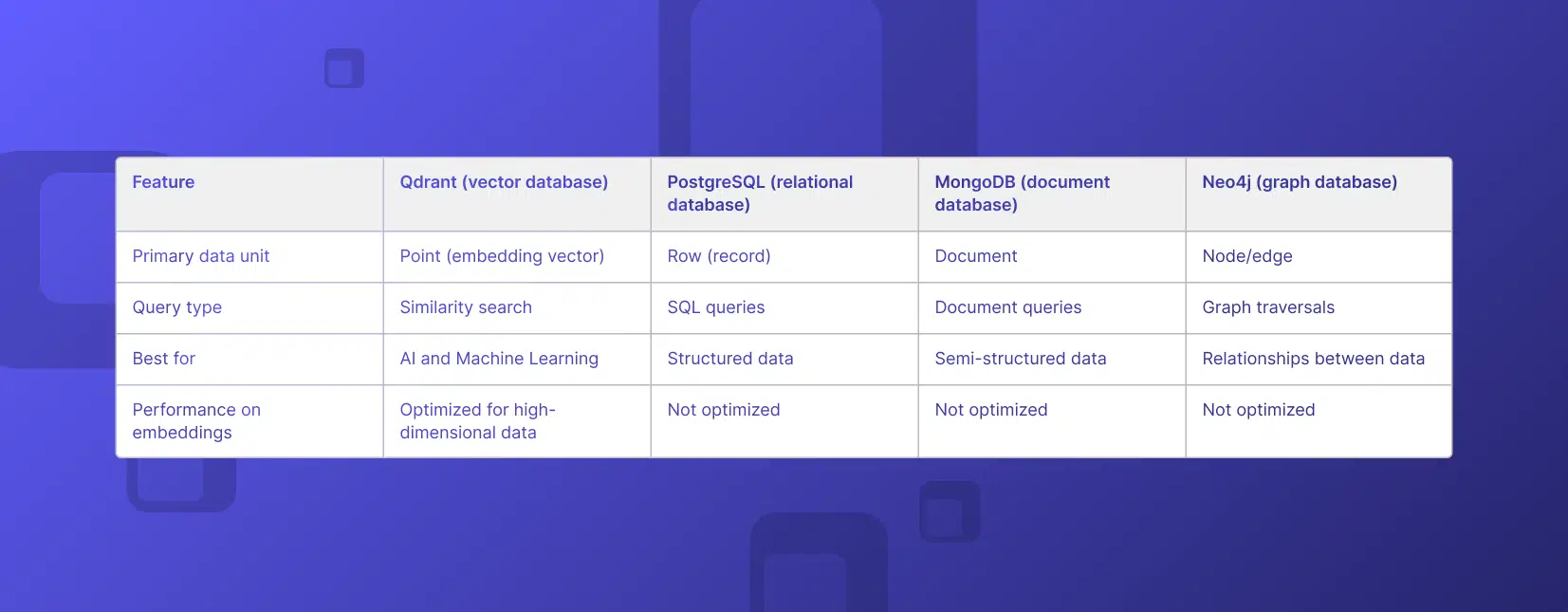
نه پایگاههای دادهی رابطهای مانند PostgreSQL، و نه پایگاههای دادهی سندی مانند MongoDB، و نه پایگاههای دادهی گرافی مانند Neo4j هیچکدام برای پردازش امبدینگهای با ابعاد بالا و در نتیجه برای کاربردهای هوش مصنوعی مناسب نیستند. اینجاست که پایگاههای دادهی برداری وارد میشوند.
Qdrant یک پایگاه دادهی برداری متنباز (Open-Source) است با کارایی استثنایی و قابلیت مقیاسپذیری در سطح سازمانی. این سیستم از قابلیتهای پیشرفتهای مانند بردارهای پراکنده (Sparse Vectors)، جستوجوی ترکیبی (Hybrid Search)، شتاب GPU و پردازش بلادرنگ دادههای چندحالته (Multi-Modal) پشتیبانی میکند. میتوانید آن را هم بهصورت Self-Hosted روی سرورهای خود اجرا کنید، و هم از خدمات ابری پرداختی شرکت با قابلیت استنتاج یکپارچه استفاده نمایید.
این مقاله، نمایی سطحبالا از Qdrant ارائه میدهد و زمینه را برای راهنماهای عملیتر بعدی فراهم میسازد. مقالهی بعدی در این مجموعه، شامل مثالهای کاربردی برای نشان دادن نحوهی استفاده از Qdrant است.
مفاهیم اصلی در معماری Qdrant چیست؟
۱. Points (نقاط)
در پایگاههای دادهی رابطهای مانند PostgreSQL، دادهها در جدولها (Tables) ذخیره میشوند و واحد اصلی داده، ردیف (Row) است.
هر آیتم توسط یک ردیف نمایش داده میشود و اطلاعات مربوط به آن در ستونهای آن ردیف ذخیره میگردد.
بهصورت مشابه، در Qdrant (بهعنوان یک پایگاه دادهی برداری)، واحد داده Point (نقطه) نامیده میشود.
این نام بهصورت استعاری انتخاب شده است، چون هر بردار را میتوان بهعنوان نقطهای در فضای چندبعدی امبدینگها در نظر گرفت.
نقاط (مشابه ردیفها) درون مجموعهها (Collections) قرار دارند (که مشابه جدولها هستند).
هر نقطه شامل موارد زیر است:
- بردار امبدینگ (Embedding Vector) – که اکنون از نمایشهای چندحالته شامل متن، تصویر و صوت پشتیبانی میکند
- شناسه (ID) – که میتواند یک UUID یا یک عدد صحیح بدون علامت ۶۴ بیتی باشد، با قابلیت نمایهسازی سریعتر برای بازیابی بهتر
- Payload اختیاری – یک شیء JSON که حاوی اطلاعات اضافی دربارهی آیتمی است که بردار نمایندهی آن است، با قابلیتهای فیلترینگ پیشرفتهتر
در غیاب ستونها، Payload به شما اجازه میدهد تا اطلاعات مرتبط با هر بردار را ذخیره کنید.
برای مثال، اگر بردار، امبدینگ یک متن باشد، Payload میتواند شامل مواردی مانند نام نویسنده، خودِ متن، و لینک منبع انتشار باشد.
مستندات Qdrant دربارهی Payload، این مفهوم را با جزئیات بیشتری شرح میدهد.
در زبان Python، از ماژول PointStruct برای ساخت نقاط استفاده میشود.
برای افزودن نقاط جدید به پایگاه داده، سه روش وجود دارد:
- upsert – اکنون با قابلیتهای بهبودیافته در پردازش دستهای (Batch Processing)
- upload_collection – با پردازش موازی (Parallel Processing) برای عملیات حجیم سریعتر
- upload_points – بهینهسازیشده برای دریافت دادهی جریانی (Streaming Ingestion)
تابع upsert پرکاربردترین روش است.
upload_collection و upload_points برای افزودن دادهها بهصورت دستهای به یک مجموعه استفاده میشوند.
این دو بهصورت خودکار دادهها را بر اساس منابع در دسترس بهینهسازی و دستهبندی میکنند.
در درون خود، هر دو این متدها در نهایت upsert را فراخوانی میکنند.
توجه کنید که Qdrant بهطور خودکار بردارها را نرمالسازی (Normalize) میکند و امکان تنظیم استراتژی نرمالسازی قابل پیکربندی را نیز فراهم میسازد.
عملیاتهای مهم قابل انجام روی نقاط عبارتاند از:
- بازیابی اطلاعات یک نقطه با استفاده از متد retrieve با گزینههای فیلترینگ پیشرفته
- بهروزرسانی بردار مرتبط با یک نقطه با استفاده از update_vectors با عملیات اتمی (Atomic Operations)
- بهروزرسانی Payload با استفاده از set_payload یا overwrite_payload با قوانین اعتبارسنجی (Validation Rules)
- حذف نقاط با استفاده از تابع delete با پشتیبانی از پردازش دستهای
برای شناسایی نقاط در این عملیاتها، میتوانید از روشهای زیر استفاده کنید:
- استفاده از ID نقطه با کارایی جستوجوی بهبودیافته
- اعمال شرایط فیلتر بر روی Payload (رجوع کنید به مستندات Qdrant دربارهی Filtering) با بهینهسازی پرسوجوهای پیشرفته
۲. Collections (مجموعهها)
مجموعهای از نقاط (Points) یک Collection (مجموعه) را تشکیل میدهد — مشابه جدولها (Tables) در پایگاههای دادهی رابطهای.
هر Collection، همانند جدول، باید نام یکتایی (Unique Name) داشته باشد.
در هنگام ایجاد یک Collection، باید موارد زیر را مشخص کنید:
- Size (تعداد ابعاد یا Dimensionality) بردارهایی که در آن ذخیره میشوند – اکنون تا ۶۵٬۵۳۶ بعد پشتیبانی میشود
- Distance Metric (معیار فاصله) که برای جستوجوی شباهت استفاده میشود، با الگوریتمهای پیشرفتهتر
- پیکربندی ذخیرهسازی (Storage Configuration) – شامل گزینههای ذخیرهسازی مبتنی بر دیسک برای استقرارهای بزرگمقیاس
- تنظیمات Quantization – برای بهینهسازی حافظه با استفاده از تکنیکهای فشردهسازی پیشرفته

۳. Distance Metric (معیار فاصله)
فاصله (Distance) در واقع نمایانگر میزان شباهت میان بردارها است.
بردارهایی که شباهت زیادی دارند، فاصلهی کمتری از هم دارند.
برای هر Collection، باید معیاری برای محاسبهی شباهت میان بردارها مشخص کنید.
Qdrant از معیارهای زیر پشتیبانی میکند:
- Dot Product (حاصلضرب نقطهای) — DOT با بهینهسازی SIMD
- Cosine Similarity (شباهت کسینوسی) — COSINE با پشتیبانی از شتاب GPU
- Euclidean Distance (فاصله اقلیدسی) — EUCLID بهینهسازیشده برای فضاهای با ابعاد بالا
- Manhattan Distance (فاصله منهتن) — MANHATTAN با کارایی بهتر برای بردارهای پراکنده (Sparse Vectors)
انتخاب معیار فاصله، تأثیر قابلتوجهی بر کارایی و دقت نتایج دارد.
برای امبدینگهای نرمالسازیشده، Cosine Similarity رایجترین گزینه است؛
در حالی که Dot Product برای سیستمهای پیشنهاددهی (Recommendation Systems) که به بزرگی مقادیر حساساند، عملکرد بهتری دارد.
۴. Multitenancy (چندمستاجری)
در پایگاههای دادهی رابطهای معمول است که جداول متعددی ایجاد شود،
اما در پایگاههای دادهی برداری، داشتن تعداد زیادی Collection باعث افت عملکرد میشود.
بنابراین، پیشنهاد میشود از یک Collection واحد استفاده کرده و دسترسی را با افزودن کلید اضافی (مانند group_id) به Payload هر Point محدود کنید.
در هنگام اجرای پرسوجو، با فیلتر کردن بر اساس این کلید، ایزولاسیون (Isolation) میان کاربران یا گروهها برقرار میشود.
این روش بهعنوان Multitenancy (چندمستاجری) شناخته میشود.
پیادهسازیهای مدرن Qdrant از الگوهای پیچیدهتر چندمستاجری پشتیبانی میکنند، از جمله:
- Sharding آگاه از مستاجر (Tenant-Aware Sharding)
- پارتیشنبندی خودکار داده (Automatic Data Partitioning)
این ساختار باعث حفظ کارایی بالا در عین تضمین ایزولاسیون سختگیرانه میان مستاجران میشود.
به لطف این رویکرد، برنامههای سازمانی میتوانند هزاران فضای نام مجزا (Namespaces) را بدون افت عملکرد مدیریت کنند.
۵. Quantization (کوانتیزیشن / فشردهسازی برداری)
بردارها معمولاً بهصورت اعداد اعشاری ۳۲ بیتی (float32) ذخیره میشوند که مصرف حافظهی بالایی دارند.
بهعنوان نمونه، امبدینگهای OpenAI با ۱۵۳۶ بعد، حدود ۹ کیلوبایت در هر بردار فضا اشغال میکنند.
یک مجموعه با میلیونها بردار از این نوع، میتواند بهراحتی دهها گیگابایت RAM مصرف کند.
Quantization اندازهی بردارها را با نمایش مؤلفهها در قالب بیتهای کمتر کاهش میدهد:
- اعداد صحیح ۸ بیتی (Scalar Quantization) — فشردهسازی ۴ برابری با حداقل افت دقت
- مقادیر بولی ۱ بیتی (Binary Quantization) — فشردهسازی ۳۲ برابری برای کاهش شدید حجم
- کدگذاری ۱٫۵ بیتی (Ternary Encoding) — فشردهسازی ۲۴ برابری با کارایی متعادل
- کوانتیزیشن نامتقارن ۲ بیتی (Asymmetric Quantization) — الگوریتمهای متفاوت برای ذخیرهسازی و پرسوجو
زمانی که کوانتیزیشن فعال باشد، Qdrant میتواند:
- Re-Score — جستوجو را روی بردارهای فشرده انجام داده، سپس با نسخهی اصلی بازنمرهدهی کند
- Oversample — نتایج بیشتری را از دادههای فشرده واکشی کرده و سپس با دقت کامل رتبهبندی نماید
- Adaptive Quantization — سطح فشردهسازی را بهصورت خودکار و بر اساس الگوی پرسوجو تنظیم کند
فعالسازی کوانتیزیشن از طریق پارامتر quantization_config هنگام ایجاد Collection انجام میشود.
در نسخههای اخیر، کوانتیزیشن با دقت تنظیمشده (Precision-Tuned Quantization) معرفی شده است که بیش از ۹۸٪ دقت Recall را حفظ کرده و در عین حال مصرف حافظه را بهطور قابلتوجهی کاهش میدهد.
۶. Indexing (نمایهسازی)
Qdrant از چندین استراتژی نمایهسازی بهینهشده برای موارد استفادهی مختلف پشتیبانی میکند:
- Vector Indexes (نمایههای برداری) — مبتنی بر الگوریتم HNSW پیشرفته با شتاب GPU
- Payload Indexes (نمایههای فراداده) — برای فیلدهای عددی، اعشاری، زمانی، رشتهای، و متنی کامل با کارایی جستوجوی بالا
- Sparse Vector Indexes — برای امبدینگهای پراکنده با ابعاد بالا
- Hybrid Indexes — ترکیب چندین نوع نمایه برای پرسوجوهای پیچیده
HNSW
الگوریتم Hierarchical Navigable Small World (HNSW) بردارها را در قالب گراف چندلایهای نمایش میدهد.
لایههای بالاتر دارای ارتباطات درشتتر و لایههای پایینتر دارای اتصالات دقیقتر هستند،
که تعادلی میان سرعت و دقت جستوجو برقرار میکند.
بهبودهای اخیر در HNSW شامل موارد زیر است:
- Delta-Encoded HNSW که فضای ذخیرهسازی گراف را تا ۳۸٪ کاهش میدهد
- ساخت افزایشی (Incremental Construction) که اجازه میدهد ۷۰٪ از یالهای موجود در هنگام بهروزرسانی مجدداً استفاده شوند
نمایهسازی شتابیافته با GPU در HNSW اکنون تا ۸٫۷ برابر سریعتر عمل میکند در حالیکه عملکرد جستوجو را حفظ میکند.
این ویژگی امکان بازسازی نمایهها در مجموعههای میلیاردی را در بازهی زمانی معقول فراهم میسازد.
چگونه خوشهبندی (Clustering) در Qdrant عملیات پیشرفتهی برداری را ممکن میسازد؟
خوشهبندی در Qdrant رویکردی پیشرفته برای سازماندهی و پرسوجوی دادههای برداری ارائه میدهد که فراتر از جستوجوی سادهی شباهت عمل میکند.
این قابلیت به متخصصان داده کمک میکند تا الگوهای پنهان را کشف کرده، بردارهای مشابه را بهصورت خودکار گروهبندی کنند و کارایی ذخیرهسازی را از طریق سازماندهی هوشمند دادهها افزایش دهند.
الگوریتمهای پویای خوشهبندی برداری (Dynamic Vector Clustering Algorithms)
Qdrant چندین روش خوشهبندی را پیادهسازی میکند که با ویژگیهای مختلف داده و کاربردها سازگار هستند.
این پلتفرم از موارد زیر پشتیبانی میکند:
- خوشهبندی k-means — بهینهشده برای فضاهای برداری با ابعاد بالا
- خوشهبندی سلسلهمراتبی (Hierarchical Clustering) — برای کشف الگوهای تو در تو
- خوشهبندی مبتنی بر چگالی (Density-Based Clustering) — که نقاط پرت (Outliers) و نویز را در مجموعههای برداری شناسایی میکند
موتور خوشهبندی Qdrant از دستورالعملهای SIMD و شتاب GPU برای پردازش کارآمد مجموعههای برداری عظیم بهره میبرد.
در کاربردهای سازمانی که میلیونها امبدینگ را پردازش میکنند، خوشهبندی Qdrant میتواند در عرض چند دقیقه (بهجای ساعتها) گروههای منسجم را شناسایی کند،
که این موضوع امکان تحلیل بلادرنگ (Real-Time Analytics) و سازماندهی پویا محتوا را فراهم میسازد.
پارتیشنبندی هوشمند داده (Intelligent Data Partitioning)
فراتر از گروهبندی پایه، خوشهبندی Qdrant از طریق پارتیشنبندی هوشمند دادهها کارایی پرسوجو را بهینه میکند.
بردارهای مشابه بهصورت فیزیکی در حافظه و روی دیسک در کنار هم قرار میگیرند،
که این کار حجم فضای جستوجو را کاهش داده و کارایی حافظهی کش (Cache Efficiency) را بهبود میدهد.
این سازماندهی مکانی (Spatial Organization) در استقرارهای بزرگمقیاس ارزش ویژهای دارد،
زیرا تأخیر پرسوجو (Query Latency) مستقیماً بر تجربهی کاربر اثر میگذارد.
سیستم بهصورت خودکار تعادل میان خوشهها (Auto-Rebalancing) را هنگام ورود دادهی جدید حفظ میکند تا از نقاط داغ (Hotspots) جلوگیری شود و کارایی پرسوجو ثابت بماند.
این بازتعادل پویا بهصورت شفاف (Transparent) عمل میکند، بهطوری که حتی با رشد داده از میلیونها به میلیاردها بردار، کارایی سیستم کاهش نمییابد.
کاربردهای خوشهبندی چندحالته (Multi-Modal Clustering Applications)
کاربردهای مدرن هوش مصنوعی روزبهروز بیشتر با دادههای چندحالته (Multi-Modal Data) کار میکنند —
ترکیبی از متن، تصویر و دادههای ساختاریافته.
Qdrant در شناسایی الگوهای میانحالتی (Cross-Modal Patterns) بسیار قدرتمند است،
مثلاً:
- گروهبندی تصاویر محصولاتی که توصیفهای متنی مشابهی دارند
- خوشهبندی بردارهای رفتار مشتری همراه با ویژگیهای جمعیتشناختی (Demographic Attributes)
این قابلیت امکان ساخت سیستمهای پیشنهاددهی چندبعدی را فراهم میکند که همزمان شباهتهای بصری، معنایی و رفتاری را در نظر میگیرند.
بهعنوان مثال، پلتفرمهای تجارت الکترونیک از این ویژگی برای دستهبندی محصولات بر اساس شباهت بصری و رابطهی معنایی استفاده میکنند،
که نتیجهی آن تجربهی کاربری شهودیتر و افزایش نرخ تبدیل (Conversion Rate) است.
چه کاربردهای نوظهوری در حال دگرگونی کاربرد پایگاههای دادهی برداری هستند؟
چشمانداز پایگاههای دادهی برداری فراتر از جستوجوی شباهت گسترش یافته است.
سازمانها در حال کشف کاربردهای نوآورانهای هستند که عملیات تجاری و تجربهی کاربر را متحول میکند.
این کاربردها قدرت و انعطافپذیری پلتفرمهای مدرن مانند Qdrant را نشان میدهند.
ارکستراسیون نسل بعدی عاملهای هوش مصنوعی (Next-Generation AI Agent Orchestration)
عاملهای هوش مصنوعی (AI Agents) نحوهی انجام جریانهای کاری چندمرحلهای (Multi-Step Workflows) را متحول کردهاند.
پایگاههای دادهی برداری به این عاملها امکان میدهند حافظهی مشترک معنایی (Semantic Memory) را از طریق ذخیرهی بردارها به اشتراک بگذارند،
تا عاملها بتوانند پیوستگی مکالمه و زمینه را حفظ کنند و دانش تخصصی در حوزههای مختلف را هماهنگ سازند.
در خدمات مالی، سیستمهای چندعاملی استفاده میشوند که در آن:
- عاملهای خدمات مشتری به بردارهای تعاملات گذشته دسترسی دارند تا زمینه را فوراً درک کنند،
- در حالی که عاملهای تخصصی دیگر بهترتیب به سؤالات صورتحساب، پشتیبانی فنی یا تشخیص تقلب پاسخ میدهند.
این معماری باعث کاهش زمان پاسخگویی (Resolution Time) و افزایش رضایت مشتری میشود.
شبکههای عامل لبهمحور (Edge-Native Agent Networks) نیز حوزهی نوینی هستند که در آن سیستمهای توزیعشدهی هوش مصنوعی،
دادهی حسگرها را بهصورت محلی پردازش کرده و از طریق تطابق شباهت برداری بین بینشها (Insights) به اشتراک میگذارند.
برای مثال، کارخانهها از این شبکهها در نگهداری پیشبینانه (Predictive Maintenance) استفاده میکنند،
جایی که عاملهای محلی، دادههای تلهمتری تجهیزات را تحلیل کرده و الگوهای ناهنجاری را بدون نیاز به پردازش مرکزی به اشتراک میگذارند.
تشخیص تقلب و تحلیل امنیتی بلادرنگ (Real-Time Fraud Detection and Security Analytics)
سیستمهای مدرن تشخیص تقلب از امبدینگهای برداری برای شناسایی الگوهای مشکوک در جریان تراکنشها بهصورت بلادرنگ استفاده میکنند.
با نمایش دنبالهی تراکنشها بهصورت بردارهایی که الگوهای زمانی، مکانی و رفتاری را رمزگذاری میکنند،
این سیستمها میتوانند ناهنجاریها را در چند میلیثانیه شناسایی کنند.
بانکها استراتژیهایی برای امبدینگ تراکنشها (Transaction Embedding) به کار میگیرند که رفتار کاربر را در طول زمان ثبت میکند.
این امر امکان شناسایی تسخیر حساب (Account Takeover) یا کلاهبرداری هویتی مصنوعی (Synthetic Identity Fraud) را از طریق تحلیل شباهت برداری فراهم میکند.
نتیجه: کاهش مثبتهای کاذب (False Positives) در حالی که دقت تشخیص بالا حفظ میشود —
که هم امنیت و هم تجربهی کاربر را بهبود میبخشد.
سیستمهای احراز هویت بیومتریک، امبدینگهای تشخیص چهره را همراه با فرادادههای کنترل دسترسی ذخیره میکنند،
و بدینترتیب امنیت فیزیکی بدون اعتماد (Zero-Trust) را از طریق احراز هویت و مجوز همزمان فراهم میسازند.
این کاربردها نشان میدهند که چگونه پایگاههای دادهی برداری از عملیات حساس به امنیت پشتیبانی میکنند که نیازمند سرعت و دقت بالا هستند.
تجربیات فوقالعاده شخصیسازیشده برای مشتری (Hyper-Personalized Customer Experiences)
پلتفرمهای تجارت الکترونیک بهطور فزاینده از استراتژیهای چندبرداری (Multi-Vector Strategies) استفاده میکنند تا سیستمهای پیشنهاددهی پیشرفتهای بسازند که همزمان
شباهت بصری، توضیحات متنی، ترجیحات کاربر و عوامل زمینهای را در نظر بگیرند.
این رویکرد امکان پرسوجوهایی مانند:
«محصولاتی را بیاب که از نظر تصویر شبیه این مورد هستند اما از مواد پایدار ساخته شدهاند.»
را فراهم میکند — پرسوجویی که چندین حالت داده (Data Modalities) را ترکیب میکند.
در حوزهی سلامت، از تحلیل شباهت بیماران (Patient Similarity Analysis) برای شناسایی الگوهای درمانی بیماریهای نادر استفاده میشود.
با مقایسهی امبدینگهای سوابق پزشکی الکترونیکی با دادههای بیماران و مقالات علمی،
سیستم میتواند موارد بالینی مرتبط را پیشنهاد دهد.
این کار باعث کاهش زمان تشخیص و بهبود نتایج درمانی از طریق شناسایی الگوهای مبتنی بر شواهد (Evidence-Based Patterns) میشود.
بهینهسازی فرایندهای صنعتی (Industrial Process Optimization)
سازمانهای تولیدی سیستمهای نگهداری پیشبینانه را پیادهسازی میکنند که دادههای حسگر تجهیزات را به بردار تبدیل میکنند.
این امر اجازه میدهد تا الگوهای خرابی احتمالی از طریق مقایسهی شباهت با سوابق تعمیرات گذشته شناسایی شوند.
این سیستمها از خرابیهای پرهزینه جلوگیری کرده و پایداری عملیات را افزایش میدهند.
در زنجیرهی تأمین، بردارهای مکانی (Geospatial Vectors) با الگوهای ترافیکی، اولویتها و محدودیتهای منابع ترکیب میشوند
تا مسیرهای حملونقل بهصورت پویا بهینه گردند.
شرکتهای لجستیکی گزارش دادهاند که این رویکرد موجب افزایش کارایی تحویل و کاهش هزینهها شده است.
بهویژه با استفاده از نرمافزارهای بهینهسازی مسیر (Routing Optimization Software)،
که علاوه بر بهبود بهرهوری، به برنامهریزی هوشمند مسیر، کاهش مصرف سوخت و افزایش رضایت مشتری منجر میشود.
ادغام با زیرساختهای دادهای موجود (Integration with Existing Data Infrastructure)
یکی از نقاط قوت اصلی Qdrant، سازگاری یکپارچهی آن با اکوسیستمهای دادهای موجود است.
در حالی که بسیاری از سازمانها از قبل از انبارهای دادهای، سیستمهای NoSQL، و چارچوبهای یادگیری ماشین استفاده میکنند،
Qdrant بدون نیاز به بازطراحی معماری، در میان این اجزا قرار میگیرد.
اتصال به پایپلاینهای ETL و ابزارهای پردازش داده
Qdrant بهصورت طبیعی با ابزارهای ETL (Extract, Transform, Load) مانند Airflow، Prefect، و Dagster ادغام میشود.
بردارها میتوانند مستقیماً از مدلهای یادگیری ماشین (مثلاً از طریق APIهای Hugging Face یا OpenAI) استخراج و در Qdrant بارگذاری شوند.
قابلیتهای دریافت داده بهصورت استریم (Streaming Ingestion) آن، از پردازش دادههای بلادرنگ پشتیبانی میکند.
همچنین، Qdrant از پروتکلهای اتصال استاندارد مانند gRPC و REST API پشتیبانی میکند،
که امکان تعامل مستقیم با سیستمهایی مانند Kafka، Spark، Flink و سایر چارچوبهای توزیعشده را فراهم میسازد.
ادغام با ابزارهای یادگیری ماشین (ML Integration)
Qdrant بهطور بومی با اکوسیستمهای هوش مصنوعی مدرن سازگار است.
کتابخانههای رسمی در زبانهای Python، Go، TypeScript، و Rust برای آن منتشر شدهاند.
در محیطهای یادگیری ماشین، Qdrant بهعنوان یک پایگاه دادهی برداری برای مدیریت حافظهی تعبیه (Embedding Memory Store) عمل میکند.
در چارچوبهایی مانند LangChain، LlamaIndex، و Haystack،
Qdrant اغلب بهعنوان زیرساخت بازیابی اطلاعات (Retrieval Layer) در سیستمهای RAG (Retrieval-Augmented Generation) استفاده میشود.
این نقش به مدلهای زبانی بزرگ (LLMs) اجازه میدهد تا به دادههای سازمانی دسترسی یافته و پاسخهای زمینهمحور و دقیقتر تولید کنند.
امنیت، حاکمیت داده و انطباق (Security, Governance, and Compliance)
Qdrant با رویکردی متمرکز بر امنیت و حاکمیت داده طراحی شده است تا با نیازهای سازمانی همتراز باشد.
در سطح ذخیرهسازی، دادهها از طریق رمزنگاری در حالت استراحت (Encryption at Rest) محافظت میشوند،
در حالی که ارتباطات بین نودها از طریق TLS ایمن میگردد.
پشتیبانی از مدیریت احراز هویت (Authentication) و کنترل دسترسی مبتنی بر نقش (RBAC)
امکان تفکیک مجوزها بین کاربران و سرویسها را فراهم میکند.
برای نمونه، میتوان کاربران را محدود کرد تا تنها به کالکشنهای خاص یا عملیات مشخص دسترسی داشته باشند.
از منظر حاکمیت داده (Data Governance)، Qdrant از ثبت رویدادها (Audit Logging) و ردیابی تغییرات (Change Tracking) پشتیبانی میکند،
که برای انطباق با مقرراتی مانند GDPR و CCPA ضروری است.
این ویژگیها باعث میشوند تا سازمانها بتوانند چرخهی عمر داده را با شفافیت کامل مدیریت کنند.
مقیاسپذیری و استقرار سازمانی (Scalability and Enterprise Deployment)
معماری Qdrant از ابتدا برای مقیاسپذیری افقی طراحی شده است.
این سیستم از Sharding خودکار برای توزیع دادهها بین نودهای مختلف و Replication چندگانه برای تداوم داده پشتیبانی میکند.
در سناریوهای حجیم، Qdrant میتواند تا میلیاردها بردار را در هزاران نود ذخیره و پردازش کند،
در حالی که زمان پاسخ را در حد چند میلیثانیه حفظ میکند.
نسخهی سازمانی Qdrant Cloud ویژگیهایی مانند:
- Autoscaling هوشمند بر اساس بار کاری (Workload-Aware Autoscaling)
- مدیریت ترافیک نودها با Load Balancer پویا
- Snapshot و Backup ایمن در سطح خوشه (Cluster-Level Backups)
را ارائه میدهد.
این قابلیتها به تیمهای مهندسی اجازه میدهند تا با حداقل تنظیمات،
سیستمهای مبتنی بر هوش مصنوعی در سطح سازمانی را در محیطهای Hybrid و Multi-Cloud استقرار دهند.
جمعبندی
پایگاههای دادهی برداری مانند Qdrant نقش مهمی در معماری هوش مصنوعی مدرن ایفا میکنند.
با پشتیبانی از امبدینگهای با ابعاد بالا، فیلترینگ پیشرفته، خوشهبندی پویا، و قابلیت مقیاسپذیری،
Qdrant به متخصصان داده و توسعهدهندگان اجازه میدهد تا سیستمهای هوشمند، سریع و چندحالته طراحی کنند.
این فناوری اکنون در قلب بسیاری از کاربردهای حیاتی — از جستوجوی معنایی و شخصیسازی محتوا گرفته تا تشخیص تقلب و ارکستراسیون عاملهای هوش مصنوعی — قرار گرفته است.
با پیشرفت مداوم Qdrant و ظهور مدلهای جدید امبدینگ،
انتظار میرود که این پلتفرم نقشی کلیدیتر در آیندهی زیرساختهای هوش مصنوعی ایفا کند.
پرسشهای متداول (FAQ)
۱. آیا Qdrant فقط برای جستوجوی برداری است؟
خیر. Qdrant علاوه بر جستوجوی شباهت، از فیلترینگ پیچیده، خوشهبندی، پردازش ترکیبی دادههای متنی و تصویری،
و تحلیل بلادرنگ دادههای چندحالته پشتیبانی میکند.
۲. تفاوت Qdrant با سایر پایگاههای دادهی برداری چیست؟
Qdrant تمرکز بالایی بر کارایی در مقیاس بزرگ، پایداری حافظه، و ویژگیهای سازمانی دارد.
همچنین، برخلاف بسیاری از رقبا، بهصورت متنباز با جامعهی توسعهی فعال ارائه شده است.
۳. آیا Qdrant برای محیطهای تولیدی مناسب است؟
بله. Qdrant در هزاران مورد استفادهی تولیدی از جمله تجارت الکترونیک، امور مالی، سلامت، و امنیت مستقر شده است.
نسخهی ابری آن با ویژگیهایی مانند Replication، Backup، و نظارت بلادرنگ (Monitoring)،
پشتیبانی سطح سازمانی را ارائه میدهد.
۴. آیا Qdrant از GPU پشتیبانی میکند؟
بله. Qdrant از شتاب GPU برای عملیات جستوجو، فشردهسازی (Quantization) و خوشهبندی بهره میبرد،
که باعث افزایش قابل توجه سرعت پردازش دادههای حجیم میشود.
۵. آیا میتوان دادههای موجود را به Qdrant مهاجرت داد؟
بله. Qdrant ابزارهایی برای وارد کردن داده از پایگاههای دادهی رابطهای، فایلهای CSV، و سیستمهای NoSQL ارائه میدهد،
و از طریق APIهای استاندارد REST و gRPC با هر نوع زیرساخت دادهای ادغام میشود.