
ترنسفورمرها نوعی معماری شبکه عصبی هستند که یک توالی ورودی را به توالی خروجی تبدیل یا تغییر میدهند. آنها این کار را با یادگیری زمینه و ردیابی روابط بین اجزای توالی انجام میدهند. برای مثال، توالی ورودی زیر را در نظر بگیرید: «رنگ آسمان چیست؟» مدل ترنسفورمر از یک نمایش ریاضی داخلی استفاده میکند که ارتباط و رابطه بین کلمات رنگ، آسمان و آبی را شناسایی میکند. آن از این دانش برای تولید خروجی استفاده میکند: «آسمان آبی است.»
سازمانها از مدلهای ترنسفورمر برای انواع تبدیلهای توالی استفاده میکنند، از تشخیص گفتار تا ترجمه ماشینی و تحلیل توالی پروتئین.
چرا ترنسفورمرها مهم هستند؟
مدلهای یادگیری عمیق اولیه که بر وظایف پردازش زبان طبیعی (NLP) تمرکز داشتند، هدفشان این بود که کامپیوترها زبان انسانی طبیعی را درک و پاسخ دهند. آنها کلمه بعدی در یک توالی را بر اساس کلمه قبلی حدس میزدند.
برای درک بهتر، ویژگی تکمیل خودکار در گوشی هوشمندتان را در نظر بگیرید. آن پیشنهادهایی بر اساس فراوانی جفتهای کلماتی که تایپ میکنید، ارائه میدهد. برای مثال، اگر اغلب «من خوبم» را تایپ کنید، گوشی پس از تایپ «am» کلمه «fine» را بهطور خودکار پیشنهاد میدهد.
مدلهای یادگیری ماشینی (ML) اولیه از فناوری مشابهی در مقیاس گستردهتری استفاده میکردند. آنها رابطه فراوانی بین جفتهای کلمات مختلف یا گروههای کلمات در مجموعه داده آموزشیشان را نگاشت میکردند و سعی میکردند کلمه بعدی را حدس بزنند. با این حال، فناوری اولیه نمیتوانست زمینه را فراتر از طول ورودی خاصی حفظ کند. برای مثال، یک مدل ML اولیه نمیتوانست پاراگراف معناداری تولید کند زیرا نمیتوانست زمینه بین جمله اول و آخر یک پاراگراف را حفظ کند. برای تولید خروجی مانند «من از ایتالیا هستم. من سوارکاری را دوست دارم. من ایتالیایی صحبت میکنم.»، مدل نیاز به بهخاطر سپردن ارتباط بین ایتالیا و ایتالیایی دارد، که شبکههای عصبی اولیه نمیتوانستند انجام دهند.
مدلهای ترنسفورمر فناوریهای NLP را بهطور اساسی تغییر دادند با امکانپذیر کردن مدلها برای مدیریت وابستگیهای بلندمدت در متن.
مزایای بیشتری از ترنسفورمرها در ادامه ذکر شده است.
-
امکانپذیر کردن مدلهای در مقیاس بزرگ
ترنسفورمرها توالیهای طولانی را بهطور کامل با محاسبات موازی پردازش میکنند، که زمانهای آموزش و پردازش را بهطور قابل توجهی کاهش میدهد. این امر آموزش مدلهای زبان بسیار بزرگ (LLM)، مانند GPT و BERT، را که میتوانند نمایشهای پیچیده زبان را یاد بگیرند، امکانپذیر کرده است. آنها میلیاردها پارامتر دارند که دامنه وسیعی از زبان و دانش انسانی را ثبت میکنند، و تحقیق را به سمت سیستمهای AI عمومیتر سوق میدهند.
-
امکانپذیر کردن سفارشیسازی سریعتر
با مدلهای ترنسفورمر، میتوانید از تکنیکهایی مانند یادگیری انتقال و تولید افزودهشده با بازیابی (RAG) استفاده کنید. این تکنیکها سفارشیسازی مدلهای موجود برای برنامههای خاص سازمانی را امکانپذیر میکنند. مدلها میتوانند روی مجموعه دادههای بزرگ پیشآموزش شوند و سپس روی مجموعه دادههای کوچکتر و خاص وظیفه تنظیم شوند. این رویکرد استفاده از مدلهای پیچیده را دموکراتیک کرده و محدودیتهای منابع در آموزش مدلهای بزرگ از صفر را حذف کرده است. مدلها میتوانند در چندین حوزه و وظیفه برای موارد استفاده مختلف عملکرد خوبی داشته باشند.
-
تسهیل سیستمهای AI چندوجهی
با ترنسفورمرها، میتوانید از AI برای وظایفی استفاده کنید که مجموعه دادههای پیچیده را ترکیب میکنند. برای مثال، مدلهایی مانند DALL-E نشان میدهند که ترنسفورمرها میتوانند تصاویر را از توصیفهای متنی تولید کنند و قابلیتهای NLP و بینایی کامپیوتری را ترکیب کنند. با ترنسفورمرها، میتوانید برنامههای AI ایجاد کنید که انواع اطلاعات مختلف را ادغام کنند و درک و خلاقیت انسانی را نزدیکتر تقلید کنند.
-
تحقیق AI و نوآوری صنعتی
ترنسفورمرها نسل جدیدی از فناوریهای AI و تحقیق AI ایجاد کردهاند و مرزهای آنچه در ML ممکن است را گسترش دادهاند. موفقیت آنها الهامبخش معماریها و برنامههای جدیدی شده است که مشکلات نوآورانه را حل میکنند. آنها ماشینها را قادر به درک و تولید زبان انسانی کردهاند، که منجر به برنامههایی میشود که تجربه مشتری را بهبود میبخشد و فرصتهای تجاری جدیدی ایجاد میکند.
موارد استفاده ترنسفورمرها چیست؟
میتوانید مدلهای ترنسفورمر بزرگ را روی هر داده توالی مانند زبانهای انسانی، ترکیبهای موسیقی، زبانهای برنامهنویسی و بیشتر آموزش دهید. موارد استفاده نمونه در ادامه ذکر شده است.
پردازش زبان طبیعی
ترنسفورمرها ماشینها را قادر به درک، تفسیر و تولید زبان انسانی به شیوهای دقیقتر از همیشه میکنند. آنها میتوانند اسناد بزرگ را خلاصه کنند و متن منسجم و زمینهدار مرتبط را برای انواع موارد استفاده تولید کنند. دستیارهای مجازی مانند الکسا از فناوری ترنسفورمر برای درک و پاسخ به دستورات صوتی استفاده میکنند.
ترجمه ماشینی
برنامههای ترجمه از ترنسفورمرها برای ارائه ترجمههای واقعیزمان و دقیق بین زبانها استفاده میکنند. ترنسفورمرها روانی و دقت ترجمهها را در مقایسه با فناوریهای قبلی بهطور قابل توجهی بهبود بخشیدهاند.
تحلیل توالی DNA
با درمان بخشهای DNA بهعنوان توالی مشابه زبان، ترنسفورمرها میتوانند اثرات جهشهای ژنتیکی را پیشبینی کنند، الگوهای ژنتیکی را درک کنند و به شناسایی مناطق DNA مسئول بیماریهای خاص کمک کنند. این قابلیت برای پزشکی شخصیسازیشده حیاتی است، جایی که درک ترکیب ژنتیکی فرد میتواند به درمانهای مؤثرتر منجر شود.
تحلیل ساختار پروتئین
مدلهای ترنسفورمر میتوانند دادههای توالی را پردازش کنند، که آنها را برای مدلسازی زنجیرههای طولانی اسیدهای آمینه که به ساختارهای پروتئینی پیچیده تا میشوند، مناسب میکند. درک ساختارهای پروتئینی برای کشف دارو و درک فرآیندهای بیولوژیکی حیاتی است. همچنین میتوانید از ترنسفورمرها در برنامههایی استفاده کنید که ساختار سهبعدی پروتئینها را بر اساس توالیهای اسید آمینهشان پیشبینی میکنند.
ترنسفورمرها چگونه کار میکنند؟
شبکههای عصبی از اوایل دهه ۲۰۰۰ روش پیشرو در وظایف مختلف AI مانند تشخیص تصویر و NLP بودهاند. آنها از لایههای گرههای محاسباتی متصل به هم، یا نورونها، تشکیل شدهاند که مغز انسانی را تقلید میکنند و با هم برای حل مشکلات پیچیده کار میکنند.
شبکههای عصبی سنتی که با دادههای توالی سروکار دارند، اغلب از الگوی معماری انکودر/دکودر استفاده میکنند. انکودر کل توالی داده ورودی، مانند یک جمله انگلیسی، را میخواند و پردازش میکند و آن را به یک نمایش ریاضی فشرده تبدیل میکند. این نمایش خلاصهای است که جوهر ورودی را ثبت میکند. سپس، دکودر این خلاصه را میگیرد و گام به گام توالی خروجی را تولید میکند، که میتواند همان جمله ترجمهشده به فرانسه باشد.
این فرآیند بهصورت توالی اتفاق میافتد، به این معنی که باید هر کلمه یا بخش از داده را یکی پس از دیگری پردازش کند. فرآیند کند است و میتواند جزئیات ظریفتری را در فواصل طولانی از دست بدهد.
مکانیسم خود-توجه
مدلهای ترنسفورمر این فرآیند را با گنجاندن چیزی به نام مکانیسم خود-توجه تغییر میدهند. به جای پردازش دادهها به ترتیب، این مکانیسم مدل را قادر میسازد تا به بخشهای مختلف توالی بهطور همزمان نگاه کند و تعیین کند که کدام بخشها مهمترین هستند.
تصور کنید در یک اتاق شلوغ هستید و سعی میکنید به صحبت کسی گوش دهید. مغزتان بهطور خودکار روی صدای او تمرکز میکند در حالی که صداهای کمتر مهم را نادیده میگیرد. خود-توجه مدل را قادر میسازد تا چیزی مشابه انجام دهد: آن به بخشهای مرتبط اطلاعات توجه بیشتری میکند و آنها را ترکیب میکند تا پیشبینیهای خروجی بهتری ایجاد کند. این مکانیسم ترنسفورمرها را کارآمدتر میکند و آنها را قادر به آموزش روی مجموعه دادههای بزرگتر میسازد. همچنین مؤثرتر است، بهویژه هنگام سروکار با قطعات طولانی متن که زمینه از عقب دور ممکن است بر معنای آنچه در ادامه میآید تأثیر بگذارد.
اجزای معماری ترنسفورمر چیست؟
معماری شبکه عصبی ترنسفورمر چندین لایه نرمافزاری دارد که با هم برای تولید خروجی نهایی کار میکنند. تصویر زیر اجزای معماری ترنسفورمر را نشان میدهد، همانطور که در بقیه این بخش توضیح داده شده است.
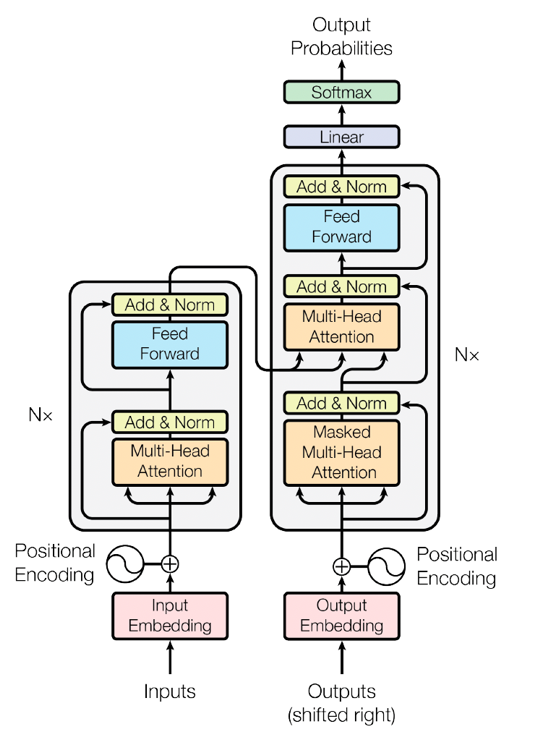
جاسازی ورودی
این مرحله توالی ورودی را به حوزه ریاضی که الگوریتمهای نرمافزاری درک میکنند، تبدیل میکند. ابتدا، توالی ورودی به سری توکنها یا اجزای توالی فردی تجزیه میشود. برای مثال، اگر ورودی یک جمله باشد، توکنها کلمات هستند. جاسازی سپس توالی توکن را به توالی بردار ریاضی تبدیل میکند. بردارها اطلاعات معنایی و نحوی را حمل میکنند، که بهعنوان اعداد نمایش داده میشوند، و ویژگیهای آنها در طول فرآیند آموزش یاد گرفته میشود.
میتوانید بردارها را بهعنوان سری مختصات در یک فضای n-بعدی تصور کنید. بهعنوان مثال ساده، به یک گراف دوبعدی فکر کنید، جایی که x مقدار الفبایی حرف اول کلمه را نشان میدهد و y دستهبندیهای آنها را. کلمه موز مقدار (۲,۲) دارد زیرا با حرف b شروع میشود و در دسته میوه است. کلمه انبه مقدار (۱۳,۲) دارد زیرا با حرف m شروع میشود و همچنین در دسته میوه است. به این ترتیب، بردار (x,y) به شبکه عصبی میگوید که کلمات موز و انبه در همان دسته هستند.
حالا یک فضای n-بعدی را با هزاران ویژگی در مورد دستور زبان، معنا و استفاده هر کلمه در جملات تصور کنید که به سری اعداد نگاشت شده است. نرمافزار میتواند از اعداد برای محاسبه روابط بین کلمات بهصورت ریاضی استفاده کند و مدل زبان انسانی را درک کند. جاسازیها راهی برای نمایش توکنهای گسسته بهعنوان بردارهای پیوسته فراهم میکنند که مدل میتواند پردازش و از آنها یاد بگیرد.
کدگذاری موقعیتی
کدگذاری موقعیتی جزء حیاتی در معماری ترنسفورمر است زیرا مدل خود بهطور ذاتی دادههای توالی را به ترتیب پردازش نمیکند. ترنسفورمر نیاز به راهی برای در نظر گرفتن ترتیب توکنها در توالی ورودی دارد. کدگذاری موقعیتی اطلاعات را به جاسازی هر توکن اضافه میکند تا موقعیت آن در توالی را نشان دهد. این کار اغلب با استفاده از مجموعهای از توابع انجام میشود که سیگنال موقعیتی منحصربهفرد تولید میکنند و به جاسازی هر توکن اضافه میشوند. با کدگذاری موقعیتی، مدل میتواند ترتیب توکنها را حفظ کند و زمینه توالی را درک کند.
بلوک ترنسفورمر
یک مدل ترنسفورمر معمولی چندین بلوک ترنسفورمر را روی هم انباشته دارد. هر بلوک ترنسفورمر دو جزء اصلی دارد: مکانیسم خود-توجه چندسر و شبکه عصبی پیشخور موقعیتمحور. مکانیسم خود-توجه مدل را قادر میسازد تا اهمیت توکنهای مختلف در توالی را وزندهی کند. آن روی بخشهای مرتبط ورودی هنگام ایجاد پیشبینیها تمرکز میکند.
برای مثال، جملات «دروغ نگو» و «او دراز میکشد.» را در نظر بگیرید. در هر دو جمله، معنای کلمه lies بدون نگاه به کلمات کنار آن قابل درک نیست. کلمات speak و down برای درک معنای صحیح ضروری هستند. خود-توجه گروهبندی توکنهای مرتبط برای زمینه را امکانپذیر میکند.
لایه پیشخور اجزای اضافی دارد که به مدل ترنسفورمر کمک میکند تا کارآمدتر آموزش ببیند و عمل کند. برای مثال، هر بلوک ترنسفورمر شامل موارد زیر است:
- اتصالاتی اطراف دو جزء اصلی که مانند میانبر عمل میکنند. آنها جریان اطلاعات از یک بخش شبکه به بخش دیگر را امکانپذیر میکنند و عملیات خاصی را در میان رد میکنند.
- نرمالسازی لایه که اعداد—بهطور خاص خروجیهای لایههای مختلف در شبکه—را در محدوده خاصی نگه میدارد تا مدل بهطور صاف آموزش ببیند.
- توابع تبدیل خطی تا مدل مقادیر را برای انجام بهتر وظیفهای که روی آن آموزش میبیند تنظیم کند—مانند خلاصه سند به جای ترجمه.
بلوکهای خطی و سافتمکس
در نهایت، مدل نیاز به ایجاد پیشبینی مشخصی دارد، مانند انتخاب کلمه بعدی در توالی. اینجا بلوک خطی وارد میشود. این یک لایه کاملاً متصل دیگر است، که بهعنوان لایه متراکم نیز شناخته میشود، قبل از مرحله نهایی. آن یک نگاشت خطی یادگرفتهشده از فضای بردار به حوزه ورودی اصلی انجام میدهد. این لایه حیاتی جایی است که بخش تصمیمگیری مدل نمایشهای داخلی پیچیده را میگیرد و آنها را به پیشبینیهای خاص برمیگرداند که میتوانید تفسیر و استفاده کنید. خروجی این لایه مجموعهای از امتیازها (اغلب بهعنوان logits نامیده میشود) برای هر توکن ممکن است.
تابع سافتمکس مرحله نهایی است که امتیازهای logit را میگیرد و آنها را به توزیع احتمال نرمالسازی میکند. هر عنصر خروجی سافتمکس اطمینان مدل را در مورد یک کلاس یا توکن خاص نشان میدهد.
ترنسفورمرها چگونه با سایر معماریهای شبکه عصبی متفاوت هستند؟
شبکههای عصبی بازگشتی (RNNها) و شبکههای عصبی کانولوشنی (CNNها) شبکههای عصبی دیگری هستند که اغلب در وظایف یادگیری ماشینی و یادگیری عمیق استفاده میشوند. در ادامه روابط آنها با ترنسفورمرها بررسی میشود.
ترنسفورمرها در مقابل RNNها
مدلهای ترنسفورمر و RNNها هر دو معماریهایی هستند که برای پردازش دادههای توالی استفاده میشوند.
RNNها توالیهای داده را یکی یکی در تکرارهای چرخهای پردازش میکنند. فرآیند با لایه ورودی که اولین عنصر توالی را دریافت میکند، شروع میشود. اطلاعات سپس به لایه پنهان منتقل میشود، که ورودی را پردازش میکند و خروجی را به گام زمانی بعدی منتقل میکند. این خروجی، همراه با عنصر بعدی توالی، به لایه پنهان بازخورد داده میشود. این چرخه برای هر عنصر در توالی تکرار میشود، با RNN که یک بردار حالت پنهان را حفظ میکند که در هر گام زمانی بهروزرسانی میشود. این فرآیند RNN را قادر میسازد تا اطلاعات از ورودیهای گذشته را بهخاطر بسپارد.
در مقابل، ترنسفورمرها کل توالیها را بهطور همزمان پردازش میکنند. این موازیسازی زمانهای آموزش بسیار سریعتری را امکانپذیر میکند و توانایی مدیریت توالیهای بسیار طولانیتر از RNNها را فراهم میکند. مکانیسم خود-توجه در ترنسفورمرها همچنین مدل را قادر میسازد تا کل توالی داده را بهطور همزمان در نظر بگیرد. این امر نیاز به بازگشت یا بردارهای پنهان را حذف میکند. در عوض، کدگذاری موقعیتی اطلاعات در مورد موقعیت هر عنصر در توالی را حفظ میکند.
ترنسفورمرها تا حد زیادی RNNها را در بسیاری از برنامهها، بهویژه در وظایف NLP، جایگزین کردهاند، زیرا میتوانند وابستگیهای بلندمدت را مؤثرتر مدیریت کنند. آنها همچنین مقیاسپذیری و کارایی بیشتری نسبت به RNNها دارند. RNNها هنوز در زمینههای خاصی مفید هستند، بهویژه جایی که اندازه مدل و کارایی محاسباتی مهمتر از ثبت تعاملات دور است.
ترنسفورمرها در مقابل CNNها
CNNها برای دادههای شبکهمانند، مانند تصاویر، طراحی شدهاند، جایی که سلسلهمراتبهای فضایی و محلی کلیدی هستند. آنها از لایههای کانولوشنی برای اعمال فیلترها روی ورودی استفاده میکنند و الگوهای محلی را از طریق این دیدگاههای فیلترشده ثبت میکنند. برای مثال، در پردازش تصویر، لایههای اولیه ممکن است لبهها یا بافتها را تشخیص دهند، و لایههای عمیقتر ساختارهای پیچیدهتری مانند اشکال یا اشیاء را بشناسند.
ترنسفورمرها عمدتاً برای مدیریت دادههای توالی طراحی شده بودند و نمیتوانستند تصاویر را پردازش کنند. مدلهای ترنسفورمر بینایی اکنون تصاویر را با تبدیل آنها به فرمت توالی پردازش میکنند. با این حال، CNNها همچنان انتخابی بسیار مؤثر و کارآمد برای بسیاری از برنامههای عملی بینایی کامپیوتری باقی میمانند.
انواع مختلف مدلهای ترنسفورمر چیست؟
ترنسفورمرها به خانوادهای متنوع از معماریها تکامل یافتهاند. انواع مدلهای ترنسفورمر در ادامه ذکر شده است.
ترنسفورمرهای دوجهته
مدلهای نمایشهای انکودر دوجهته از ترنسفورمرها (BERT) معماری پایه را تغییر میدهند تا کلمات را در رابطه با تمام کلمات دیگر در جمله پردازش کنند نه بهصورت ایزوله. از نظر فنی، از مکانیسمی به نام مدل زبان ماسکشده دوجهته (MLM) استفاده میکند. در طول پیشآموزش، BERT بهطور تصادفی درصدی از توکنهای ورودی را ماسک میکند و این توکنهای ماسکشده را بر اساس زمینهشان پیشبینی میکند. جنبه دوجهته از این واقعیت ناشی میشود که BERT هر دو توالی توکن چپ به راست و راست به چپ را در هر دو لایه در نظر میگیرد برای درک بیشتر.
ترنسفورمرهای پیشآموزششده generative
مدلهای GPT از دکودرهای ترنسفورمر انباشتهشده استفاده میکنند که روی مجموعه بزرگی از متن با استفاده از اهداف مدلسازی زبان پیشآموزش میشوند. آنها autoregressive هستند، به این معنی که مقدار بعدی در توالی را بر اساس تمام مقادیر پیشین رگرسیون یا پیشبینی میکنند. با استفاده از بیش از ۱۷۵ میلیارد پارامتر، مدلهای GPT میتوانند توالیهای متنی تولید کنند که برای سبک و لحن تنظیم شدهاند. مدلهای GPT تحقیق در AI را به سمت دستیابی به هوش عمومی مصنوعی سوق دادهاند. این به معنی آن است که سازمانها میتوانند سطوح جدیدی از بهرهوری را در حالی که برنامهها و تجربیات مشتریشان را بازسازی میکنند، برسند.
ترنسفورمرهای دوجهته و autoregressive
یک ترنسفورمر دوجهته و autoregressive (BART) نوعی مدل ترنسفورمر است که خواص دوجهته و autoregressive را ترکیب میکند. آن مانند ترکیبی از انکودر دوجهته BERT و دکودر autoregressive GPT است. کل توالی ورودی را بهطور همزمان میخواند و مانند BERT دوجهته است. با این حال، توالی خروجی را یکی یکی توکن به توکن تولید میکند، مشروط به توکنهای تولیدشده قبلی و ورودی ارائهشده توسط انکودر.
ترنسفورمرها برای وظایف چندوجهی
مدلهای ترنسفورمر چندوجهی مانند ViLBERT و VisualBERT برای مدیریت انواع متعدد دادههای ورودی، معمولاً متن و تصاویر، طراحی شدهاند. آنها معماری ترنسفورمر را با استفاده از شبکههای دوجریانی گسترش میدهند که ورودیهای بصری و متنی را جداگانه پردازش میکنند قبل از ادغام اطلاعات. این طراحی مدل را قادر به یادگیری نمایشهای بینمدلی میسازد. برای مثال، ViLBERT از لایههای ترنسفورمر همتوجهی برای امکان تعامل جریانهای جداگانه استفاده میکند. این برای موقعیتهایی حیاتی است که درک رابطه بین متن و تصاویر کلیدی است، مانند وظایف پاسخدهی به سؤالات بصری.
ترنسفورمرهای بینایی
ترنسفورمرهای بینایی (ViT) معماری ترنسفورمر را برای وظایف طبقهبندی تصویر بازاستفاده میکنند. به جای پردازش تصویر بهعنوان شبکهای از پیکسلها، دادههای تصویر را بهعنوان توالی پچهای اندازه ثابت، مشابه نحوه درمان کلمات در جمله، مشاهده میکنند. هر پچ صاف میشود، بهصورت خطی جاسازی میشود، و سپس بهصورت توالی توسط انکودر ترنسفورمر استاندارد پردازش میشود. جاسازیهای موقعیتی برای حفظ اطلاعات فضایی اضافه میشوند. این استفاده از خود-توجه جهانی مدل را قادر میسازد تا روابط بین هر جفت پچ را، صرفنظر از موقعیتشان، ثبت کند.