
شاردینگ پایگاه داده چیست؟
شاردینگ پایگاه داده فرآیند ذخیرهسازی یک پایگاه داده بزرگ در چندین ماشین است. یک ماشین واحد یا سرور پایگاه داده، فقط میتواند مقدار محدودی از داده را ذخیره و پردازش کند. شاردینگ پایگاه داده با تقسیم دادهها به قطعات کوچکتر به نام شارد و ذخیرهسازی آنها در چندین سرور پایگاه داده، بر این محدودیت غلبه میکند. معمولاً همه سرورهای پایگاه داده از فناوریهای زیربنایی یکسانی برخوردارند و با هم برای ذخیره و پردازش حجم زیادی از دادهها کار میکنند.
چرا شاردینگ پایگاه داده مهم است؟
با رشد یک برنامه، تعداد کاربران برنامه و میزان دادهای که ذخیره میکند به مرور زمان افزایش مییابد. اگر حجم دادهها خیلی زیاد شود و کاربران زیادی به طور همزمان سعی در استفاده از برنامه برای خواندن یا ذخیره اطلاعات داشته باشند، پایگاه داده به یک گلوگاه تبدیل میشود. برنامه کند میشود و تجربه مشتری را تحت تأثیر قرار میدهد. شاردینگ پایگاه داده یکی از روشهای حل این مشکل است زیرا پردازش موازی مجموعههای داده کوچکتر را در بین شاردها امکانپذیر میکند.
مزایای شاردینگ پایگاه داده چیست؟
سازمانها از شاردینگ پایگاه داده برای دستیابی به مزایای زیر استفاده میکنند:
- بهبود زمان پاسخ: بازیابی دادهها در یک پایگاه داده بزرگ واحد بیشتر طول میکشد. سیستم مدیریت پایگاه داده باید ردیفهای زیادی را جستجو کند تا داده صحیح را بازیابی کند. در مقابل، شاردهای داده نسبت به کل پایگاه داده ردیفهای کمتری دارند. بنابراین، بازیابی اطلاعات خاص یا اجرای یک پرسش از یک پایگاه داده شارد شده زمان کمتری میبرد.
- جلوگیری از قطع کامل سرویس: اگر کامپیوتری که میزبان پایگاه داده است از کار بیفتد، برنامهای که به پایگاه داده وابسته است نیز از کار میافتد. شاردینگ پایگاه داده با توزیع بخشهایی از پایگاه داده در کامپیوترهای مختلف از این امر جلوگیری میکند. از کار افتادن یکی از کامپیوترها باعث خاموش شدن برنامه نمیشود زیرا میتواند با سایر شاردهای کاربردی به کار خود ادامه دهد. شاردینگ اغلب در ترکیب با تکثیر داده در بین شاردها انجام میشود. بنابراین، اگر یک شارد غیرقابل دسترس شود، میتوان به دادهها از یک شارد جایگزین دسترسی پیدا کرد و آنها را بازیابی کرد.
- مقیاسپذیری کارآمد: یک پایگاه داده در حال رشد منابع محاسباتی بیشتری مصرف میکند و در نهایت به ظرفیت ذخیرهسازی میرسد. سازمانها میتوانند از شاردینگ پایگاه داده برای افزودن منابع محاسباتی بیشتر برای پشتیبانی از مقیاسپذیری پایگاه داده استفاده کنند. آنها میتوانند شاردهای جدید را در زمان اجرا بدون خاموش کردن برنامه برای تعمیر و نگهداری اضافه کنند.
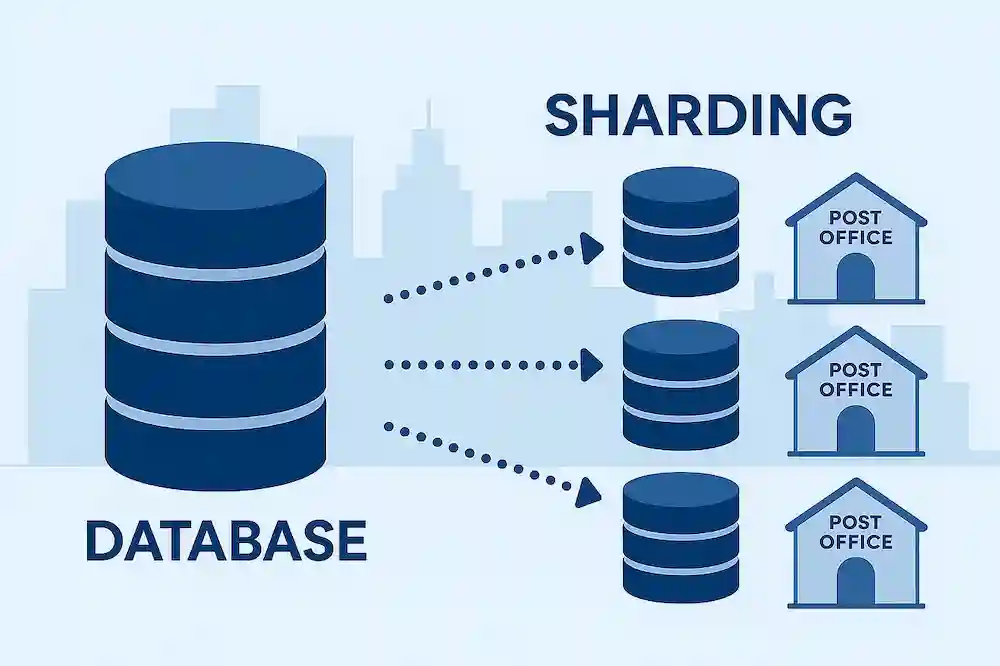
شاردینگ پایگاه داده چگونه کار میکند؟
یک پایگاه داده اطلاعات را در مجموعههای داده متعددی متشکل از ستونها و ردیفها ذخیره میکند. شاردینگ پایگاه داده یک مجموعه داده واحد را به پارتیشنها یا شاردها تقسیم میکند. هر شارد شامل ردیفهای منحصر به فردی از اطلاعات است که میتوانید آنها را به طور جداگانه در چندین کامپیوتر به نام گره ذخیره کنید. همه شاردها روی گرههای جداگانه اجرا میشوند اما طرح یا طراحی اصلی پایگاه داده را به اشتراک میگذارند.
به عنوان مثال، یک پایگاه داده شارد نشده که شامل یک مجموعه داده برای سوابق مشتری است ممکن است به این شکل باشد:
| شناسه مشتری | نام | ایالت |
|---|---|---|
| ۱ | جان | کالیفرنیا |
| ۲ | جین | واشنگتن |
| ۳ | پائولو | آریزونا |
| ۴ | وانگ | جورجیا |
شاردینگ شامل جدا کردن ردیفهای مختلف اطلاعات از جدول و ذخیره آنها در ماشینهای مختلف است، همانطور که در زیر نشان داده شده است:
کامپیوتر A:
| شناسه مشتری | نام | ایالت |
|---|---|---|
| ۱ | جان | کالیفرنیا |
| ۲ | جین | واشنگتن |
کامپیوتر B:
| شناسه مشتری | نام | ایالت |
|---|---|---|
| ۳ | پائولو | آریزونا |
| ۴ | وانگ | جورجیا |
شاردها:
قطعات پارتیشنبندی شده داده، شاردهای منطقی نامیده میشوند. ماشینی که شارد منطقی را ذخیره میکند، شارد فیزیکی یا گره پایگاه داده نامیده میشود. یک شارد فیزیکی میتواند شامل چندین شارد منطقی باشد.
کلید شارد:
توسعهدهندگان نرمافزار از یک کلید شارد برای تعیین نحوه پارتیشنبندی مجموعه داده استفاده میکنند. یک ستون در مجموعه داده تعیین میکند که کدام ردیفهای داده با هم گروهبندی شوند تا یک شارد را تشکیل دهند. طراحان پایگاه داده یک کلید شارد را از یک ستون موجود انتخاب میکنند یا یک ستون جدید ایجاد میکنند.
معماری بدون اشتراک:
شاردینگ پایگاه داده بر روی یک معماری بدون اشتراک عمل میکند. هر شارد فیزیکی به طور مستقل عمل میکند و از سایر شاردها بیاطلاع است. فقط شاردهای فیزیکی که حاوی دادههای مورد درخواست شما هستند، دادهها را به صورت موازی برای شما پردازش میکنند.
یک لایه نرمافزاری ذخیرهسازی و دسترسی به دادهها را از این شاردهای متعدد هماهنگ میکند. به عنوان مثال، برخی از انواع فناوری پایگاه داده دارای ویژگیهای خودکار شاردینگ داخلی هستند. توسعهدهندگان نرمافزار همچنین میتوانند کد شاردینگ را در برنامه خود برای ذخیره یا بازیابی اطلاعات از شارد یا شاردهای صحیح بنویسند.
روشهای شاردینگ پایگاه داده چیست؟
روشهای شاردینگ پایگاه داده قوانین مختلفی را برای کلید شارد اعمال میکنند تا گره صحیح را برای یک ردیف داده خاص تعیین کنند. در زیر معماریهای رایج شاردینگ آورده شده است:
- شاردینگ مبتنی بر محدوده: شاردینگ مبتنی بر محدوده یا شاردینگ پویا، ردیفهای پایگاه داده را بر اساس محدودهای از مقادیر تقسیم میکند. سپس طراح پایگاه داده یک کلید شارد را به محدوده مربوطه اختصاص میدهد. به عنوان مثال، طراح پایگاه داده دادهها را مطابق با اولین حرف الفبا در نام مشتری به شرح زیر پارتیشنبندی میکند:
| نام | کلید شارد |
|---|---|
| شروع با A تا I | A |
| شروع با J تا S | B |
| شروع با T تا Z | C |
هنگامی که یک رکورد مشتری در پایگاه داده نوشته میشود، برنامه با بررسی نام مشتری، کلید شارد صحیح را تعیین میکند. سپس برنامه کلید را با گره فیزیکی آن مطابقت میدهد و ردیف را روی آن ماشین ذخیره میکند. به طور مشابه، برنامه هنگام جستجوی یک رکورد خاص، یک تطابق معکوس انجام میدهد.
- مزایا و معایب: بسته به مقادیر داده، شاردینگ مبتنی بر محدوده میتواند منجر به بارگذاری بیش از حد دادهها در یک گره فیزیکی واحد شود. در مثال ما، شارد A (شامل نامهایی که با A تا I شروع میشوند) ممکن است تعداد بسیار بیشتری از ردیفهای داده نسبت به شارد C (شامل نامهایی که با T تا Z شروع میشوند) داشته باشد. با این حال، پیادهسازی آن آسانتر است.
- شاردینگ هش شده: شاردینگ هش شده با استفاده از یک فرمول ریاضی به نام تابع هش، کلید شارد را به هر ردیف از پایگاه داده اختصاص میدهد. تابع هش اطلاعات را از ردیف میگیرد و یک مقدار هش تولید میکند. برنامه از مقدار هش به عنوان کلید شارد استفاده میکند و اطلاعات را در شارد فیزیکی مربوطه ذخیره میکند.
توسعهدهندگان نرمافزار از شاردینگ هش شده برای توزیع یکنواخت اطلاعات در یک پایگاه داده بین چندین شارد استفاده میکنند. به عنوان مثال، نرمافزار سوابق مشتری را به دو شارد با مقادیر هش متناوب ۱ و ۲ جدا میکند.
| نام | مقدار هش |
|---|---|
| جان | ۱ |
| جین | ۲ |
| پائولو | ۱ |
| وانگ | ۲ |
- مزایا و معایب: اگرچه شاردینگ هش شده منجر به توزیع یکنواخت دادهها بین شاردهای فیزیکی میشود، پایگاه داده را بر اساس معنای اطلاعات جدا نمیکند. بنابراین، توسعهدهندگان نرمافزار ممکن است هنگام افزودن شاردهای فیزیکی بیشتر به محیط محاسباتی، با مشکلاتی در تخصیص مجدد مقدار هش روبرو شوند.
- شاردینگ دایرکتوری: شاردینگ دایرکتوری از یک جدول جستجو برای مطابقت اطلاعات پایگاه داده با شارد فیزیکی مربوطه استفاده میکند. یک جدول جستجو مانند جدولی در یک صفحه گسترده است که یک ستون پایگاه داده را به یک کلید شارد پیوند میدهد. به عنوان مثال، نمودار زیر یک جدول جستجو برای رنگهای لباس را نشان میدهد.
| رنگ | کلید شارد |
|---|---|
| آبی | A |
| قرمز | B |
| زرد | C |
| مشکی | D |
هنگامی که یک برنامه اطلاعات لباس را در پایگاه داده ذخیره میکند، به جدول جستجو مراجعه میکند. اگر لباسی آبی باشد، برنامه اطلاعات را در شارد مربوطه ذخیره میکند.
- مزایا و معایب: توسعهدهندگان نرمافزار از شاردینگ دایرکتوری استفاده میکنند زیرا انعطافپذیر است. هر شارد یک نمایش معنادار از پایگاه داده است و محدود به محدودهها نیست. با این حال، اگر جدول جستجو حاوی اطلاعات نادرست باشد، شاردینگ دایرکتوری با مشکل مواجه میشود.
- شاردینگ جغرافیایی: شاردینگ جغرافیایی اطلاعات پایگاه داده را بر اساس موقعیت جغرافیایی تقسیم و ذخیره میکند. به عنوان مثال، یک وب سایت خدمات دوستیابی از یک پایگاه داده برای ذخیره اطلاعات مشتریان از شهرهای مختلف به شرح زیر استفاده میکند.
| نام | کلید شارد |
|---|---|
| جان | کالیفرنیا |
| جین | واشنگتن |
| پائولو | آریزونا |
توسعهدهندگان نرمافزار از شهرها به عنوان کلید شارد استفاده میکنند. آنها اطلاعات هر مشتری را در شاردهای فیزیکی که از نظر جغرافیایی در شهرهای مربوطه قرار دارند، ذخیره میکنند.
- مزایا و معایب: شاردینگ جغرافیایی به برنامهها اجازه میدهد تا به دلیل فاصله کوتاهتر بین شارد و مشتری که درخواست را میدهد، اطلاعات را سریعتر بازیابی کنند. اگر الگوهای دسترسی به داده عمدتاً مبتنی بر جغرافیا باشند، این روش به خوبی کار میکند. با این حال، شاردینگ جغرافیایی نیز میتواند منجر به توزیع ناهموار دادهها شود.
چگونه شاردینگ پایگاه داده را برای توزیع یکنواخت داده بهینه کنیم؟
هنگامی که بارگذاری بیش از حد داده در شاردهای فیزیکی خاص رخ میدهد در حالی که سایرین کم بار هستند، منجر به نقاط داغ پایگاه داده میشود. نقاط داغ روند بازیابی را در پایگاه داده کند میکنند و هدف شاردینگ داده را از بین میبرند.
انتخاب خوب کلید شارد میتواند دادهها را به طور مساوی در بین چندین شارد توزیع کند. هنگام انتخاب یک کلید شارد، طراحان پایگاه داده باید عوامل زیر را در نظر بگیرند:
-
کاردینالیتی: کاردینالیتی مقادیر ممکن کلید شارد را توصیف میکند. حداکثر تعداد شاردهای ممکن را در پایگاه دادههای ستونمحور جداگانه تعیین میکند. به عنوان مثال، اگر طراح پایگاه داده یک فیلد داده بله/خیر را به عنوان کلید شارد انتخاب کند، تعداد شاردها به دو محدود میشود.
-
فراوانی: فراوانی احتمال ذخیره اطلاعات خاص در یک شارد خاص است. به عنوان مثال، یک طراح پایگاه داده سن را به عنوان کلید شارد برای یک وب سایت تناسب اندام انتخاب میکند. بیشتر رکوردها ممکن است به گرههایی برای مشترکین بین ۳۰ تا ۴۵ سال بروند و منجر به نقاط داغ پایگاه داده شوند.
-
تغییر یکنواخت: تغییر یکنواخت نرخ تغییر کلید شارد است. یک کلید شارد که به صورت یکنواخت افزایش یا کاهش مییابد منجر به شاردهای نامتعادل میشود. به عنوان مثال، یک پایگاه داده بازخورد به سه شارد فیزیکی مختلف به شرح زیر تقسیم میشود:
- شارد A بازخورد مشتریانی را که ۰ تا ۱۰ خرید انجام دادهاند ذخیره میکند.
- شارد B بازخورد مشتریانی را که ۱۱ تا ۲۰ خرید انجام دادهاند ذخیره میکند.
- شارد C بازخورد مشتریانی را که ۲۱ خرید یا بیشتر انجام دادهاند ذخیره میکند.
با رشد کسب و کار، مشتریان بیش از ۲۱ خرید یا بیشتر انجام میدهند. برنامه بازخورد آنها را در شارد C ذخیره میکند. این منجر به یک شارد نامتعادل میشود زیرا شارد C حاوی رکوردهای بازخورد بیشتری نسبت به سایر شاردها است.
جایگزینهای شاردینگ پایگاه داده چیست؟
شاردینگ پایگاه داده یک استراتژی مقیاسپذیری افقی است که گرهها یا کامپیوترهای اضافی را برای به اشتراک گذاشتن حجم کاری یک برنامه اختصاص میدهد. سازمانها از مقیاسپذیری افقی به دلیل معماری مقاوم در برابر خطای آن سود میبرند. هنگامی که یک کامپیوتر از کار میافتد، سایرین بدون وقفه به کار خود ادامه میدهند. طراحان پایگاه داده با گسترش شاردهای منطقی در چندین سرور، زمان خرابی را کاهش میدهند.
با این حال، شاردینگ یکی از چندین استراتژی دیگر مقیاسپذیری پایگاه داده است. برخی دیگر از تکنیکها را بررسی کنید و نحوه مقایسه آنها را درک کنید.
- مقیاسپذیری عمودی: مقیاسپذیری عمودی قدرت محاسباتی یک ماشین واحد را افزایش میدهد. به عنوان مثال، تیم IT یک CPU، RAM و یک هارد دیسک به یک سرور پایگاه داده اضافه میکند تا ترافیک رو به افزایش را مدیریت کند.
- مقایسه شاردینگ پایگاه داده و مقیاسپذیری عمودی: مقیاسپذیری عمودی هزینه کمتری دارد، اما محدودیتی برای منابع محاسباتی وجود دارد که میتوانید به صورت عمودی مقیاس دهید. در همین حال، شاردینگ، یک استراتژی مقیاسپذیری افقی، پیادهسازی آسانتری دارد. به عنوان مثال، تیم IT به جای ارتقاء سختافزار کامپیوتر قدیمی، چندین کامپیوتر نصب میکند.
- تکثیر: تکثیر تکنیکی است که نسخههای دقیقی از پایگاه داده ایجاد میکند و آنها را در کامپیوترهای مختلف ذخیره میکند. طراحان پایگاه داده از تکثیر برای طراحی یک سیستم مدیریت پایگاه داده رابطهای مقاوم در برابر خطا استفاده میکنند. هنگامی که یکی از کامپیوترهای میزبان پایگاه داده از کار میافتد، سایر نسخهها عملیاتی باقی میمانند. تکثیر یک عمل رایج در سیستمهای محاسباتی توزیع شده است.
- مقایسه شاردینگ پایگاه داده و تکثیر: شاردینگ پایگاه داده نسخههایی از اطلاعات مشابه ایجاد نمیکند. در عوض، یک پایگاه داده را به چند بخش تقسیم میکند و آنها را در کامپیوترهای مختلف ذخیره میکند. برخلاف تکثیر، شاردینگ پایگاه داده منجر به دسترسی بالا نمیشود. شاردینگ میتواند در ترکیب با تکثیر برای دستیابی به هر دو مقیاس و دسترسی بالا استفاده شود.
در برخی موارد، شاردینگ پایگاه داده ممکن است شامل تکثیر مجموعههای داده خاص باشد. به عنوان مثال، یک فروشگاه خرده فروشی که محصولاتی را به مشتریان ایالات متحده و اروپا میفروشد، ممکن است نسخههایی از جداول تبدیل اندازه را در شاردهای مختلف برای هر دو منطقه ذخیره کند. برنامه میتواند از نسخههای تکراری جدول تبدیل برای تبدیل اندازه اندازهگیری بدون دسترسی به سایر سرورهای پایگاه داده استفاده کند.
-
پارتیشنبندی: پارتیشنبندی فرآیند تقسیم یک جدول پایگاه داده به چند گروه است. پارتیشنبندی به دو نوع طبقهبندی میشود:
- پارتیشنبندی افقی پایگاه داده را بر اساس ردیفها تقسیم میکند.
- پارتیشنبندی عمودی پارتیشنهای مختلف ستونهای پایگاه داده را ایجاد میکند.
-
مقایسه شاردینگ پایگاه داده و پارتیشنبندی: شاردینگ پایگاه داده مانند پارتیشنبندی افقی است. هر دو فرآیند پایگاه داده را به چند گروه از ردیفهای منحصر به فرد تقسیم میکنند. پارتیشنبندی همه گروههای داده را در یک کامپیوتر ذخیره میکند، اما شاردینگ پایگاه داده آنها را در کامپیوترهای مختلف پخش میکند.
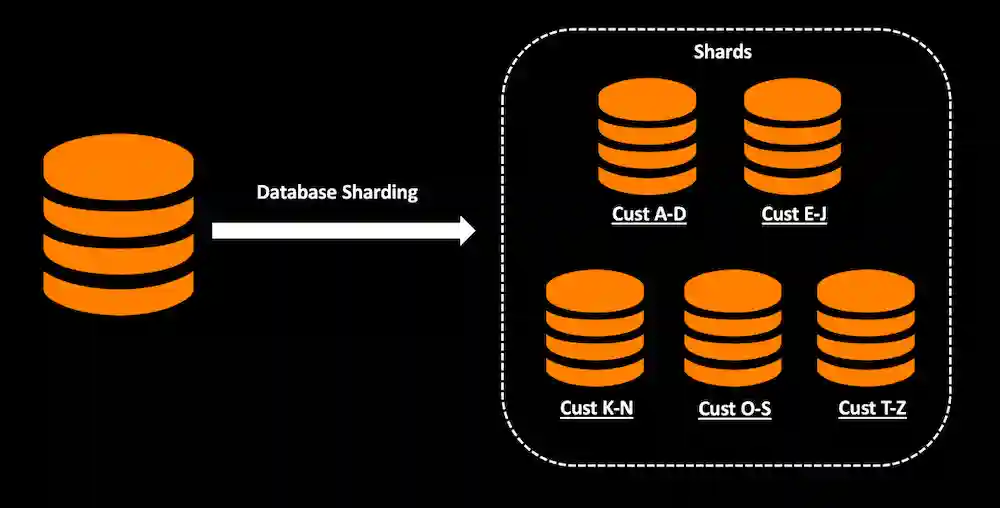
چالشهای شاردینگ پایگاه داده چیست؟
سازمانها ممکن است هنگام پیادهسازی شاردینگ پایگاه داده با این چالشها روبرو شوند:
-
نقاط داغ داده: برخی از شاردها به دلیل توزیع ناهموار دادهها نامتعادل میشوند. به عنوان مثال، یک شارد فیزیکی واحد که شامل نام مشتریانی است که با A شروع میشوند، دادههای بیشتری نسبت به سایرین دریافت میکند. این شارد فیزیکی از منابع محاسباتی بیشتری نسبت به سایرین استفاده میکند.
- راه حل: میتوانید با استفاده از کلیدهای شارد بهینه، دادهها را به طور مساوی توزیع کنید. برخی از مجموعههای داده برای شاردینگ مناسبتر از سایرین هستند.
-
پیچیدگی عملیاتی: شاردینگ پایگاه داده پیچیدگی عملیاتی ایجاد میکند. توسعهدهندگان به جای مدیریت یک پایگاه داده واحد، باید چندین گره پایگاه داده را مدیریت کنند. هنگامی که آنها در حال بازیابی اطلاعات هستند، توسعهدهندگان باید چندین شارد را پرس و جو کنند و قطعات اطلاعات را با هم ترکیب کنند. این عملیات بازیابی میتواند تجزیه و تحلیل را پیچیده کند.
- راه حل: در مجموعه پایگاه داده AWS، راهاندازی و عملیات پایگاه داده تا حد زیادی خودکار شده است. این امر کار با یک معماری پایگاه داده شارد شده را به یک کار سادهتر تبدیل میکند.
-
هزینههای زیرساخت: سازمانها هنگام اضافه کردن کامپیوترهای بیشتر به عنوان شاردهای فیزیکی، هزینه بیشتری برای هزینههای زیرساخت میپردازند. اگر تعداد ماشینها را در مرکز داده محلی خود افزایش دهید، هزینههای نگهداری میتواند افزایش یابد.
- راه حل: توسعهدهندگان از Amazon Elastic Compute Cloud (Amazon EC2) برای میزبانی و مقیاسبندی شاردها در فضای ابری استفاده میکنند. میتوانید با استفاده از زیرساخت مجازی که AWS به طور کامل آن را مدیریت میکند، در هزینهها صرفهجویی کنید.
-
پیچیدگی برنامه: اکثر سیستمهای مدیریت پایگاه داده دارای ویژگیهای داخلی شاردینگ نیستند. این بدان معناست که طراحان پایگاه داده و توسعهدهندگان نرمافزار باید پایگاه داده را به صورت دستی تقسیم، توزیع و مدیریت کنند.
- راه حل: میتوانید دادههای خود را به پایگاه دادههای مناسب AWS که دارای ویژگیهای داخلی متعددی هستند که از مقیاسپذیری افقی پشتیبانی میکنند، منتقل کنید.
سوالات متداول درباره شاردینگ پایگاه داده
شاردینگ پایگاه داده چیست؟
شاردینگ پایگاه داده تکنیکی است برای تقسیم و توزیع دادهها در بخشها یا “شارد”های جداگانه تا بار کاری روی یک سرور کاهش یابد و مقیاسپذیری افزایش پیدا کند.
شاردینگ چگونه کار میکند؟
در شاردینگ، دادهها بر اساس کلید مشخص (مثلاً شناسه کاربر) به چند پارتیشن مستقل تقسیم میشوند و هر بخش روی سرور یا نود جداگانه ذخیره و مدیریت میشود.
مزایای شاردینگ پایگاه داده چیست؟
شاردینگ باعث افزایش عملکرد، کاهش زمان پاسخ، مقیاسپذیری بهتر و توزیع بار پردازشی در سیستمهای با حجم داده زیاد میشود.