
متخصصان داده که سیستمهای پردازش زبان طبیعی سازمانی را مدیریت میکنند با گلوگاه حیاتی روبرو هستند: رویکردهای جاسازی سنتی بودجههای محاسباتی بیش از ۳۰۰٬۰۰۰ دلار در سال مصرف میکنند در حالی که درک معنایی ناسازگار در زمینههای خاص دامنه ارائه میدهند. این چالش زمانی شدت میگیرد که اصطلاحات چندمعنایی مانند “cell” بردارهای یکسانی تولید میکنند چه در تحقیقات زیستشناختی ظاهر شوند و چه در مستندات مخابراتی، که باعث میشود ۴۲ درصد سازمانها علیرغم سرمایهگذاریهای قابل توجه با عملیاتی کردن راهحلهای هوش مصنوعی مبارزه کنند. جاسازیهای جمله و کلمه مدرن برای رفع این نقاط درد از طریق آگاهی زمینهای و بهینهسازی تنظیمشده با دستورالعمل تکامل یافتهاند، و نحوه پردازش معنایی زبان انسانی توسط ماشینها را تحول میبخشند. جاسازیهای جمله و کلمه به عنوان پایه ریاضی عمل میکنند که مدلهای زبان بزرگ را قادر میسازند روابط معنایی را درک کنند، سیستمهای تولید تقویتشده با بازیابی را قدرت ببخشند، و کاربردهای طبقهبندی متن، تشخیص موجودیت نامدار، و پردازش اطلاعات چندزبانه را هدایت کنند. این تحلیل جامع معماریهای فنی، کاربردهای عملی، و استراتژیهای پیادهسازی را که سیستمهای جاسازی مدرن را تعریف میکنند کاوش میکند، و مفاهیم پایه و پیشرفتهای پیشرفته را که گردش کارهای پردازش زبان طبیعی معاصر را شکل میدهند بررسی میکند.
جاسازی کلمات چیست و چگونه کار میکند؟
جاسازی کلمه تکنیک اساسی را نمایان میکند که کلمات را به بردارهای عددی متراکم در فضای ابعاد بالا تبدیل میکند، جایی که روابط هندسی شباهتهای معنایی بین اصطلاحات مربوطه را بازتاب میدهند. بر خلاف روشهای کدگذاری یک-داغ پراکنده که کلمات را به عنوان نمادهای ایزوله عمل میکنند، جاسازیها معنایی توزیعشده را بر اساس اصل که کلماتی که در زمینههای مشابه ظاهر میشوند تمایل به معانی مرتبط دارند، ضبط میکنند.
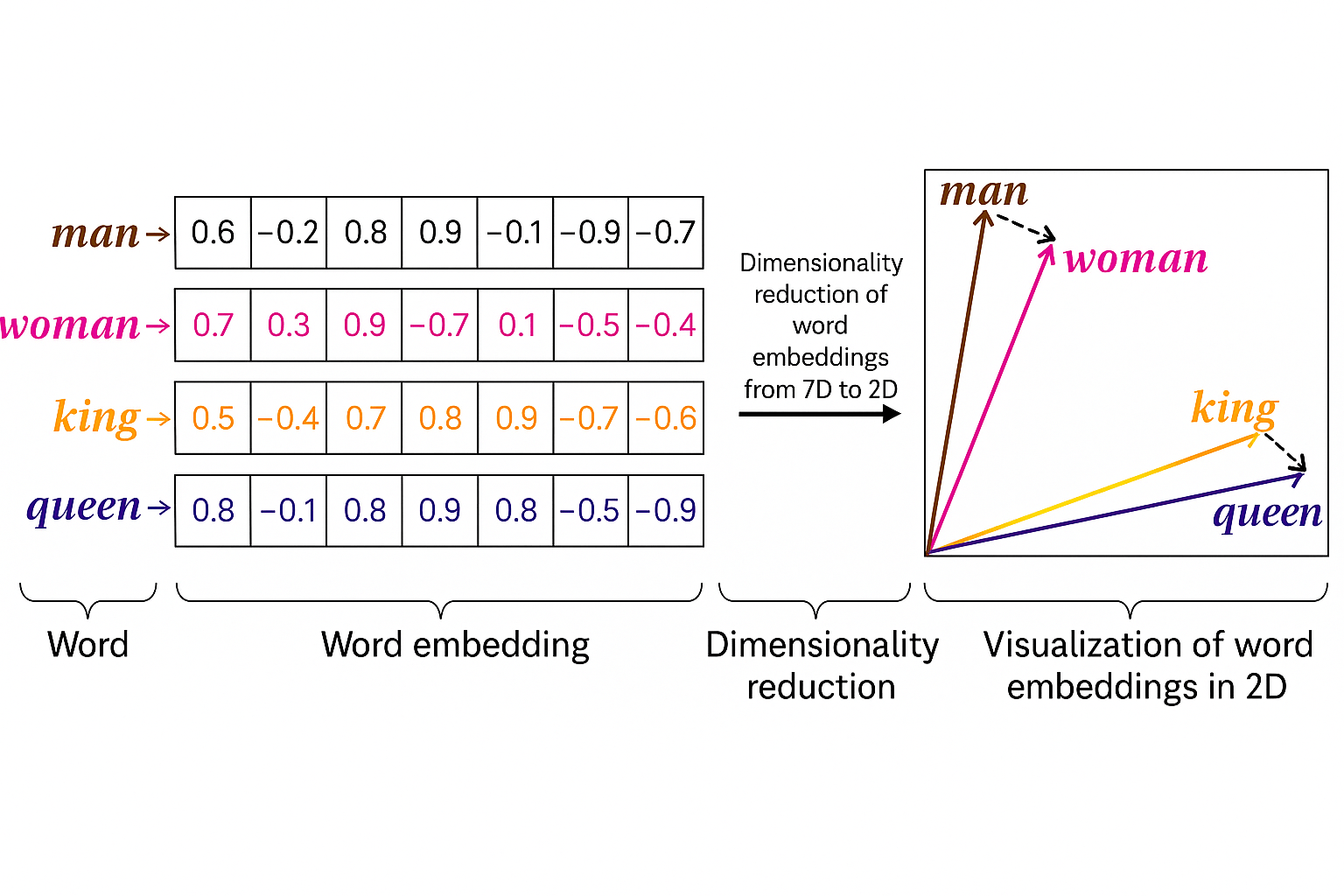
مدل کلمات مرتبط معنایی مانند “king” و “queen” یا “man” و “woman” را در مکانهای برداری مجاور قرار میدهد. این ترتیب هندسی عملیات حسابی برداری را امکانپذیر میسازد که روابط زبانی جذاب را آشکار میکند: vector(“king”) – vector(“man”) ≈ vector(“queen”) – vector(“woman”) جاسازیهای زمینهای مدرن رویکردهای ثابت را با تولید نمایندگیهای پویا که بر اساس زمینه متن اطراف تنظیم میشوند، جایگزین کردهاند. در حالی که Word2Vec و GloVe بردارهای ثابت بدون توجه به زمینه استفاده اختصاص میدهند، مدلهای معاصر مانند BERT و RoBERTa جاسازیهای منحصربهفرد برای کلمات یکسان که در محیطهای معنایی متفاوت ظاهر میشوند تولید میکنند، و چالشهای چندمعنایی را که معماریهای قبلی را آزار میدادند حل میکنند.
جاسازی جملات چیست و چگونه از جاسازی کلمات متفاوت است؟
جاسازی جملات پارادایم نمایندگی برداری را از کلمات فردی به واحدهای متنی کامل گسترش میدهد، و جملات کامل، پاراگرافها، یا اسناد را به بردارهای متراکم کدگذاری میکند که معنای معنایی و روابط زمینهای را حفظ میکنند. این رویکرد ماشینها را قادر میسازد متن را در سطوح بالاتر از دانهبندی درک کنند، و کاربردهایی مانند مقایسه شباهت اسناد، جستجوی معنایی، و خوشهبندی محتوا را که نیاز به درک کلی به جای تحلیل سطح کلمه دارند، پشتیبانی میکند.
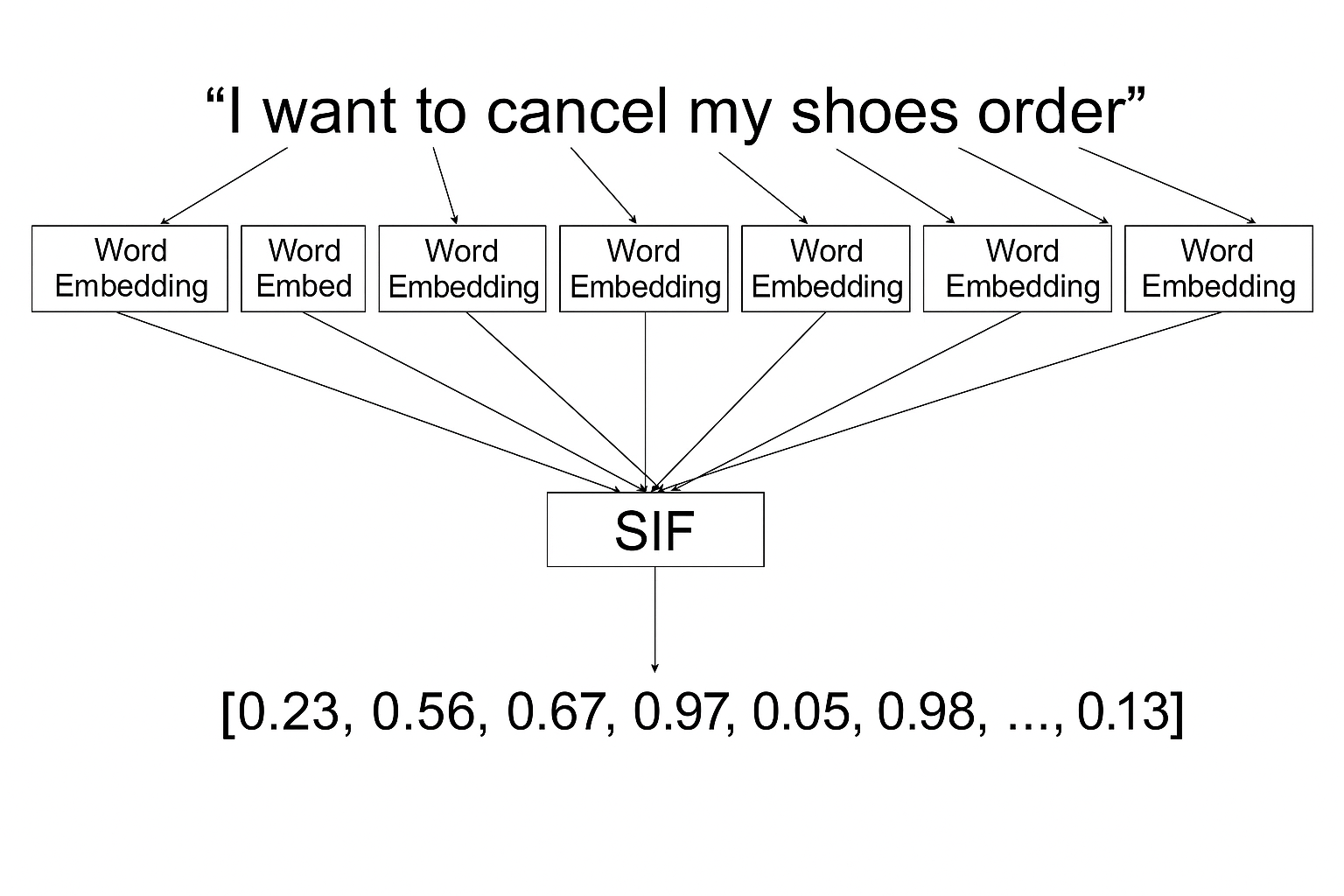
تفاوت اساسی بین جاسازی جمله در مقابل جاسازی کلمه در دامنه و ادغام زمینهای آنها نهفته است. جاسازی کلمات بر واحدهای واژگانی فردی و خواص توزیعشده آنها تمرکز میکنند، در حالی که جاسازی جملات معنای ترکیبی را که از ترکیب کلمات، ساختارهای نحوی، و وابستگیهای زمینهای پدیدار میشود ضبط میکنند. روششناسیهای محبوب شامل Universal Sentence Encoder (USE)، Sentence-BERT، Sentence Implicit Frequency (SIF)، و مدل CNN-non-static است، که دقت طبقهبندی سوالات TREC را از ۹۵ درصد به ۹۸.۶ درصد با ضبط الگوهای معنایی سطح جمله که بردارهای کلمه فردی نمیتوانند نمایندگی کنند، افزایش داد.
جاسازیهای جمله چندزبانه چگونه درک بینزبانی را امکانپذیر میکنند؟
جاسازیهای چندزبانه فضاهای برداری یکپارچه ایجاد میکنند جایی که جملات معادل معنایی از زبانهای مختلف موقعیتهای هندسی مشابهی اشغال میکنند، و کاربردهای بینزبانی را بدون نیاز به ترجمه موازی امکانپذیر میسازند.
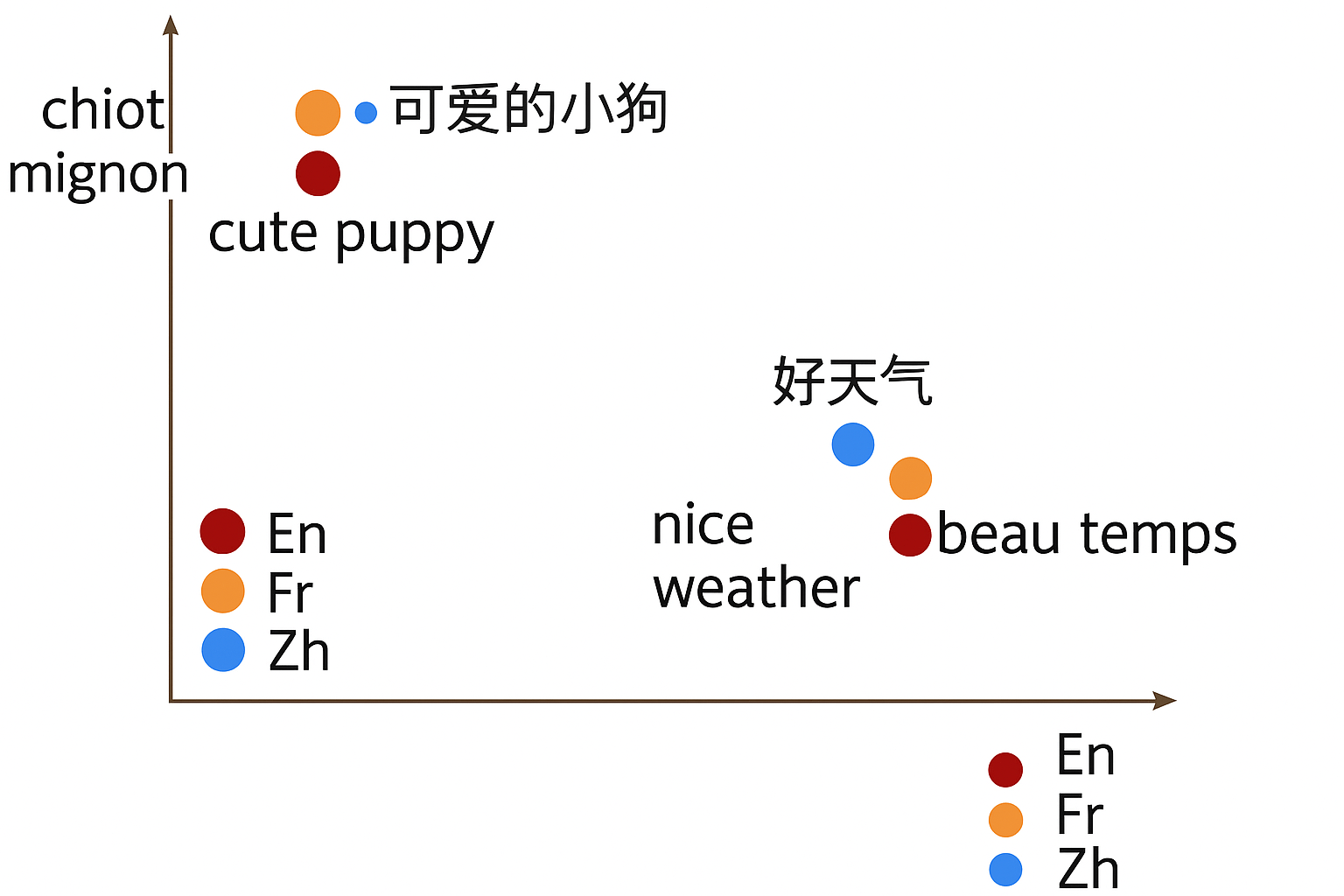
مدلسازی زبان ترجمه (TLM) پیشآموزش زبان ماسکشده را به زمینههای چندزبانه گسترش میدهد. رویکردهای مدرن مانند LASER و XLM-R از آموزش مقابلهای و توجه بینزبانی برای همتراز کردن معنایی در زبانها با ساختارهای نحوی و واژگان متفاوت استفاده میکنند. این سیستمها طبقهبندی صفر-شات، بازیابی اطلاعات چندزبانه، و جاسازیهای تنظیمشده با دستورالعمل را که راهنمایی خاص وظیفه را برای عملکرد بهتر در زمینههای زبانی و فرهنگی متنوع ادغام میکنند، قدرت میبخشند.
کاربردهای کلیدی واقعی جاسازی کلمات چیست؟
طبقهبندی متن
جاسازیها ویژگیهای غنی معنایی به طبقهبندها میدهند، و تشخیص اسپم، تحلیل احساسات، و دستهبندی موضوع را تقویت میکنند.
تشخیص موجودیت نامدار (NER)

بردارهای زمینهای موجودیتهایی که فرمهای سطحی یکسان به اشتراک میگذارند را ابهامزدایی میکنند (مثلاً “Apple” شرکت در مقابل میوه).
ترجمه ماشین
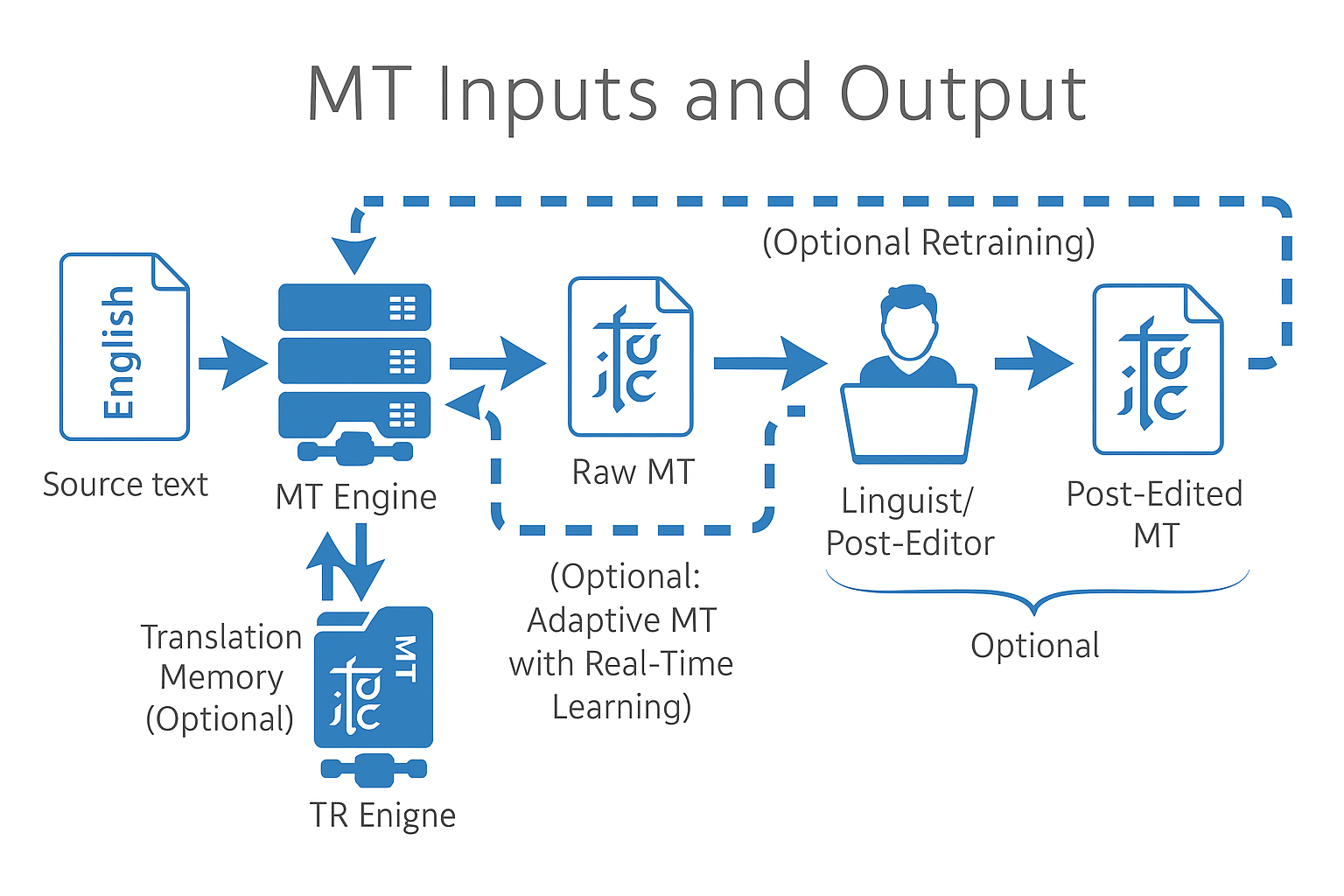
بردارهای چندزبانه پیشآموزششده (مثلاً fastText) ترجمه ماشین عصبی را زیربنایی میکنند، و سناریوهای صفر-شات و کممنبع را امکانپذیر میسازند.
پاسخ به سوالات
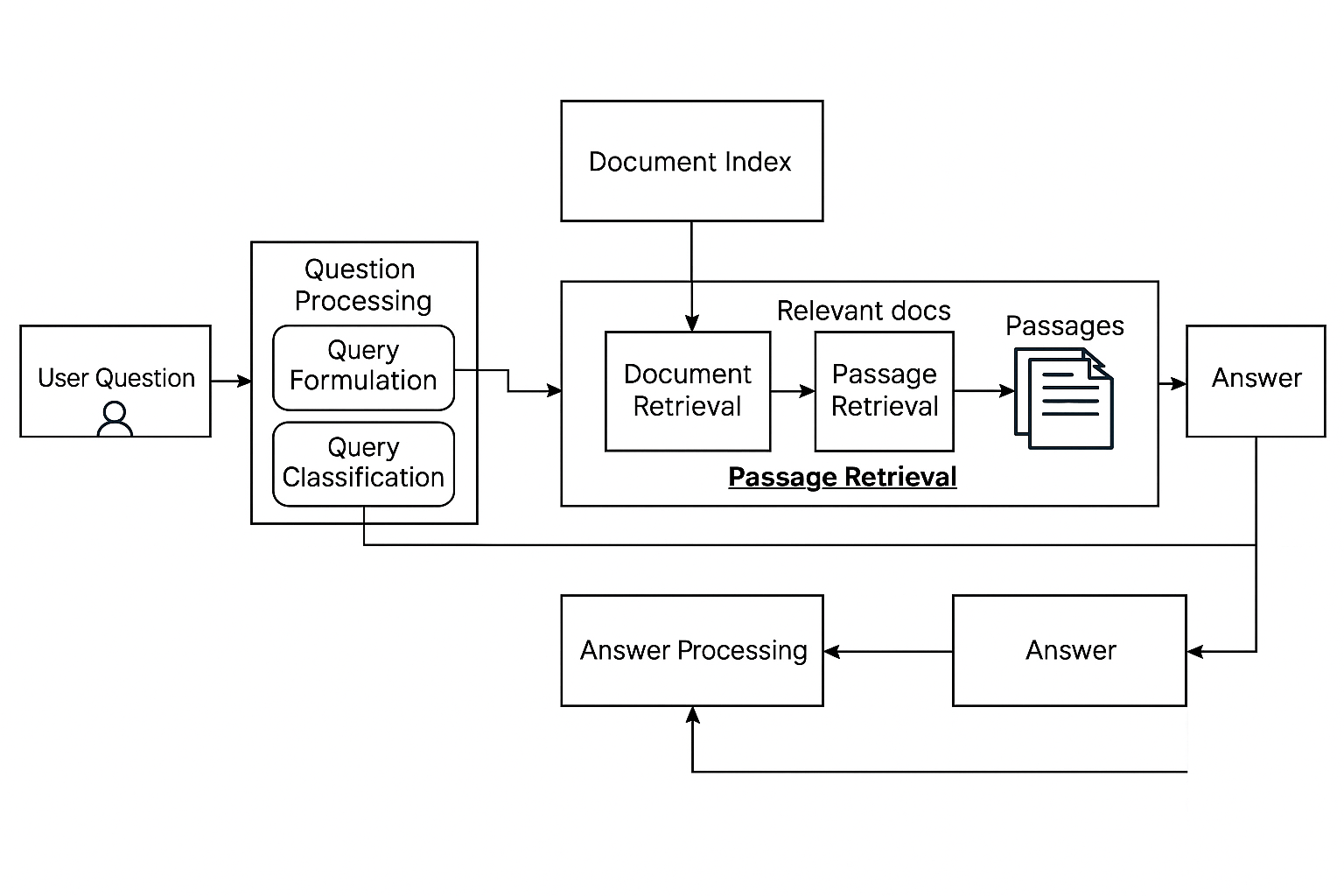
مدلهای زبان بزرگ جاسازیها را برای سوالات و پاسخهای کاندید مقایسه میکنند تا مرتبطترین زمینه را برای تولید بازیابی کنند.
بازیابی اطلاعات
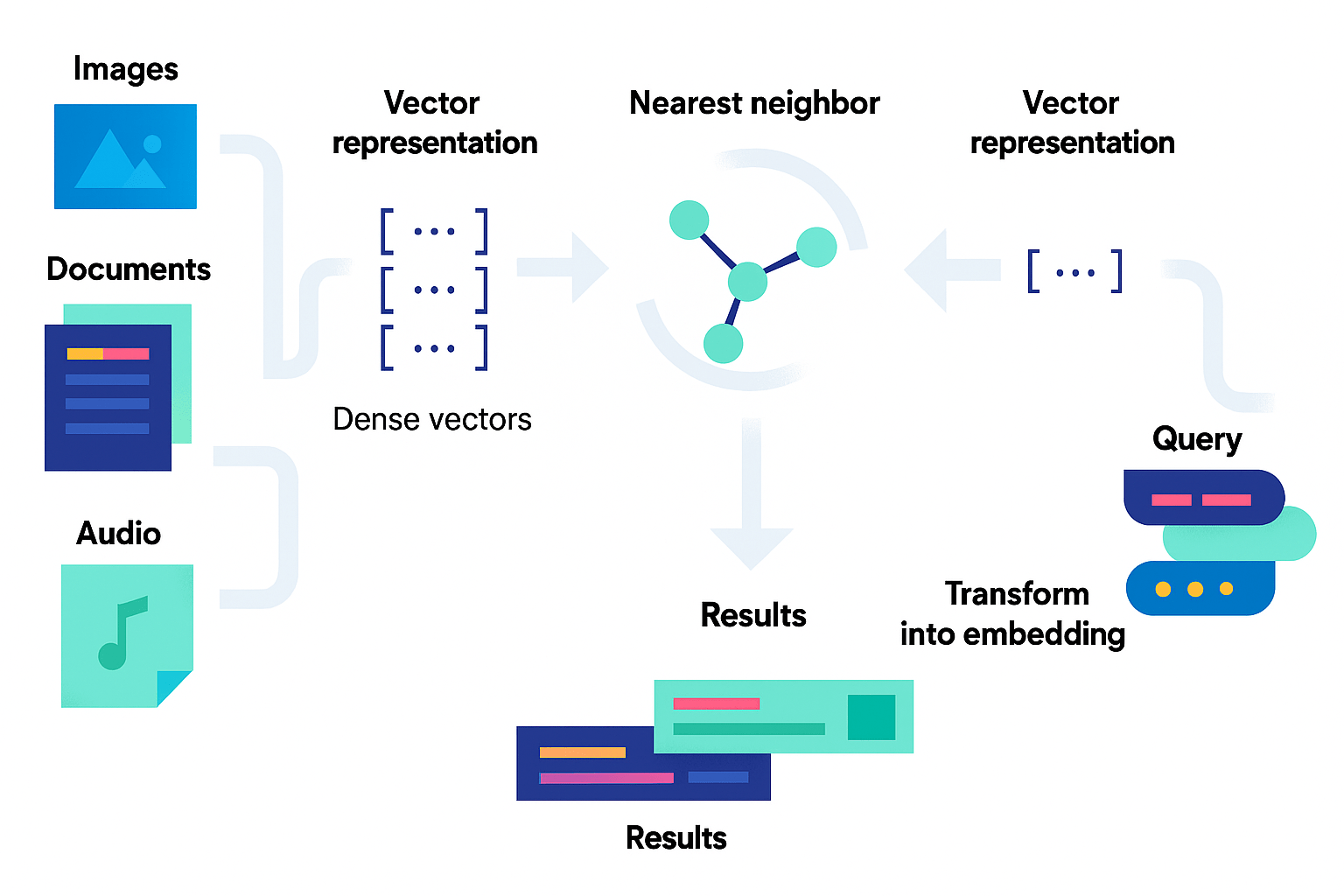
پرسشها و اسناد به فضای مشترک جاسازی میشوند؛ معیارهای شباهت (مثلاً cosine) نتایج را فراتر از همپوشانی ساده کلمات کلیدی رتبهبندی میکنند.
جاسازی کلمات در طول تاریخ چگونه تکامل یافتهاند؟
- ۲۰۰۳ – مدلهای زبان عصبی پیشخور (Bengio et al.)
- ۲۰۰۹ – مدلهای احتمالی (Mnih & Hinton)
- ۲۰۱۳ – Word2Vec (Skip-gram & CBOW)
- ۲۰۱۴ – GloVe (جهانی + زمینه محلی)
- ۲۰۱۷-۲۰۱۸ – انقلاب ترانسفورمر
- ۲۰۱۸-۲۰۱۹ – جاسازیهای زمینهای BERT و GPT
- ۲۰۲۰-۲۰۲۴ – جاسازیهای تنظیمشده با دستورالعمل
- ۲۰۲۴-۲۰۲۵ – ادغام چندوجهی
این مسیر نشاندهنده تغییر از بردارهای سطح کلمه ثابت به سیستمهای پویا و آگاه از زمینه که زبانها و وجوه را در بر میگیرند است.
جاسازی کلمات چگونه ایجاد و آموزش داده میشوند؟
معماری Word2Vec
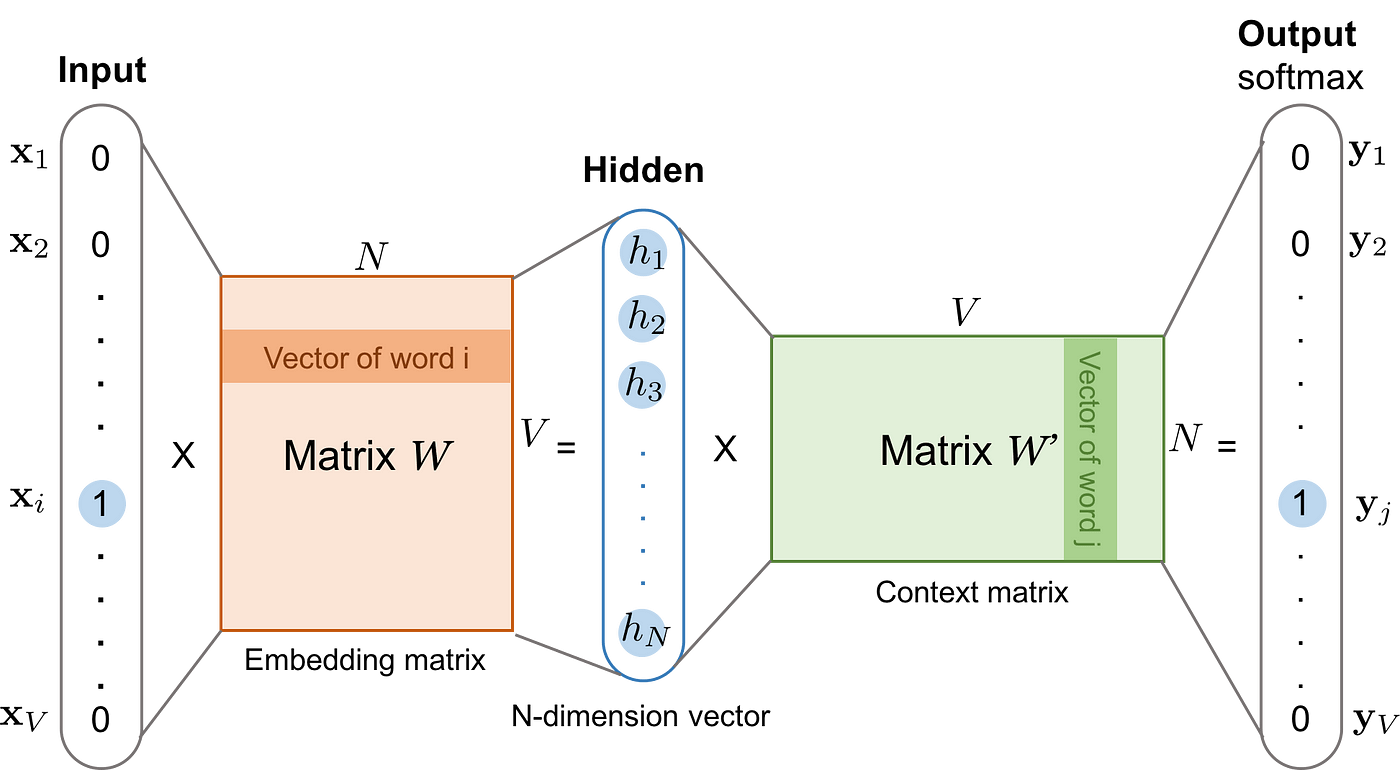
CBOW کلمات هدف را از زمینه پیشبینی میکند؛ Skip-gram زمینه را از یک کلمه هدف پیشبینی میکند، و بردارها را از طریق پسانتشار با softmax سلسلهمراتبی یا نمونهبرداری منفی یاد میگیرد.
BERT و جاسازیهای زمینهای
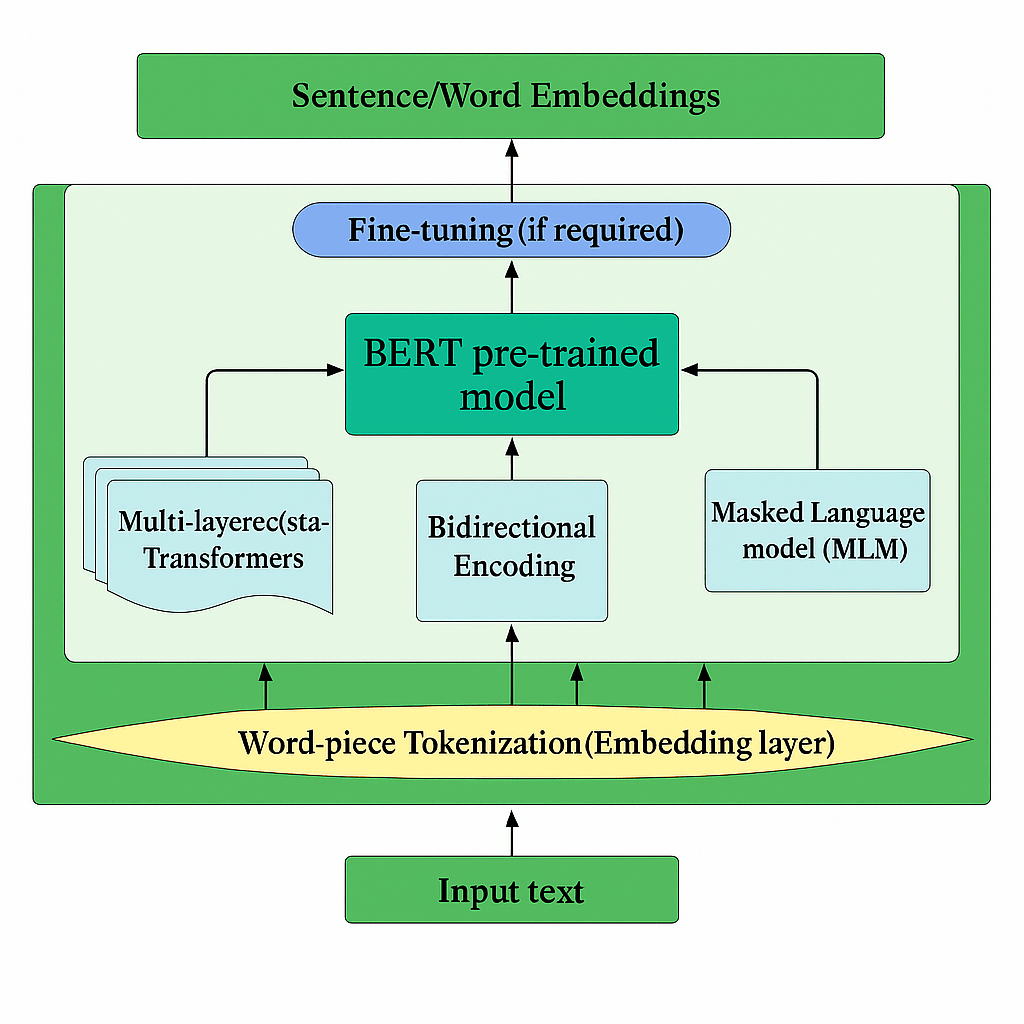
مدلسازی زبان ماسکشده BERT جاسازیهای توکن را شرطی بر زمینه دوطرفه کامل تولید میکند. گسترشهایی مانند BERT-flow امتیازات شباهت را کالیبره میکنند، و معیارهای شباهت معنایی را تقویت میکنند. مدلهای تنظیمشده با دستورالعمل معاصر (مثلاً E5-mistral-7b-instruct) جاسازیهایی تولید میکنند که برای وظایف مشخص مانند “شباهت سند حقوقی” بهینهسازی شدهاند.
تکنیکهای بهینهسازی جاسازی پیشرفته چگونه عملکرد را بهبود میبخشند؟
- تولید تنظیمشده با دستورالعمل – راهنمایی خاص وظیفه دقت دامنه را تا ۳۸ درصد بهبود میبخشد.
- فشردهسازی و کارایی – کوانتیزاسیون باینری، یادگیری نمایندگی Matryoshka، و فشردهسازی کنترلشده با دما ذخیرهسازی را کاهش میدهند در حالی که ~۹۵ درصد دقت را حفظ میکنند.
- جاسازیهای اسناد زمینهای (CDE) – زمینه بیناسنادی را ادغام میکنند، و عملکرد بازیابی را ۱۷ درصد افزایش میدهند.
- پارادایمهای بدون آموزش – روشهایی مانند GenEOL از پرامپتینگ مدل زبان بزرگ برای ساخت جاسازیهای باکیفیت بدون تنظیم دقیق استفاده میکنند.
روشهایی برای ارزیابی عملکرد جاسازی و بهترین شیوهها وجود دارد؟
معیارهای استانداردشده
معیار جاسازی متن عظیم (MTEB) ۵۶ مجموعه داده را در هشت دسته وظیفه ارزیابی میکند؛ MMTEB به ۱۱۲ زبان گسترش مییابد.
معیارهای ذاتی
همبستگیهای شباهت معنایی (STS-B)، امتیازات silhouette خوشهبندی، و همترازی یکنواختی هندسه فضای برداری را تحلیل میکنند.
معیارهای عملیاتی
تأخیر، ردپای حافظه، توان عملیاتی، و مدیریت نسخه جاسازی آمادگی تولید را حاکم میکنند.
اعتبارسنجی خاص دامنه
کیفیت پاسخ RAG، انتقال بینزبانی، و ممیزیهای عملکرد همتراز با کاربرد را اطمینان میدهند.
بهترین شیوهها
- تنظیم دقیق دامنه با دادههای مصنوعی → ۲۲ درصد سود.
- کالیبراسیون ابعادی (PCA/هرس) → ۴۰ درصد کوچکتر، ۹۷ درصد دقت حفظشده.
- مهندسی پرامپت برای بازیابی → ۳۱ درصد افزایش relevance.
- اعتبارسنجی صفر-شات مداوم در برابر نشت داده محافظت میکند.
نقش TF-IDF در جاسازی کلمات مدرن چیست؟
TF-IDF همچنان برای تحلیل corpus، انتخاب واژگان، و مهندسی ویژگی هیبریدی ارزشمند است. کتابخانههایی مانند Scikit-learn، SpaCy، NLTK، و Gensim پیادهسازیهای بهینهشده ارائه میدهند که رویکردهای عصبی را تکمیل میکنند، به ویژه در زمینههای خاص دامنه جایی که اصطلاحات فنی نادر اهمیت دارند.
چالشهای کلیدی هنگام مقایسه TF-IDF در مقابل جاسازی کلمات چیست؟
- محدودیتهای معنایی – TF-IDF آگاهی از مترادف ندارد.
- کلمات خارج از واژگان – جاسازیها کلمات دیدهنشده را از طریق توکنسازی زیرکلمه مدیریت میکنند.
- زمینه و چندمعنایی – جاسازیها ابهام حس کلمه را حل میکنند.
- تعادلهای کارایی – جاسازیها حافظه بیشتری نیاز دارند؛ TF-IDF از ماتریسهای پراکنده استفاده میکند.
- قابلیت تفسیر – ابعاد TF-IDF به کلمات نگاشت میشوند، در حالی که ابعاد جاسازی انتزاعی هستند.
سوالات متداول
تفاوت بین جاسازی کلمات و جملات چیست؟
جاسازی کلمات کلمات فردی را کدگذاری میکنند؛ جاسازی جملات جملات کامل را کدگذاری میکنند، و معنای ترکیبی را ضبط میکنند.
جاسازی کلمات، جملات، و اسناد چیست؟
کلمه → کلمات تک؛ جمله → جملات؛ سند → اسناد کامل، هر کدام به عنوان بردارهای متراکم.
تفاوت بین BERT و sentence-transformers چیست؟
BERT جاسازیهای زمینهای سطح توکن خروجی میدهد؛ sentence-transformers مدلهای شبیه BERT را برای تولید جاسازیهای سطح جمله باکیفیت تطبیق میدهند.
تفاوت بین جاسازی جمله و جاسازی توکن چیست؟
جاسازی توکن کلمات/زیرکلمات فردی را نمایان میکند؛ جاسازی جمله جملات کامل را در یک بردار نمایان میکند.
مثالی از جاسازی جمله چیست؟
“Today is a sunny day” → [۰.۳۲, ۰.۴۲, ۰.۱۵, …, ۰.۷۲]، یک بردار ابعاد بالا که معنایی، لحن، و زمینه آن را ضبط میکند.