
رگرسیون لجستیک چیست؟
رگرسیون لجستیک یک تکنیک تحلیل داده است که از ریاضیات برای یافتن روابط بین دو عامل داده استفاده میکند. سپس از این رابطه برای پیشبینی مقدار یکی از آن عوامل بر اساس دیگری استفاده میکند. پیشبینی معمولاً تعداد محدودی از نتایج دارد، مانند بله یا خیر.برای مثال، فرض کنید میخواهید حدس بزنید که آیا بازدیدکننده وبسایت شما روی دکمه پرداخت در سبد خرید خود کلیک میکند یا خیر. تحلیل رگرسیون لجستیک، رفتار گذشته بازدیدکننده، مانند زمان صرف شده در وبسایت و تعداد موارد موجود در سبد خرید را بررسی میکند. مشخص میکند که در گذشته، اگر بازدیدکنندگان بیش از پنج دقیقه در سایت صرف میکردند و بیش از سه مورد به سبد خرید اضافه میکردند، روی دکمه پرداخت کلیک میکردند. با استفاده از این اطلاعات، تابع رگرسیون لجستیک میتواند رفتار یک بازدیدکننده جدید وبسایت را پیشبینی کند.
چرا رگرسیون لجستیک مهم است؟
رگرسیون لجستیک یک تکنیک مهم در زمینه هوش مصنوعی و یادگیری ماشین (AI/ML) است. مدلهای ML برنامههای نرمافزاری هستند که میتوانید آنها را برای انجام وظایف پیچیده پردازش داده بدون دخالت انسان آموزش دهید. مدلهای ML ساخته شده با استفاده از رگرسیون لجستیک به سازمانها کمک میکنند تا بینشهای عملی از دادههای تجاری خود به دست آورند. آنها میتوانند از این بینشها برای تحلیل پیشبینیکننده به منظور کاهش هزینههای عملیاتی، افزایش کارایی و مقیاس سریعتر استفاده کنند. برای مثال، کسبوکارها میتوانند الگوهایی را کشف کنند که منجر به بهبود حفظ کارکنان یا طراحی محصول سودآورتر میشوند.
در زیر، برخی از مزایای استفاده از رگرسیون لجستیک نسبت به سایر تکنیکهای ML را فهرست میکنیم.
سادگی: مدلهای رگرسیون لجستیک از نظر ریاضی پیچیدگی کمتری نسبت به سایر روشهای ML دارند. بنابراین، میتوانید آنها را حتی اگر هیچکس در تیم شما تخصص عمیق ML نداشته باشد، پیادهسازی کنید.
سرعت: مدلهای رگرسیون لجستیک میتوانند حجم زیادی از دادهها را با سرعت بالا پردازش کنند، زیرا به ظرفیت محاسباتی کمتری مانند حافظه و قدرت پردازش نیاز دارند. این امر آنها را برای سازمانهایی که پروژههای ML را شروع میکنند تا به برخی از موفقیتهای سریع دست یابند، ایدهآل میسازد.
انعطافپذیری: میتوانید از رگرسیون لجستیک برای یافتن پاسخ سؤالاتی که دو یا چند نتیجه محدود دارند، استفاده کنید. همچنین میتوانید از آن برای پیشپردازش دادهها استفاده کنید. برای مثال، میتوانید دادهها را با دامنه وسیعی از مقادیر، مانند تراکنشهای بانکی، با استفاده از رگرسیون لجستیک به دامنه کوچکتر و محدودی از مقادیر مرتب کنید. سپس میتوانید این مجموعه داده کوچکتر را با استفاده از سایر تکنیکهای ML برای تحلیل دقیقتر پردازش کنید.
قابلیت مشاهده: تحلیل رگرسیون لجستیک نسبت به سایر تکنیکهای تحلیل داده، دید بیشتری از فرآیندهای نرمافزاری داخلی به توسعهدهندگان میدهد. عیبیابی و تصحیح خطا نیز آسانتر است، زیرا محاسبات پیچیدگی کمتری دارند.
کاربردهای رگرسیون لجستیک چیست؟
رگرسیون لجستیک کاربردهای واقعی متعددی در صنایع مختلف دارد.
تولید: شرکتهای تولیدی از تحلیل رگرسیون لجستیک برای تخمین احتمال خرابی قطعات در ماشینآلات استفاده میکنند. سپس برنامههای تعمیر و نگهداری را بر اساس این تخمین برای به حداقل رساندن خرابیهای آینده برنامهریزی میکنند.
مراقبتهای بهداشتی: محققان پزشکی با پیشبینی احتمال بیماری در بیماران، مراقبتهای پیشگیرانه و درمان را برنامهریزی میکنند. آنها از مدلهای رگرسیون لجستیک برای مقایسه تأثیر سابقه خانوادگی یا ژنها بر بیماریها استفاده میکنند.
امور مالی: شرکتهای مالی باید تراکنشهای مالی را برای تقلب تجزیه و تحلیل کنند و درخواستهای وام و درخواستهای بیمه را از نظر ریسک ارزیابی کنند. این مشکلات برای یک مدل رگرسیون لجستیک مناسب هستند زیرا نتایج گسستهای دارند، مانند ریسک بالا یا ریسک پایین و جعلی یا غیر جعلی.
بازاریابی: ابزارهای تبلیغات آنلاین از مدل رگرسیون لجستیک برای پیشبینی اینکه آیا کاربران روی یک تبلیغ کلیک میکنند یا خیر، استفاده میکنند. در نتیجه، بازاریابان میتوانند پاسخهای کاربران به کلمات و تصاویر مختلف را تجزیه و تحلیل کنند و تبلیغات پربازدهی ایجاد کنند که مشتریان با آنها درگیر شوند.
تحلیل رگرسیون چگونه کار میکند؟
رگرسیون لجستیک یکی از چندین تکنیک مختلف تحلیل رگرسیون است که دانشمندان داده معمولاً در یادگیری ماشین (ML) از آن استفاده میکنند. برای درک رگرسیون لجستیک، ابتدا باید تحلیل رگرسیون پایه را درک کنیم. در زیر، از یک مثال از تحلیل رگرسیون خطی برای نشان دادن نحوه عملکرد تحلیل رگرسیون استفاده میکنیم.
سوال را مشخص کنید: هر تحلیل دادهای با یک سؤال تجاری شروع میشود. برای رگرسیون لجستیک، باید سؤال را به گونهای مطرح کنید که نتایج خاصی به دست آورید:
- آیا روزهای بارانی بر فروش ماهانه ما تأثیر دارند؟ (بله یا خیر)
- مشتری چه نوع فعالیت کارت اعتباری را انجام میدهد؟ (مجاز، جعلی یا احتمالاً جعلی)
دادههای تاریخی را جمعآوری کنید: پس از شناسایی سؤال، باید عوامل داده مرتبط را شناسایی کنید. سپس دادههای گذشته را برای همه عوامل جمعآوری خواهید کرد. برای مثال، برای پاسخ به سؤال اول نشان داده شده در بالا، میتوانید تعداد روزهای بارانی و دادههای فروش ماهانه خود را برای هر ماه در سه سال گذشته جمعآوری کنید.
مدل تحلیل رگرسیون را آموزش دهید: دادههای تاریخی را با استفاده از نرمافزار رگرسیون پردازش میکنید. نرمافزار نقاط داده مختلف را پردازش میکند و آنها را به صورت ریاضی با استفاده از معادلات به هم متصل میکند. برای مثال، اگر تعداد روزهای بارانی برای سه ماه ۳، ۵ و ۸ باشد و تعداد فروش در آن ماهها ۸، ۱۲ و ۱۸ باشد، الگوریتم رگرسیون عوامل را با معادله زیر مرتبط میکند:
تعداد فروش = 2 * (تعداد روزهای بارانی) + ۲
برای مقادیر ناشناخته پیشبینی کنید: برای مقادیر ناشناخته، نرمافزار از معادله برای پیشبینی استفاده میکند. اگر بدانید که شش روز در ماه جولای باران خواهد بارید، نرمافزار مقدار فروش جولای را ۱۴ تخمین میزند.
مدل رگرسیون لجستیک چگونه کار میکند؟
برای درک مدل رگرسیون لجستیک، ابتدا باید معادلات و متغیرها را درک کنیم.
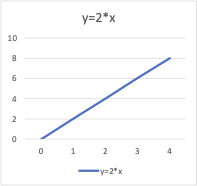
معادلات: در ریاضیات، معادلات رابطه بین دو متغیر x و y را نشان میدهند. میتوانید از این معادلات یا توابع برای رسم نمودار در امتداد محور x و محور y با قرار دادن مقادیر مختلف x و y استفاده کنید. برای مثال، اگر نمودار تابع y = 2 * x را رسم کنید، یک خط مستقیم مانند شکل زیر خواهید داشت. از این رو این تابع را تابع خطی نیز مینامند.
متغیرها: در آمار، متغیرها عوامل داده یا ویژگیهایی هستند که مقادیر آنها تغییر میکند. برای هر تحلیل، متغیرهای خاصی مستقل یا متغیرهای توضیحی هستند. این ویژگیها علت یک نتیجه هستند. متغیرهای دیگر وابسته یا متغیرهای پاسخ هستند. مقادیر آنها به متغیرهای مستقل بستگی دارد. به طور کلی، رگرسیون لجستیک بررسی میکند که چگونه متغیرهای مستقل با بررسی مقادیر دادههای تاریخی هر دو متغیر بر یک متغیر وابسته تأثیر میگذارند.
در مثال بالا، x متغیر مستقل، متغیر پیشبینیکننده یا متغیر توضیحی نامیده میشود زیرا مقدار شناخته شدهای دارد. Y متغیر وابسته، متغیر نتیجه یا متغیر پاسخ نامیده میشود زیرا مقدار آن ناشناخته است.
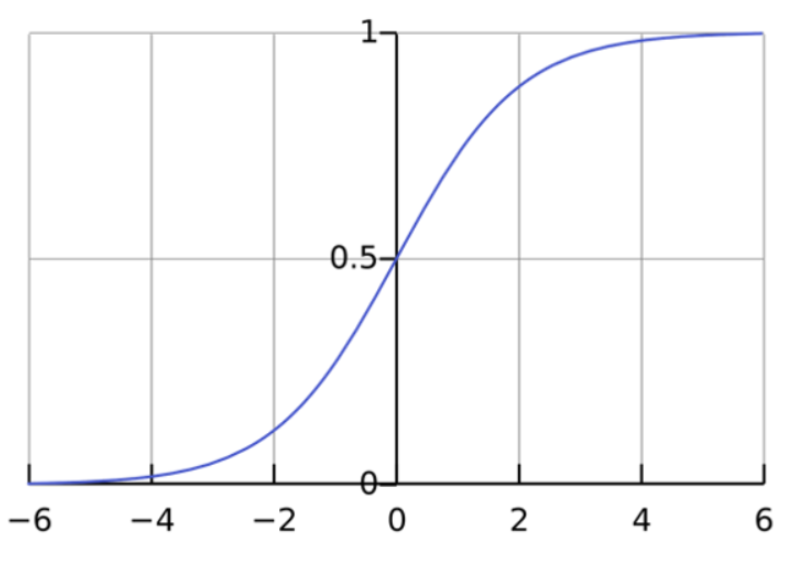
تابع رگرسیون لجستیک: رگرسیون لجستیک یک مدل آماری است که از تابع لجستیک یا تابع logit در ریاضیات به عنوان معادله بین x و y استفاده میکند. تابع logit، y را به عنوان یک تابع سیگموئید از x ترسیم میکند.
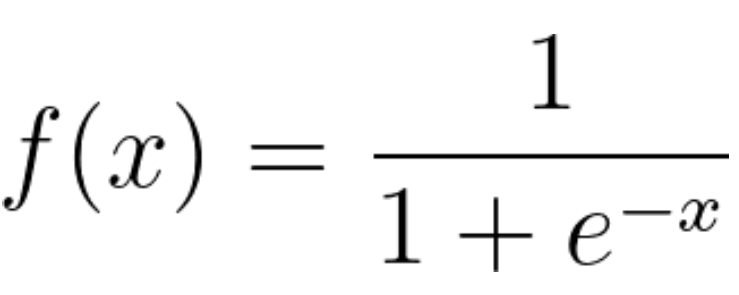
اگر این معادله رگرسیون لجستیک را رسم کنید، یک منحنی S شکل مانند شکل زیر خواهید داشت.
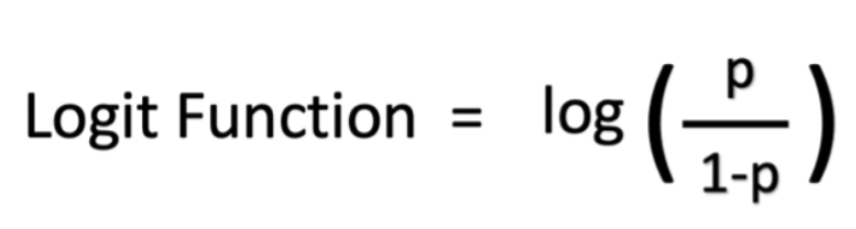
انواع تحلیل رگرسیون لجستیک چیست؟
سه رویکرد برای تحلیل رگرسیون لجستیک بر اساس نتایج متغیر وابسته وجود دارد.
رگرسیون لجستیک دودویی: رگرسیون لجستیک دودویی برای مسائل طبقهبندی دودویی که فقط دو نتیجه ممکن دارند، به خوبی کار میکند. متغیر وابسته فقط میتواند دو مقدار داشته باشد، مانند بله و خیر یا ۰ و ۱.
حتی اگر تابع لجستیک طیفی از مقادیر بین ۰ و ۱ را محاسبه کند، مدل رگرسیون دودویی پاسخ را به نزدیکترین مقادیر گرد میکند. به طور کلی، پاسخهای زیر ۰.۵ به ۰ گرد میشوند و پاسخهای بالای ۰.۵ به ۱ گرد میشوند، به طوری که تابع لجستیک یک نتیجه دودویی را برمیگرداند.
رگرسیون لجستیک چند جملهای: رگرسیون چند جملهای میتواند مشکلاتی را که چندین نتیجه ممکن دارند، تا زمانی که تعداد نتایج محدود باشد، تجزیه و تحلیل کند. برای مثال، میتواند پیشبینی کند که آیا قیمت خانه بر اساس دادههای جمعیت ۲۵٪، ۵۰٪، ۷۵٪ یا ۱۰۰٪ افزایش مییابد یا خیر، اما نمیتواند مقدار دقیق یک خانه را پیشبینی کند.
رگرسیون لجستیک چند جملهای با نگاشت مقادیر نتیجه به مقادیر مختلف بین ۰ و ۱ کار میکند. از آنجا که تابع لجستیک میتواند طیفی از دادههای پیوسته، مانند ۰.۱، ۰.۱۱، ۰.۱۲ و غیره را برگرداند، رگرسیون چند جملهای نیز خروجی را به نزدیکترین مقادیر ممکن گروهبندی میکند.
رگرسیون لجستیک ترتیبی: رگرسیون لجستیک ترتیبی یا مدل logit مرتب شده، نوع خاصی از رگرسیون چند جملهای برای مشکلاتی است که در آنها اعداد به جای مقادیر واقعی، رتبهها را نشان میدهند. برای مثال، از رگرسیون ترتیبی برای پیشبینی پاسخ به یک سؤال نظرسنجی استفاده میکنید که از مشتریان میخواهد خدمات شما را بر اساس یک مقدار عددی، مانند تعداد مواردی که در طول سال از شما خریداری میکنند، به عنوان ضعیف، منصفانه، خوب یا عالی رتبهبندی کنند.
رگرسیون لجستیک چگونه با سایر تکنیکهای ML مقایسه میشود؟
دو تکنیک رایج تحلیل داده، تحلیل رگرسیون خطی و یادگیری عمیق هستند.
تحلیل رگرسیون خطی: همانطور که در بالا توضیح داده شد، رگرسیون خطی رابطه بین متغیرهای وابسته و مستقل را با استفاده از یک ترکیب خطی مدل میکند. معادله رگرسیون خطی به صورت زیر است:
y= β0X0 + β1X1 + β2X2+… βnXn+ ε، که در آن β۱ تا βn و ε ضرایب رگرسیون هستند.
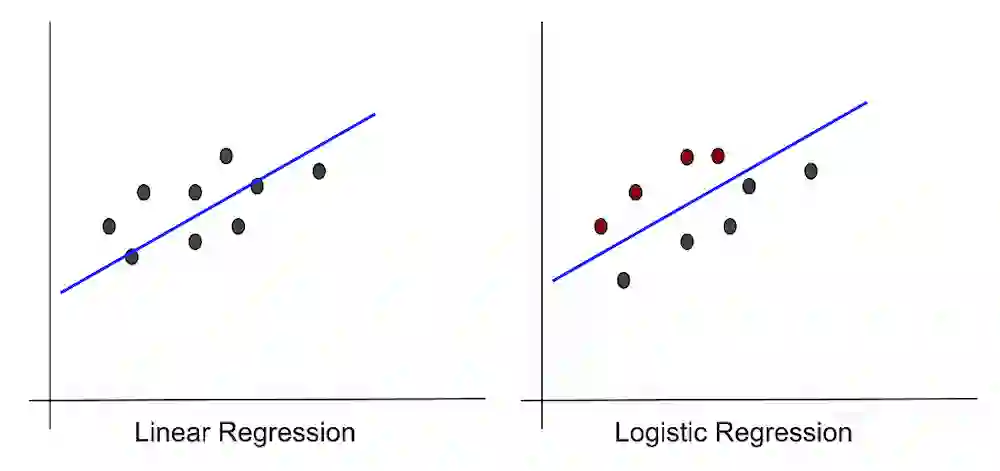
رگرسیون لجستیک در مقابل رگرسیون خطی: رگرسیون خطی یک متغیر وابسته پیوسته را با استفاده از مجموعه داده شدهای از متغیرهای مستقل پیشبینی میکند. یک متغیر پیوسته میتواند طیفی از مقادیر داشته باشد، مانند قیمت یا سن. بنابراین رگرسیون خطی میتواند مقادیر واقعی متغیر وابسته را پیشبینی کند. میتواند به سؤالاتی مانند “قیمت برنج بعد از ۱۰ سال چقدر خواهد بود؟” پاسخ دهد.
برخلاف رگرسیون خطی، رگرسیون لجستیک یک الگوریتم طبقهبندی است. نمیتواند مقادیر واقعی را برای دادههای پیوسته پیشبینی کند. میتواند به سؤالاتی مانند “آیا قیمت برنج در ۱۰ سال ۵۰ درصد افزایش مییابد؟” پاسخ دهد.
یادگیری عمیق: یادگیری عمیق از شبکههای عصبی یا اجزای نرمافزاری که مغز انسان را برای تجزیه و تحلیل اطلاعات شبیهسازی میکنند، استفاده میکند. محاسبات یادگیری عمیق بر اساس مفهوم ریاضی بردارها است.
رگرسیون لجستیک در مقابل یادگیری عمیق: رگرسیون لجستیک نسبت به یادگیری عمیق پیچیدگی و محاسبات کمتری دارد. مهمتر از آن، محاسبات یادگیری عمیق به دلیل ماهیت پیچیده و ماشین محور خود، نمیتوانند توسط توسعهدهندگان بررسی یا اصلاح شوند. از سوی دیگر، محاسبات رگرسیون لجستیک شفاف و عیبیابی آنها آسانتر است.
سوالات متداول درباره رگرسیون لجستیک
رگرسیون لجستیک چیست؟
رگرسیون لجستیک یک روش آماری و مدل یادگیری ماشین برای پیشبینی احتمال وقوع یک رویداد با دو یا چند دسته خروجی است که از تابع لجستیک (sigmoid) برای تبدیل خروجی به احتمال بین ۰ و ۱ استفاده میکند.
رگرسیون لجستیک چگونه کار میکند؟
این روش رابطه بین متغیرهای ورودی و خروجی دستهبندیشده (مثلاً بله/خیر) را مدل میکند و با استفاده از تابع سیگموئید، احتمال تعلق به یک گروه را محاسبه میکند.
کاربردهای رگرسیون لجستیک چیست؟
از رگرسیون لجستیک در طبقهبندی دودویی مانند پیشبینی خرید مشتری، تشخیص بیماری یا تشخیص اسپم استفاده میشود و در آمار، یادگیری ماشین و تحلیل داده کاربرد فراوان دارد.