
ETL مخفف Extract, Transform, Load است. یک سری فرآیندهای خودکار که رویکرد ساختاریافتهای برای تمام تلاشهای یکپارچهسازی دادهها ارائه میدهد. این فرآیند به شما کمک میکند جریان دادهها را از منابع مختلف جمعآوری کرده و آنها را به شکل قابل استفاده و قابل تحلیل تبدیل کنید تا بتوانید بینش عمیقتری به دست آورده و تصمیمات تجاری آگاهانه بگیرید.
این مقاله مروری بر پایپلاین ETL، نحوه عملکرد آن و مزایای آن ارائه میدهد. همچنین کاربردهای عملی اجرای ETL و نحوه استفاده از آنها برای بهبود مدیریت داده در سازمان شما بررسی خواهد شد.
پایپلاین ETL چیست؟
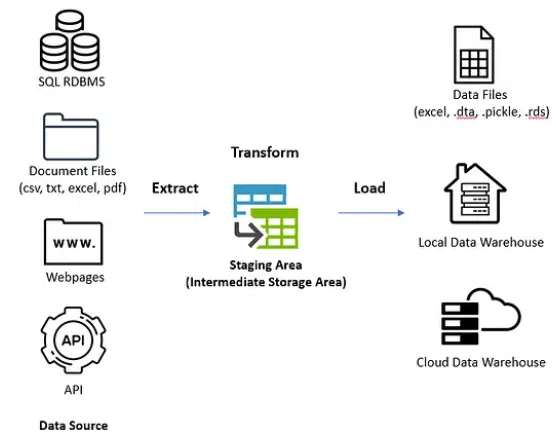
یک پایپلاین ETL یک جریان کاری برای آمادهسازی دادهها برای تحلیل است. این پایپلاین به شما کمک میکند دادهها را از منابع مختلف استخراج کرده و آنها را به فرمتی یکپارچه و قابل استفاده تبدیل کنید. این تبدیل ممکن است شامل پاکسازی دادهها، حذف مقادیر تکراری یا تبدیل آنها به یک ساختار خاص باشد.
سپس، دادههای تبدیلشده را میتوانید به سیستم مقصد مانند یک انبار داده بارگذاری کنید تا به راحتی برای گزارشگیری و هوش تجاری قابل دسترسی باشد.
پایپلاینهای ETL قابل استفاده مجدد هستند و میتوانند بارهای دادهای مختلف را مدیریت کنند، بنابراین برای کاربردهای متنوع قابل تطبیق هستند. بسته به نیاز شما، میتوانید آنها را برای اجرای برنامههای زمانی مختلف مانند ساعتی، روزانه، هفتگی یا هنگام رخدادهای خاص پیکربندی کنید.
همچنین میتوانید از پایپلاینهای ETL برای سناریوهای مختلف یکپارچهسازی داده، مانند پردازشهای دستهای یکباره، یکپارچهسازیهای خودکار مکرر یا یکپارچهسازی دادههای جریان (streaming) استفاده کنید. این پایپلاینها برای مدیریت مجموعه دادههایی که نیاز به تبدیل پیچیده دارند، بهینه هستند.
چگونه یک پایپلاین ETL کار میکند؟
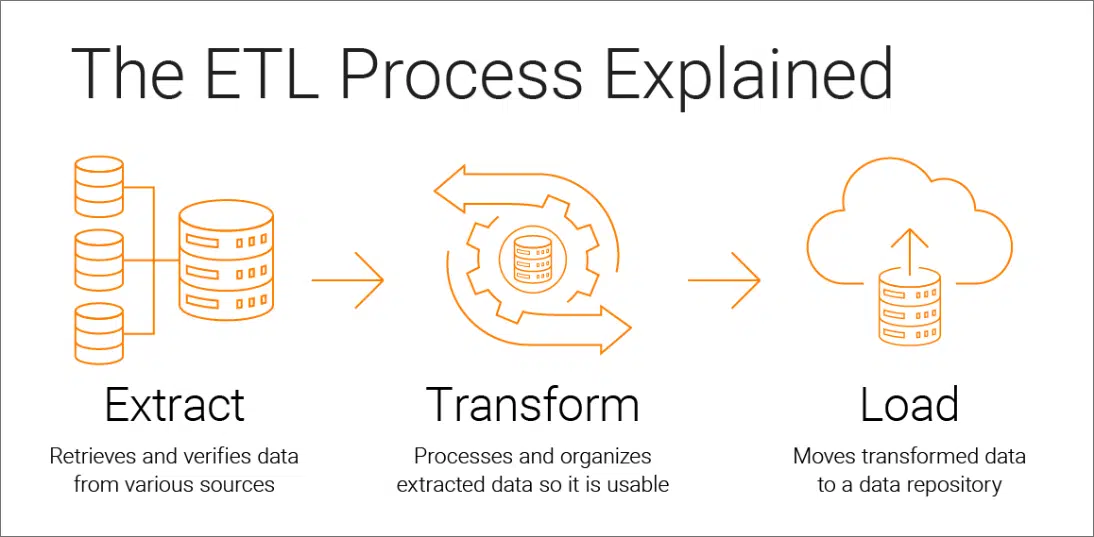
یک پایپلاین ETL شامل سه مرحله در کل فرآیند انتقال داده بین منبع و مقصد است استخراج، تبدیل و بارگذاری. اگر میخواهید یک پایپلاین ETL بسازید، میتوانید از Python یا Scala استفاده کنید. میتوانید پایپلاینها را با نوشتن کد سفارشی و مشخص کردن جزئیاتی مانند رشتههای اتصال منبع، منطق تبدیل و جدولهای مقصد پیکربندی کنید.
Extract
مرحله استخراج شامل اتصال به منابع داده مختلف و جمعآوری اطلاعاتی است که معیارهای خاصی را برآورده میکنند. این منابع میتوانند شامل پایگاههای داده، APIها، فایلهای مسطح، سرویسهای وب یا پلتفرمهای جریان داده باشند. فرآیندهای استخراج مدرن از هر دو حالت دستهای و زمان واقعی پشتیبانی میکنند و سازمانها را قادر میسازند همه چیز را از مهاجرت دادههای تاریخی تا جریانهای مداوم داده مدیریت کنند.
در طول استخراج، پایپلاین اتصالات امن به سیستمهای منبع برقرار میکند و پروتکلهای احراز هویت و مجوزدهی مناسب را اعمال میکند. مکانیزمهای پیشرفته استخراج شامل تکنیکهای تغییر داده (Change Data Capture) است که فقط رکوردهای تغییر یافته را شناسایی میکند، که باعث کاهش بار پردازشی و افزایش کارایی میشود. مکانیزمهای مدیریت خطا و تلاش مجدد اطمینان میدهند که جمعآوری دادهها حتی در صورت عدم دسترسی موقت سیستمهای منبع، پایدار باقی بماند.
Transform
در مرحله تبدیل، دادهها پردازش میشوند تا مطمئن شویم مقادیر، طرحواره، نوع داده و ساختار آنها با استفاده مورد نظر مطابقت دارند و با سیستم مقصد سازگار هستند. میتوانید بررسیهای کیفیت و اعتبار داده را اعمال کنید تا دادههای شما از خطا، ناسازگاری و مقادیر گمشده پاک بماند و یک ساختار منسجم ارائه شود. این اطمینان حاصل میکند که تحلیل و گزارشگیری دادهها قابل اعتماد و سازگار باشد.
تکنیکهای رایج تبدیل داده شامل Aggregators، data masking، expressions، joiners، filters، lookups، ranks، routers، unions، Normalizer، H2R و R2H هستند. استفاده از این تکنیکها به شما امکان میدهد دادهها را برای تحلیل پیشرفته، عملیات تجاری و مصورسازیها دستکاری، فیلتر، قالببندی، نرمالسازی و استاندارد کنید.
این تبدیلها در ناحیه staging انجام میشوند تا سیستم هدف شما را از خطاها و ناکارآمدیها محافظت کنند. این همچنین امکان ایجاد فرآیند ETL ماژولار و قابل استفاده مجدد را فراهم میکند.
Load
بارگذاری آخرین مرحله پایپلاین ETL است، جایی که دادههای تبدیلشده را به مقصد مورد نظر منتقل میکنید. این مقصد میتواند یک پایگاه داده محلی یا ابری، انبار داده، هاب داده یا دریاچه داده باشد.
این مرحله حیاتی شامل سه جنبه کلیدی است: نگاشت داده، تکنیکهای بارگذاری و حفظ یکپارچگی دادهها.
نگاشت داده تعیین میکند که هر عنصر داده از سیستم منبع چگونه با فیلد متناظر در طرحواره هدف هماهنگ شود.
پایپلاینهای ETL استراتژیهای بارگذاری مختلفی برای بهینهسازی عملکرد و حجم داده ارائه میدهند. بارگذاری دستهای (bulk load) برای مجموعه دادههای عظیم بهینه است، در حالی که بارگذاری افزایشی (incremental loading) برای دادههای بهروزرسانی شده مکرر مناسب است. میتوانید از روش بارگذاری کامل (full-load) نیز برای همگامسازی کامل دادهها استفاده کنید.
برای حفظ کیفیت دادههای بارگذاریشده، میتوانید از تکنیکهایی مانند اعتبارسنجی دادهها و اعمال کلید اصلی استفاده کنید.
ETL چیست؟
ETL یک فرآیند است که به شما امکان میدهد دادهها را از چندین منبع استخراج کرده، تبدیل و به یک مخزن مرکزی بزرگ مانند دریاچه یا انبار داده منتقل کنید. با استفاده از قوانین تجاری گسترده میتوانید دادهها را سازماندهی، یکپارچه و آماده ذخیرهسازی، تحلیل داده و مدلهای یادگیری ماشین کنید. این به شما امکان میدهد دیدی جامع از دادهها به دست آورید، جریانهای کاری را بهینه کرده و بینشهای دقیق و قابل اعتماد برای تصمیمگیری آگاهانه ایجاد کنید.
مزایای یک پایپلاین ETL چیست؟
پایپلاینهای ETL میتوانند به سازمان شما کمک کنند تا با منابع اطلاعات پراکنده مقابله کرده و جریان دادهای یکپارچه فراهم کنند. این امکان را به شما میدهد که تحلیل پیشرفته انجام داده، بینش ایجاد کرده و تصمیمات هوشمندانهتری بگیرید. برخی از مزایای پایپلاین ETL عبارتند از:
بهبود کارایی
با تحلیل جریانهای داده و شناسایی الگوهایی که هر گونه ناهنجاری یا خطر احتمالی را نشان میدهند، میتوانید از بینشهای نزدیک به زمان واقعی بهره برده و به مسائل به سرعت پاسخ دهید. این کارایی عملیاتی و فرآیندهای تجاری را بهطور قابل توجهی افزایش میدهد و به شما امکان میدهد از فرصتهای جدید استفاده کرده و مزیت رقابتی کسب کنید.
مقیاسپذیری
پایپلاینهای ETL میتوانند به راحتی حجم بالای دادهها را از منابع مختلف مدیریت کنند. آنها انعطافپذیر هستند و میتوانند بارهای دادهای در حال تغییر را بدون تأثیر بر عملکرد مدیریت کنند. معماریهای ETL مدرن ابری بهصورت خودکار منابع را بر اساس نیازهای کاری مقیاس میدهند و عملکرد بهینه در اوج پردازش را تضمین میکنند.
امنیت و انطباق
میتوانید کنترل دسترسی به دادهها و رمزگذاری را در پایپلاینهای ETL اعمال کرده و دادههای حساس را محافظت کنید. این پایپلاینها همچنین حرکت و تبدیل دادهها را ثبت میکنند و مسیر شفاف (audit trail) برای گزارشدهی و انطباق فراهم میکنند. پایپلاینهای پیشرفته شامل شناسایی خودکار PII و اعمال سیاستها برای حفظ انطباق در حوزههای قضایی مختلف هستند.
بهبود کیفیت دادهها
پایپلاینهای ETL با حذف رکوردهای تکراری، یکپارچهسازی فرمتهای داده و اصلاح دادههای نادرست در مرحله تبدیل، انسجام و قابلیت اطمینان دادهها را تضمین میکنند. این کیفیت کلی دادههای استفادهشده برای تحلیل و تصمیمگیری آگاهانه را افزایش میدهد. اعمال خودکار قوانین اعتبارسنجی و تشخیص ناهنجاریهای خودکار، مانع ورود دادههای آلوده به سیستمهای تحلیلی میشود.
صرفهجویی در هزینه
با استفاده از پایپلاینهای ETL میتوانید وظایف تکراری را خودکار کرده و هزینه محاسباتی در ناحیه staging را بهطور قابل توجهی کاهش دهید. این همچنین توان پردازشی مورد نیاز برای تحلیلهای پاییندستی را کاهش میدهد. پیادهسازیهای ابری بومی منابع را با پرداخت به ازای استفاده و مقیاسبندی خودکار بهینه میکنند و هزینههای منابع بلااستفاده را حذف میکنند.
ویژگیهای کلیدی یک پایپلاین ETL چیست؟
یک پایپلاین ETL پیوسته، چابک و انعطافپذیر است. میتواند به تغییرات حجم داده یا نیازها پاسخ دهد و همزمان کیفیت و انسجام دادهها را حفظ کند. ویژگیهای کلیدی عبارتند از:
پردازش پیوسته داده
در حالی که پایپلاینهای ETL میتوانند پردازش دستهای انجام دهند، آنها همچنین قادر به پردازش مداوم جریانهای داده بهصورت خودکار و بدون وقفه هستند. این اطمینان میدهد که دادهها بهروز باقی میمانند، بینشهای زمان واقعی فراهم میشود و تأخیر در دسترسی به دادهها کاهش مییابد. معماریهای ETL جریان داده مدرن، تأخیر کمتر از یک ثانیه برای عملیات تجاری حساس به زمان را پشتیبانی میکنند.
راهاندازی و نگهداری آسان
پایپلاینهای ETL مدرن دارای رابطهای کاربری دوستانه هستند. میتوانید آنها را به راحتی پیکربندی و اصلاح کنید که باعث کاهش قابل توجه زمان توسعه و هزینههای نگهداری میشود. قابلیتهای سلفسرویس به کاربران تجاری امکان میدهد بدون دانش فنی گسترده، یکپارچهسازی ایجاد کنند.
دستکاری داده منعطف
پایپلاینهای ETL به شما امکان میدهند دادههای خود را بهطور مؤثر دستکاری کنید. همچنین میتوانید آنها را به راحتی برای تغییرات در فرمت یا طرحواره دادهها تنظیم کنید تا دادهها مرتبط و مفید باقی بمانند. پایپلاینهای پیشرفته اکنون شامل قابلیتهای تکامل هوشمند طرحواره هستند که بهطور خودکار با تغییرات سیستم منبع سازگار میشوند.
کنترل دسترسی به داده
پایپلاینهای ETL کنترل دقیق بر حرکت دادهها ارائه میدهند. میتوانید سیستمهای منبع، منطق تبدیل و مقصد هدف را تعریف کنید تا اطمینان حاصل شود اطلاعات دقیق و مرتبط برای تحلیل ارائه میشوند. کنترل دسترسی مبتنی بر نقش تضمین میکند که دادههای حساس در طول جریان کاری پایپ لاین محافظت شوند.
چگونه هوش مصنوعی میتواند مدیریت پایپلاین ETL را تغییر دهد؟
هوش مصنوعی توسعه پایپلاینهای ETL را از نگهداری واکنشی به بهینهسازی پیشگیرانه متحول کرده است. سیستمهای ETL مدرن مبتنی بر AI از الگوریتمهای یادگیری ماشین برای خودکارسازی نگاشت طرحواره، پیشبینی نیازهای منابع و اصلاح خودکار خطاهای پایپلاین بدون دخالت انسان استفاده میکنند.
تکامل هوشمند طرحواره
الگوریتمهای AI اکنون بهطور خودکار تغییرات طرحواره در سیستمهای منبع را شناسایی کرده و تبدیلها را مجدداً نگاشت میکنند در حالی که یکپارچگی داده حفظ میشود. این چرخه سنتی تعمیر-شکست را حذف میکند که منابع مهندسی زیادی را مصرف میکرد.
بهینهسازی پیشبینی منابع
پلتفرمهای پیشرفته ETL از یادگیری تقویتی برای تحلیل الگوهای بار کاری تاریخی و تنظیم خودکار تخصیص منابع قبل از ایجاد گلوگاه استفاده میکنند. این سیستمها زمانهای اوج پردازش را پیشبینی کرده، زیرساخت را پیشگیرانه مقیاس میدهند و اندازه دستهها را برای کاهش هزینههای ابری بهینه میکنند.
اجرای خودکار کیفیت داده
موتورهای کیفیت داده مبتنی بر AI پایههای رفتاری برای جریانهای داده ورودی ایجاد کرده و بهطور خودکار ناهنجاریهایی که از آستانههای آماری فراتر میروند را علامتگذاری میکنند. هنگامی که ناهنجاریها شناسایی شوند، سیستمها میتوانند دادههای مشکوک را قرنطینه کرده، تبدیلهای اصلاحی اعمال کرده یا گردشهای کاری بازبینی انسانی را بر اساس سطح شدت فعال کنند.
معماری خودترمیم پایپلاین
پایپلاینهای ETL مدرن دارای قابلیت خودترمیم هستند که بهطور خودکار سناریوهای شکست رایج را شناسایی و اصلاح میکنند. مدلهای یادگیری ماشین تلومتری پایپلاین را تحلیل کرده تا الگوهای پیش از وقوع خطا را شناسایی کرده و اقدامات پیشگیرانه انجام دهند. وقتی خطا رخ دهد، سیستمها میتوانند بهطور خودکار با پارامترهای تنظیم شده دوباره تلاش کنند، دادهها را از مسیرهای جایگزین عبور دهند یا به پیکربندی پایدار قبلی بازگردند.
نقش مشاهدهپذیری دادهها در عملیات مدرن ETL
مشاهدهپذیری دادهها تحول پارادایمی از نظارت واکنشی به مدیریت سلامت پیشگیرانه پایپلاین ایجاد میکند. برخلاف نظارت سنتی سیستم که بر شاخصهای زیرساخت تمرکز دارد، مشاهدهپذیری داده دید جامع از کیفیت داده، ریشه و الگوهای عملیاتی در طول فرآیند ETL ارائه میدهد.
نظارت چندبعدی پایپلاین
مشاهدهپذیری مؤثر نیازمند اندازهگیری مداوم در پنج بعد اصلی است: تازگی داده، انسجام حجم، ثبات طرحواره، الگوهای توزیع و یکپارچگی ریشه داده. پلتفرمهای مدرن بهطور خودکار رفتار پایه برای هر بعد را تعیین کرده و زمانی که انحراف از حد آستانه پیکربندی شده فراتر رود، هشدار میدهند.
شناسایی خودکار ناهنجاریها
الگوریتمهای یادگیری ماشین الگوهای تاریخی پایپلاین را برای شناسایی ناهنجاریها تحلیل میکنند بدون نیاز به قوانین از پیش تعریفشده. این سیستمها مشکلاتی مانند تغییر تدریجی داده، تغییر حجم غیرمنتظره یا افزایش تأخیر پردازش که ممکن است مشکلات بالادستی را نشان دهند شناسایی میکنند.
خودکارسازی تحلیل علت ریشهای
پلتفرمهای مشاهدهپذیری پیشرفته تحلیل علت ریشهای را با همبستگی ناهنجاریهای داده با شاخصهای اجرای پایپلاین، شاخصهای عملکرد سیستم و وابستگیهای خارجی خودکار میکنند. این زمان مورد نیاز برای شناسایی و حل مشکلات پایپلاین را بهطور چشمگیری کاهش میدهد.
مدیریت انطباق پیشگیرانه
چارچوبهای مشاهدهپذیری اکنون انطباق با مقررات را مستقیماً در عملیات پایپلاین تعبیه میکنند از طریق اعمال سیاست خودکار و تولید مسیر ممیزی. این سیستمها جریان داده را بهطور مداوم نظارت میکنند تا اطمینان حاصل شود که رمزگذاری، کنترل دسترسی و سیاستهای نگهداری بهدرستی اعمال میشوند.
تکنیکهای نوظهور پردازش ETL زمان واقعی
پردازش ETL زمان واقعی فراتر از عملیات دستهای سنتی تکامل یافته است تا نیازهای تصمیمگیری فوری و تحلیل عملیاتی را برآورده کند. تکنیکهای مدرن از معماری جریان داده و الگوهای رویدادمحور برای پردازش دادهها با تأخیر میلیثانیهای در سیستمهای توزیعشده استفاده میکنند.
ادغام Change Data Capture
مکانیزمهای CDC لاگهای تراکنش پایگاه داده را نظارت میکنند تا فقط رکوردهای تغییر یافته را به سیستمهای پاییندستی منتقل کنند. این روش بار پردازشی را کاهش داده و همزمانی نزدیک به زمان واقعی بین پایگاههای داده عملیاتی و پلتفرمهای تحلیلی را امکانپذیر میکند.
معماری پایپلاین رویدادمحور
سیستمهای ETL رویدادمحور به تغییرات داده از طریق صفهای پیام و پلتفرمهای جریان داده پاسخ میدهند، نه از طریق کارهای دستهای زمانبندیشده. Apache Kafka و سرویسهای جریان ابری مدرن امکان پایپلاینهایی را فراهم میکنند که بلافاصله پس از ورود داده، تبدیلها را اجرا کنند.
چارچوبهای پردازش جریان
موتورهای یکپارچه دستهای-جریانی امکان پردازش دادههای تاریخی و جریانهای زمان واقعی را با منطق و زیرساخت یکسان فراهم میکنند. پلتفرمهایی مانند Apache Flink و قابلیتهای structured streaming در پلتفرمهای مدرن داده، تبدیلهای پیچیده از جمله تجمیع پنجرهای، join حالتدار و تحلیل زمانی را با تضمین پردازش دقیق یکبار ارائه میدهند.
بهینهسازی میکروبچ
سیستمهای ETL جریان پیشرفته عملکرد را با میکروبچینگ هوشمند بهینه میکنند که تعادل بین نیازهای تأخیر و کارایی پردازش را برقرار میسازد. این سیستمها اندازه دستهها را بر اساس سرعت داده، بار سیستم و ظرفیت پاییندستی تنظیم میکنند تا از حداکثر بهرهوری در عین رعایت SLAهای تأخیر اطمینان حاصل شود.
چگونه معماریهای مدرن ETL مقیاسپذیری و بهینهسازی هزینه را حل میکنند؟
معماریهای مدرن ETL بر مقیاسپذیری انعطافپذیر و کارایی هزینه از طریق طراحیهای ابری بومی تمرکز دارند که بهطور خودکار با نیازهای کاری سازگار شده و استفاده از منابع را در محیطهای محاسبات توزیعشده بهینه میکنند.
ادغام محاسبات بدون سرور
معماریهای ETL بدون سرور مدیریت زیرساخت را حذف کرده و پردازش را بر اساس رویداد مقیاس میدهند. این سیستمها فقط برای زمان محاسبه مصرفشده در پردازش داده هزینه میگیرند و هزینهها را برای بارهای کاری نامنظم یا انفجاری کاهش میدهند و مقیاسپذیری نامحدود برای اوج پردازش فراهم میکنند.
ارکستراسیون مبتنی بر کانتینر
پلتفرمهای ETL مبتنی بر Kubernetes تخصیص منابع دقیق و مقیاسپذیری افقی از طریق بارهای کانتینری را ممکن میکنند. این معماریها محیطهای پردازش جداگانه برای منابع مختلف داده فراهم کرده و امکان بهینهسازی هزینهها از طریق اشتراک منابع و مقیاسگذاری خودکار را فراهم میکنند.
پارادایمهای Zero-ETL
رویکردهای Zero-ETL حرکت داده را به حداقل میرسانند و امکان پرسوجوی مستقیم از منابع داده توزیعشده از طریق فناوریهای مجازیسازی و فدراسیون را فراهم میکنند. این معماریها هزینه ذخیرهسازی را کاهش داده، تأخیر تکثیر را حذف کرده و نگهداری پایپلاین را ساده میکنند و در عین حال تحلیل زمان واقعی بر دادههای عملیاتی را بدون کاهش عملکرد سیستم منبع ممکن میسازند.
تخصیص هوشمند منابع
پلتفرمهای مدرن با استفاده از یادگیری ماشین الگوهای استفاده تاریخی را تحلیل کرده و نیازهای منابع برای بارهای کاری آینده را پیشبینی میکنند. این سیستمها بهطور خودکار منابع محاسبات و ذخیرهسازی بهینه را فراهم میکنند و از طریق استفاده از spot instance، برنامهریزی ظرفیت رزرو شده و خاموش کردن خودکار منابع بلااستفاده در دورههای کمفعالیت، کنترل هزینهها را اعمال میکنند.
مقایسه پایپلاینهای ETL با پایپلاینهای داده
یک پایپلاین داده مفهومی گستردهتر است که اجزای زیرساخت تحلیل داده سازمان شما را نشان میدهد. این شامل فناوریهای مختلفی است که امکان بررسی، خلاصهسازی و یافتن الگوها در دادهها را فراهم میکنند و پروژههایی مانند ML و مصورسازی دادهها را پشتیبانی میکنند. ETL یکی از فرآیندهایی است که در پایپلاینهای داده برای استخراج، تبدیل و بارگذاری دادهها استفاده میکنید.
etl pipeline 03
| ویژگی | پایپلاین داده | پایپلاین ETL |
| هدف | برای وظایف مختلف پردازش داده، از جمله انبار داده، تحلیل زمان واقعی، جریان داده یا یادگیری ماشین | عمدتاً برای انبار داده و گزارشگیری، تمرکز بر آمادهسازی داده برای تحلیل |
| تبدیل | ممکن است رخ دهد یا نه | تبدیل یک عملکرد اصلی است |
| تأخیر | میتواند پردازش زمان واقعی یا دستهای را پشتیبانی کند | معمولاً شامل پردازش دستهای با تأخیر بالاتر (اگرچه ETL جریاندار رایج میشود) |
| ریشه داده | پیگیری منبع و تبدیلها ممکن است چالشبرانگیز باشد | تأکید قوی بر ریشه داده؛ اغلب مراحل تبدیل ثبت میشوند |
| پیچیدگی | از پایین تا بالا بسته به پردازش | نسبتاً بالا به دلیل فرآیندهای تبدیل متعدد |
نتیجهگیری
پایپلاینهای ETL رویکرد ساختاریافتهای برای یکپارچهسازی داده ارائه میدهند که دادههای خام از منابع مختلف را به فرمتهای قابل استفاده برای تحلیل تبدیل میکنند. چه هدف شما هوش تجاری، تحلیل بازاریابی یا نظارت زمان واقعی باشد، پایپلاینهای ETL به شما کمک میکنند فرآیندهای داده را بهینه کرده و مزیت رقابتی حفظ کنید.
سؤالات متداول
چه زبانی در یک پایپلاین ETL استفاده میشود؟
اکثر ابزارهای ETL رابطهای تصویری ارائه میدهند، اما میتوانید پایپلاینهای ETL را با زبانهای برنامهنویسی عمومی مانند Python یا Java بسازید. پلتفرمهای مدرن بیشتر از تبدیلهای مبتنی بر SQL و رویکردهای توسعه کمکد پشتیبانی میکنند.
ETL و ELT چیستند؟
ETL و ELT دو رویکرد برای ساخت پایپلاین داده هستند. در ETL، داده قبل از بارگذاری در سیستم مقصد تبدیل میشود؛ در ELT، داده ابتدا بارگذاری شده و در داخل سیستم مقصد تبدیل میشود.
یک کسبوکار چگونه پایپلاین ETL خود را اجرا میکند؟
برخی از کسبوکارها به اسکریپتهای سفارشی Python که بهصورت موازی اجرا میشوند، متکی هستند، در حالی که برخی دیگر از پلتفرمهایی مانند Airbyte، ابزارهای ابری مدرن یا راهحلهای سازمانی استفاده میکنند. انتخاب بستگی به نیازهای فنی، بودجه و مقیاسپذیری دارد.
آیا ساخت ETL یا پایپلاین داده در Node امکانپذیر است؟
بله. Node.js میتواند گزینه مناسبی باشد، به ویژه برای پروژههای کوچک یا آنهایی که نیاز به عملکرد نزدیک به زمان واقعی دارند. با این حال، Python و Java همچنان محبوبتر برای پیادهسازی ETL سازمانی هستند.
چگونه یک پایپلاین ETL را تست کنم؟
کیفیت دادهها را در هر مرحله—استخراج، تبدیل و بارگذاری—با مقایسه دادههای منبع و مقصد بررسی کنید تا از دقت و کامل بودن آن اطمینان حاصل شود. تست مدرن شامل اعتبارسنجی خودکار دادهها، تشخیص drift طرحواره و بنچمارک عملکرد است.
پایپلاین ETL کمهزینه چیست؟
یک پایپلاین ETL کمهزینه مصرف منابع را در حین پردازش به حداقل میرساند از طریق ابزارهای کارآمد، کد بهینه و جلوگیری از تبدیلهای غیرضروری. معماریهای ابری بومی با مقیاسگذاری خودکار، بهرهوری منابع و هزینهها را بهینه میکنند.