
کاهش نرمالسازی داده مدرن شامل تکنیکهای پیشرفتهای است که به تعادل بین بهینهسازی عملکرد و حفظ یکپارچگی داده کمک میکند.
در حالی که پایگاههای داده نرمالشده برای سازماندهی دادهها عالی هستند، ممکن است فرآیندهایی که نیاز به کوئریهای پیچیده دارند را کند کنند. در این سناریوها، میتوان از مفهوم کاهش نرمالسازی مدل داده برای بهبود عملکرد کوئری پایگاه داده و تسهیل بازیابی سریعتر داده استفاده کرد.
این مقاله به شما کمک میکند تا بفهمید کاهش نرمالسازی داده چگونه کار میکند، تکنیکهای آن را بررسی کنید، مزایای آن را درک کنید، موارد استفاده را کشف کنید و بهترین شیوهها را مرور کنید.
کاهش نرمالسازی داده چیست؟
کاهش نرمالسازی مدل داده یک فرآیند بهینهسازی است که افزونگی پیشمحاسبهشده را به یک پایگاه داده نرمالشده اضافه میکند. در حالی که نرمالسازی دادهها با تقسیم دادهها به جداول کوچکتر و مرتبط، تکرار داده را کاهش داده و یکپارچگی داده را حفظ میکند، کاهش نرمالسازی بخشی از این یکپارچگی را قربانی میکند تا عملکرد خواندن بهبود یابد. یک پایگاه داده دینرمالشده با پایگاه دادهای که هرگز نرمال نشده است متفاوت است؛ کاهش نرمالسازی معمولاً پس از فرآیند نرمالسازی پایگاه داده اعمال میشود.
ویژگیهای کلیدی:
-
بهبود عملکرد کوئری: کاهش جوینهای پیچیده با تجمیع دادهها در یک جدول، سرعت عملیات خواندن مکرر را افزایش میدهد.
-
بازیابی ساده داده: تعداد کمتر جداول یا فرمتهای پیشمحاسبهشده، دسترسی سریعتر برای برنامههای کاربری نهایی فراهم میکند.
-
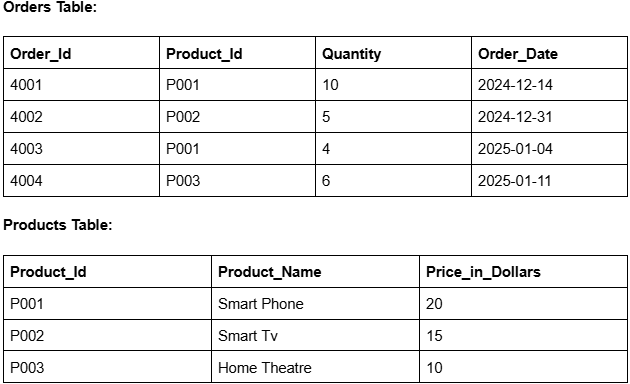
تجمیع سریع: ذخیره مقادیر تجمیعشده (مجموعها، میانگینها، تعدادها) محاسبات در زمان اجرا را کاهش داده و کوئریهای تحلیلی را تسریع میکند.
کاهش نرمالسازی داده چگونه کار میکند؟
برای درک کاهش نرمالسازی، ابتدا نحوه سازماندهی دادهها در پایگاه داده نرمالشده را در نظر بگیرید و سپس ببینید کاهش نرمالسازی چگونه میتواند عملکرد را بهبود دهد.
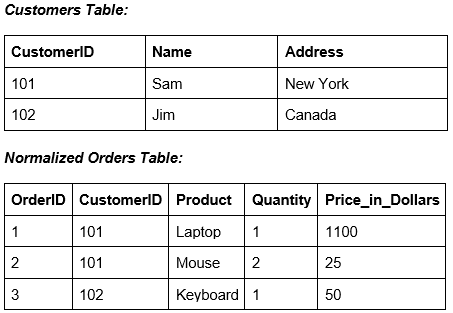
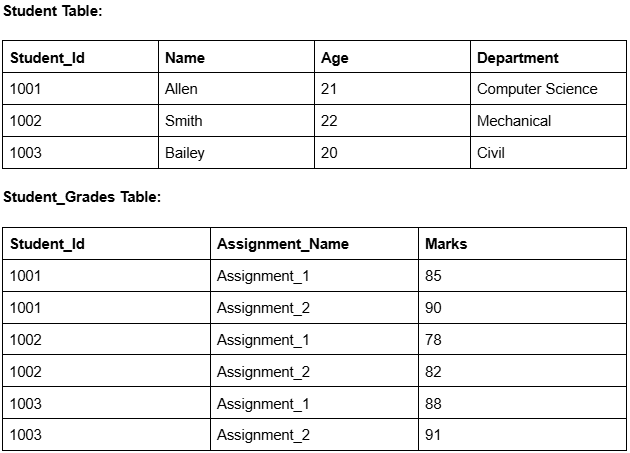
تصور کنید یک پلتفرم تجارت الکترونیک با جداول Customers و Orders که از طریق CustomerID به هم مرتبط هستند. برای نمایش تمام سفارشات یک مشتری، سایت باید این جداول را جوین کند — عملیاتی پرهزینه در مقیاس بزرگ.
برای کاهش این هزینه:
-
ستون Name را از جدول Customers در Orders کپی کنید تا نیاز به جوین حذف شود.

-
یک جدول جدید ایجاد کنید که دادههای هر دو جدول را با هم ترکیب کند.

deno 03
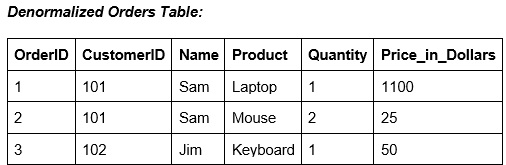
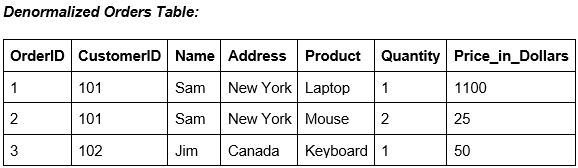
پنج تکنیک اصلی کاهش نرمالسازی داده چیست؟
-
پیشجوین کردن جداول:
تکرار ستونهای خاص در جداول برای جلوگیری از جوینهای مکرر.
-
جداول آینهای:
حفظ یک نسخه کامل یا جزئی حاوی دادههای مرتبط برای سادهسازی کوئریها.
-
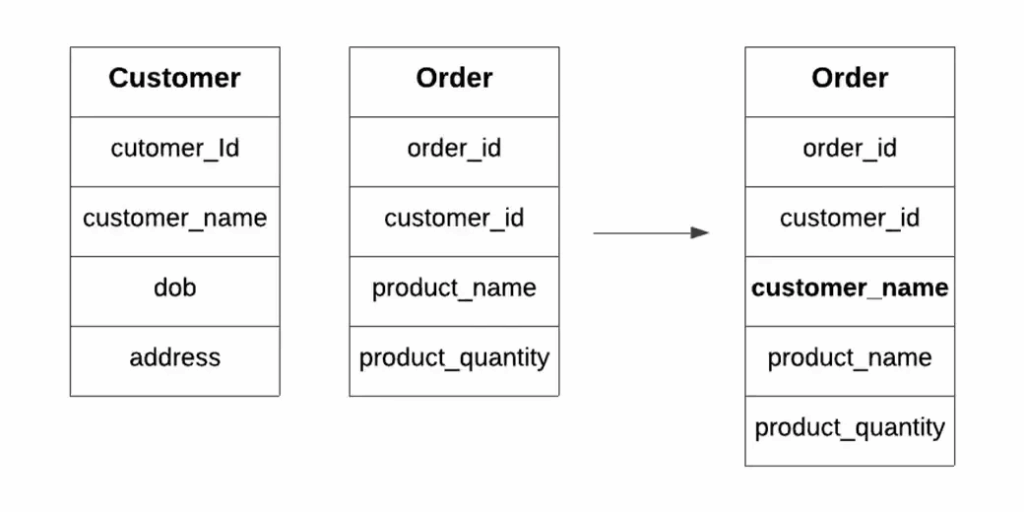
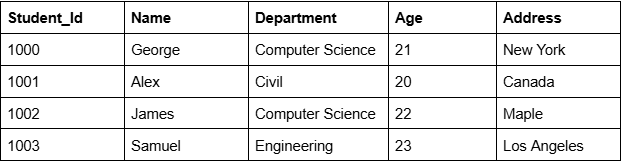
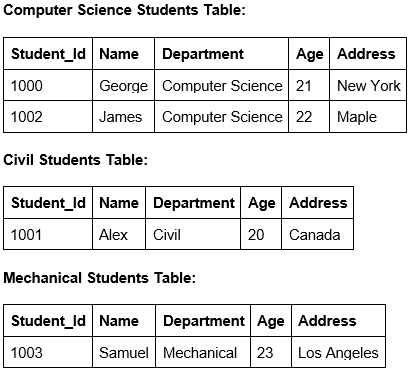
تقسیم جدول:
جدول را به چند جدول برای دسترسی سریعتر تقسیم کنید.

-
تقسیم افقی


-
تقسیم عمودی


-
افزودن ستونهای مشتقشده:
ذخیره مقادیر پیشمحاسبهشده برای جلوگیری از محاسبات در زمان اجرا.
-
نمایشهای مادیشده (Materialized Views):
ذخیره نتایج کوئری بهصورت یک جدول برای دسترسی سریع.
استراتژیهای پیشرفته مدیریت یکپارچگی برای سیستمهای دینرمالشده
حفظ یکپارچگی دادهها در ساختارهای دینرمالشده، چالش اصلی در پیادهسازی استراتژیهای بهینهسازی مبتنی بر افزونگی است. رویکردهای مدرن از مکانیزمهای همگامسازی پیشرفته، چارچوبهای نظارتی خودکار و الگوهای معماری بهره میبرند تا تعادل بین افزایش عملکرد و حفظ یکپارچگی داده را برقرار کنند.
تریگرهای تراکنشی و منطق لایه برنامه:
تریگرهای پایگاه داده همگامسازی بلادرنگ را با اجرای اسکریپتهای از پیش تعریفشده هنگام تغییر داده فراهم میکنند. هنگام پیادهسازی کاهش نرمالسازی از طریق تریگرها، بهروزرسانیها در جداول منبع بهطور خودکار تغییرات را به تمام نسخههای دینرمالشده وابسته در همان محدوده تراکنش منتقل میکنند. به عنوان مثال، یک تریگر AFTER UPDATE بر روی فیلد نام مشتری میتواند تغییرات را به تمام رکوردهای دینرمالشده سفارش حاوی آن نام منتقل کند و اتمیک بودن را از طریق تضمین تراکنش ACID حفظ کند.
منطق لایه برنامه رویکرد جایگزینی ارائه میدهد که بهروزرسانیهای دوگانه را در عملیات کسبوکار کپسوله میکند و زمانبندی همگامسازی و مدیریت خطا را کنترل میکند. این رویکرد بهویژه در معماریهای میکروسرویس ارزشمند است، جایی که تریگرهای پایگاه داده نمیتوانند مرزهای سرویس را پوشش دهند و هماهنگی برنامه برای حفظ یکپارچگی لازم است.
Change Data Capture و همگامسازی مبتنی بر رویداد:
سیستمهای CDC مانند Debezium یا Oracle GoldenGate تغییرات پایگاه داده را به مصرفکنندگان پاییندست منتقل میکنند و کاهش نرمالسازی بلادرنگ را بدون اتصال مستقیم به پایگاه داده امکانپذیر میسازند. CDC تغییرات ردیف به ردیف را با تأخیر بسیار کم ضبط کرده و آنها را به رویدادهای ساختاریافته تبدیل میکند که بهطور خودکار نسخههای دینرمالشده را همگام میکنند.
معماریهای مبتنی بر رویداد، CDC را با ارائه تحویل پیام مطمئن و تضمین پردازش تکمیل میکنند. هنگامی که جداول منبع تغییر میکنند، خطوط CDC رویدادهای تغییر را به پیامرسانها منتشر میکنند که سرویسهای پاییندست آنها را مصرف کرده و نمایشهای مادیشده، ستونهای مشتق و جداول آینهای را بهروزرسانی میکنند. این رویکرد امکان مدلهای همگامسازی تدریجی (eventual consistency) را فراهم میکند.
ادغام Command Query Responsibility Segregation (CQRS):
معماریهای CQRS بهطور طبیعی با استراتژیهای کاهش نرمالسازی هماهنگ هستند، زیرا ساختارهای نرمالشده بهینهشده برای نوشتن را از نمایشهای دینرمالشده بهینهشده برای خواندن جدا میکنند. بخش نوشتن اسکیمای نرمالشده را حفظ میکند و عملیات تراکنشی را پشتیبانی میکند، در حالی که بخش خواندن این تغییرات را به ساختارهای دینرمالشده منتقل میکند که برای الگوهای کوئری و نیازهای دسترسی بهینه شدهاند.
این جداسازی امکان مقیاس مستقل را فراهم میکند و معماری Event Sourcing اغلب CQRS را تکمیل میکند، زیرا تغییرات وضعیت را بهصورت توالیهای غیرقابل تغییر و دارای timestamp ثبت میکند و امکان بازسازی پروجکشنها برای هر نقطه تاریخی را برای مصارف بازنگری فراهم میآورد.
چارچوبهای خودکار نظارت و بازسازی:
پیادهسازیهای مدرن کاهش نرمالسازی سیستمهای نظارت خودکار دارند که انحراف داده بین نسخههای منبع و دینرمالشده را از طریق مقایسه چکسام و تحلیل آماری پیگیری میکنند. این سیستمها معیارهای یکپارچگی پایه را تعیین کرده و هنگام تجاوز انحراف از آستانههای تعریفشده، جریانهای کاری بازسازی خودکار را فعال میکنند.
خطوط خود-ترمیم بهطور خودکار ناسازگاریهای داده در ساختارهای دینرمالشده را از طریق الگوریتمهای تشخیص ناهنجاری شناسایی و اصلاح میکنند و بدون ایجاد اختلال عملیاتی، جداول دینرمالشده را بازسازی میکنند.
پلتفرمهای ابری چگونه پیادهسازی کاهش نرمالسازی را تغییر میدهند؟
پلتفرمهای داده بومی ابر بهطور اساسی اقتصاد و الگوهای معماری کاهش نرمالسازی را تغییر میدهند و با ارائه مقیاس الاستیک، جداسازی منابع ذخیرهسازی و محاسبات و موتورهای بهینهسازی پیشرفته، مبادلات عملکردی سنتی را به مزیت رقابتی استراتژیک تبدیل میکنند.
جداسازی دینامیک ذخیره و محاسبه:
پلتفرمهای مدرن ابری مانند Snowflake و Databricks هزینههای ذخیره را از منابع محاسباتی جدا میکنند و امکان کاهش نرمالسازی در مقیاس بزرگ را فراهم میآورند. Snowflake با میکرو-پارتیشنبندی ذخیره فیزیکی جداول دینرمالشده را بهینه میکند و Databricks Delta Lake تراکنشهای سازگار با ACID و مدیریت هوشمند فایل را برای معماریهای دینرمال ارائه میدهد.
جداول دینامیک و اتوماسیون اعلامی:
Dynamic Tables در Snowflake خطوط کاهش نرمالسازی دستی را با ساختارهای اعلامی جایگزین میکنند که دادهها را با تازهسازی افزایشی و معماری streams & tasks مدیریت میکنند. Delta Live Tables در Databricks نیز قابلیتهای مشابهی ارائه میدهد و جریان داده زمان واقعی را با جداول ابعاد آهسته تغییر دینامیک ترکیب میکند.
مدیریت هوشمند نمایش مادیشده:
پلتفرمهای ابری نمایشهای مادیشده را از اسنپشاتهای استاتیک به داراییهای دینرمالیزهشده دینامیک با قابلیتهای بهینهسازی پیشرفته تبدیل کردهاند. بهروزرسانیها و مدیریت خودکار این نمایشها باعث حفظ یکپارچگی بدون مداخله دستی میشود.
ادغام برداری و پشتیبانی بار کاری هوش مصنوعی:
رشد نمایی بار کاری AI و ML باعث توسعه روشهای کاهش نرمالسازی مبتنی بر embedding برداری و جستجوی شباهت در پلتفرمهای ابری شده است. دادههای تراکنشی با بردارهای ویژگی پیشمحاسبهشده و ایندکسهای نزدیکترین همسایه کنار هم قرار میگیرند، که امکان جستجوی سریع برای موتورهای توصیه، تشخیص تقلب و الگوریتمهای شخصیسازی را بدون جوینهای پرهزینه فراهم میکند.
کاهش نرمالسازی پیشبینیکننده با یادگیری ماشین:
الگوریتمهای یادگیری ماشین الگوهای کوئری و فراوانی دسترسی را تحلیل میکنند تا خودکاراً کاندیداهای کاهش نرمالسازی را شناسایی کنند و دورههای اوج استفاده را پیشبینی و بهترین روشها را توصیه کنند.
کاهش نرمالسازی مبتنی بر embedding برای بار کاری AI:
بردارهای تراکنشی خام همراه با embeddingهای پیشمحاسبهشده کنار هم قرار میگیرند و جستجوی شباهت سریع را برای توصیهها، تشخیص تقلب و شخصیسازی فراهم میکنند. نرمالسازی برداری تضمین میکند که محاسبات شباهت از نظر ریاضی سازگار باشد و توصیهها وابسته به علاقه کاربر باشند، نه فقط محبوبیت.
بهینهسازی خودکار و سیستمهای خودترمیم:
موتورهای خودمختار استراتژیهای کاهش نرمالسازی را بر اساس معیارهای زمان واقعی تنظیم و در صورت بروز ناهنجاری جداول دینرمالشده را بازسازی میکنند. خطوط خودترمیم ناسازگاریها را شناسایی و بدون نیاز به مداخله دستی اصلاح میکنند.
مقایسه ساختارهای داده نرمال و دینرمال
| جنبه | داده نرمال | داده دینرمال |
|---|---|---|
| ساختار داده | چندین جدول مرتبط | جداول تجمیعشده |
| کارایی ذخیره | بالا | کمتر (فضای بیشتر) |
| عملکرد کوئری | کندتر (Joins) | سریعتر (Joins کمتر) |
| یکپارچگی داده | قوی | ضعیفتر |
| عملکرد نوشتن | سریعتر | کندتر |
| نگهداری | سادهتر | پیچیدهتر |
| پشتیبانی GenAI | کاهش دقت | حفظ زمینه |
| استفاده معمول | OLTP | OLAP |
مزایای کلیدی کاهش نرمالسازی مدل داده
-
کاهش پیچیدگی کوئری: جوینهای کمتر به SQL سادهتر و خطاهای کمتر منجر میشود.
-
بهبود مقیاسپذیری برنامه: تعداد تراکنش کمتر، مقیاسپذیری را در بارهای خواندن سنگین بهبود میدهد.
-
تولید گزارش سریعتر: جداول آینهای یا نمایشهای مادیشده، تجمیعها را برای داشبورد و BI سرعت میبخشند.
موارد استفاده عملی مؤثر
-
انبار داده خردهفروشی با BigQuery: ساختارهای تو در تو و تکراری BigQuery اجازه میدهند ابعاد در داخل جداول واقعی جاسازی شوند و جوینها حذف شده و سرعت کوئری افزایش یابد.
-
مدیریت مشتری Salesforce: شی Contact چندین شماره تلفن، ایمیل و آدرس را در یک رکورد دینرمالشده ذخیره میکند و دید کامل مشتری را بدون جوین ارائه میدهد.
بهترین شیوهها
-
ابتدا برای حفظ یکپارچگی نرمالسازی کنید و تنها در موارد نیاز به عملکرد کاهش نرمالسازی اعمال شود.
-
جداول و کوئریهایی که بیشترین تأخیر را ایجاد میکنند هدف قرار دهید.
-
ساختارهای دینرمالشده را مانیتور کرده و با تغییر حجم داده یا الگوهای دسترسی تنظیم کنید.
-
مکانیسمهایی مانند تریگرها، کارهای دستهای و خطوط CDC برای همگامسازی دادههای افزوده اجرا کنید.
-
طراحیها را بهطور دورهای بازبینی کنید تا تعادل بین یکپارچگی، ذخیره و سرعت حفظ شود.
نتیجهگیری
کاهش نرمالسازی داده بهصورت استراتژیک افزونگی را برای بهینهسازی عملکرد کوئری در بارهای خواندن فشرده وارد میکند و تعادل بین سرعت و یکپارچگی داده را برقرار میسازد. تکنولوژیهای مدرن مانند CDC، پلتفرمهای بومی ابری و بهینهسازی مبتنی بر AI، روشهای سنتی کاهش نرمالسازی را قابل مدیریتتر و مؤثرتر کردهاند. پیادهسازی دقیق تکنیکهای کاهش نرمالسازی و مکانیزمهای همگامسازی، به سازمانها اجازه میدهد عملکرد قابلتوجهی در تحلیلها، گزارشدهی و کاربردهای AI داشته باشند و همزمان یکپارچگی داده حفظ شود.
سوالات متداول
کاهش نرمالسازی داده چیست و چرا استفاده میشود؟
کاهش نرمالسازی فرآیند اضافه کردن عمدی افزونگی به پایگاه داده نرمالشده برای سرعت بخشیدن به عملکرد کوئری است.
آیا کاهش نرمالسازی یکپارچگی داده را به خطر میاندازد؟
بله، اما سیستمهای مدرن با تریگرهای تراکنشی، CDC و معماریهای مبتنی بر رویداد این ریسک را کاهش میدهند.
چه زمانی باید مدل داده خود را دینرمالیزه کنید؟
زمانی که پیچیدگی کوئری یا تأخیر خواندن تبدیل به گلوگاه شود، معمولاً در سیستمهای OLAP، تحلیل بلادرنگ یا بارهای کاری AI.
اصلیترین معایب کاهش نرمالسازی چیست؟
افزایش مصرف ذخیره، پیچیدگی نوشتن و هزینه نگهداری بیشتر؛ اینها با بهبود عملکرد خواندن و سادهتر شدن منطق کوئری متعادل میشوند.