
آپاچی کافکا چیست؟
آپاچی کافکا یک مخزن داده توزیعشده است که برای دریافت و پردازش دادههای جریانی در زمان واقعی بهینهسازی شده است. دادههای جریانی دادههایی هستند که به طور مداوم توسط هزاران منبع داده تولید میشوند و معمولاً سوابق دادهای را به صورت همزمان ارسال میکنند. یک پلتفرم جریانی باید بتواند این جریان مداوم دادهها را مدیریت کند و دادهها را به ترتیب و به صورت تدریجی پردازش کند.
کافکا سه عملکرد اصلی را به کاربران خود ارائه میدهد:
- انتشار و اشتراک در جریانهای سوابق
- ذخیرهسازی مؤثر جریانهای سوابق به ترتیب تولید آنها
- پردازش جریانهای سوابق در زمان واقعی
کافکا عمدتاً برای ساخت خطوط لوله داده جریانی در زمان واقعی و برنامههای جریانی در زمان واقعی که با جریانهای داده سازگار میشوند، استفاده میشود. این سیستم پیامرسانی، ذخیرهسازی و پردازش جریان را ترکیب میکند تا امکان ذخیرهسازی و تحلیل دادههای تاریخی و در زمان واقعی را فراهم کند.
کافکا برای چه استفاده میشود؟
کافکا برای ساخت خطوط لوله داده جریانی در زمان واقعی و برنامههای جریانی در زمان واقعی استفاده میشود. یک خط لوله داده، دادهها را به طور قابل اعتماد پردازش و از یک سیستم به سیستم دیگر منتقل میکند، و یک برنامه جریانی برنامهای است که جریانهای داده را مصرف میکند. برای مثال، اگر بخواهید یک خط لوله داده ایجاد کنید که دادههای فعالیت کاربران را برای ردیابی نحوه استفاده افراد از وبسایت شما در زمان واقعی جمعآوری کند، کافکا برای دریافت و ذخیره دادههای جریانی و همچنین ارائه خوانش برای برنامههایی که خط لوله داده را پشتیبانی میکنند، استفاده میشود. کافکا همچنین اغلب به عنوان یک راهحل کارگزار پیام استفاده میشود، که پلتفرمی است که ارتباطات بین دو برنامه را پردازش و واسطهگری میکند.
کافکا چگونه کار میکند؟
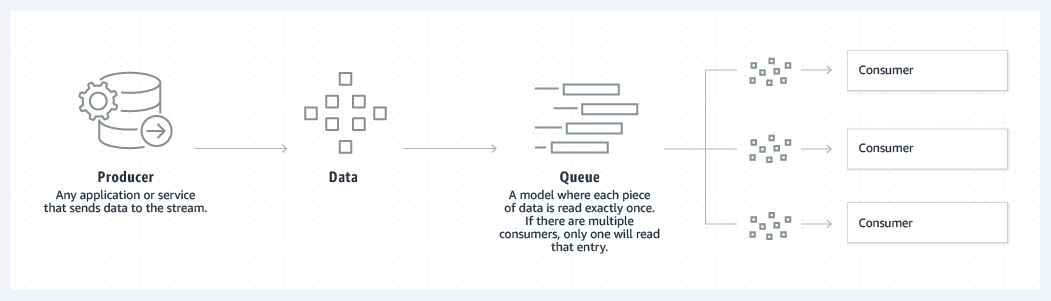
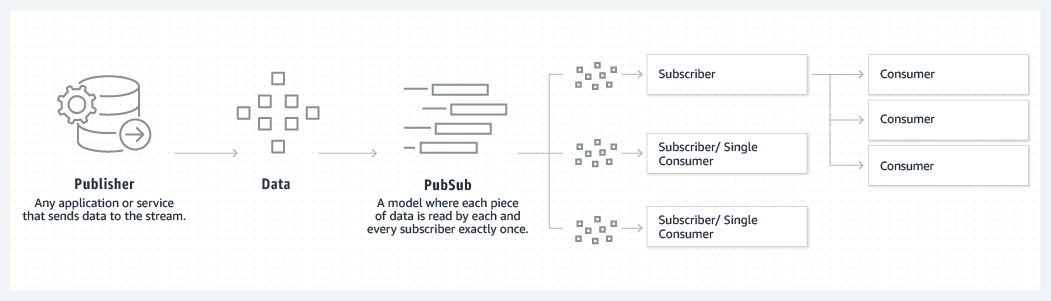
کافکا دو مدل پیامرسانی، صفبندی و انتشار-اشتراک، را ترکیب میکند تا مزایای کلیدی هر یک را به مصرفکنندگان ارائه دهد. صفبندی امکان توزیع پردازش دادهها در چندین نمونه مصرفکننده را فراهم میکند و آن را بسیار مقیاسپذیر میکند. با این حال، صفهای سنتی چندمشترکی نیستند. رویکرد انتشار-اشتراک چندمشترکی است، اما چون هر پیام به هر مشترک میرسد، نمیتوان از آن برای توزیع کار در چندین فرآیند کاری استفاده کرد. کافکا از یک مدل لاگ تقسیمبندیشده برای اتصال این دو راهحل استفاده میکند. لاگ یک دنباله مرتب از سوابق است، و این لاگها به بخشها یا پارتیشنهایی تقسیم میشوند که به مشترکین مختلف مربوط میشوند. این به این معناست که میتواند چندین مشترک برای یک موضوع وجود داشته باشد و هر یک به یک پارتیشن اختصاص داده میشود تا مقیاسپذیری بالاتری فراهم شود. در نهایت، مدل کافکا قابلیت بازپخش را ارائه میدهد، که به چندین برنامه مستقل که از جریانهای داده میخوانند اجازه میدهد به طور مستقل با سرعت خودشان کار کنند.
صفبندی
انتشار-اشتراک
مزایای Kafka چیست؟
- مقیاسپذیری: مدل لاگ تقسیمشده Kafka امکان توزیع دادهها در بین چندین سرور را ایجاد میکند که منجر به مقیاسپذیری بیشتری نسبت به یک سرور واحد می شود.
- سرعت: با جداکردن جریانات داده، تأخیر بسیار کمتر و سرعت بالا میرود.
- دوام: بخشها در بین چندین سرور توزیع و تکرار شده و تمام دادهها بر روی دیسک ذخیره میشوند. به این شکل، از سرور در برابر خرابی محافظت شده و دادهها مقاوم و بادوام میشوند.
چگونه مدلهای مختلف در ساختار Kafka با هم ادغام میشوند؟
Kafka با انتشار رکوردها در موضوعات مختلف، این دو مدل پیامرسانی را بهبود میبخشد. هر موضوع یک لاگ تقسیمشده دارد که در واقع یک لاگ ساختاریافته است و تمام رکوردها را مرتب پیگیری کرده و رکوردهای جدید بی درنگ را بهصورت به آن اضافه میکند. این بخشها در بین چندین سرور توزیع و تکرار میشوند که مقیاسپذیری بالا، تحمل خطا و موازیسازی ایجاد میکند. هر مصرفکننده به یک بخش در موضوع اختصاص داده میشود که چندکاربره بودن را در حین حفظ ترتیب دادهها ممکن میکند. بهاینترتیب، در ترکیب این مدلهای پیامرسانی، Kafka مزایای هر دو را شامل میشود. Kafka همچنین بهعنوان یک سیستم ذخیرهسازی بسیار مقیاسپذیر و مقاوم با نوشتن و تکرار تمام دادهها روی دیسک عمل میکند. Kafka دادهها را روی دیسک تاحدامکان ذخیره میکند و به کاربر هم امکان تنظیم محدودیت نگهداری را میدهد .Kafka دارای چهار API است:
- API تولیدکننده: برای انتشار جریانی از رکوردها به یک موضوع Kafka استفاده میشود.
- API مصرفکننده: برای اشتراکگذاری موضوعات و پردازش جریانات رکوردهای آنها استفاده میشود.
- API جریانات: به برنامهها اجازه میدهد تا بهعنوان پردازشگران جریانی عمل کنند به شکلی که یک جریانی ورودی از موضوعات را دریافت کرده و آن را به جریانی خروجی تبدیل میکند.
- API اتصالدهنده: به کاربران این امکان را میدهد که افزودن یک برنامه یا سیستم داده دیگر به موضوعات فعلی Kafka خود را اتومات کنند.
تفاوتهای Apache Kafka و RabbitMQ در چیست؟
RabbitMQ یک کارگزار پیام متنباز است که از رویکرد صفبندی پیام استفاده میکند. صفها در بین یک خوشه از گرهها توزیع میشوند و به شیوه ای اختیاری تکرار میشوند، بهطوری که هر پیام فقط به یک مصرفکننده ارائه میشود.
| ویژگیها | Apache Kafka | RabbitMQ |
| ساختار | Kafka از مدل لاگ تقسیمشده استفاده میکند که رویکردهای صفبندی پیام و انتشار-اشتراک را ترکیب میکند. |
RabbitMQ از صفبندی پیام استفاده میکند. |
| مقیاسپذیری | Kafka با اجازه توزیع بخشها در بین سرورهای مختلف، مقیاسپذیری را فراهم میکند. |
با افزایش تعداد مصرفکنندگان در صف، پردازش در بین مصرفکنندگان رقابتیتر میشود. |
| نگهداری پیام | بر اساس سیاست: پیامها ممکن است یک روزه ذخیره شوند. کاربر میتواند این پنجره نگهداری را تنظیم کند. |
بر اساس تأیید: پیامها بهمحض مصرفشدن حذف میشوند. |
| چندین مصرفکننده | چندین مصرفکننده میتوانند در یک موضوع خاص شریک شوند، چون Kafka اجازه میدهد پیام یکسانی برای یک بازه زمانی خاص پخش شود. |
چندین مصرفکننده نمیتوانند همه پیام یکسانی دریافت کنند چون پیامها بهمحض مصرفشدن حذف میشوند. |
| تکرار | موضوعات خودکار تکرار میشوند، اما کاربر هم میتواند بهصورت دستی موضوعات را تنظیم کنند تا تکرار نشوند. |
پیامها خودکار تکرار نمیشوند، اما کاربر میتواند بهصورت دستی آنها را برای تکرارشدن تنظیم کند. |
| ترتیب پیام | هر مصرفکننده اطلاعات را با لاگ تقسیم شده به ترتیب دریافت میکند. | پیامها به مصرفکنندگان به ترتیب ورود به صف تحویل داده میشوند. اگر مصرفکنندگان رقابتی وجود داشته باشند، هر مصرفکننده یک زیرمجموعه از آن پیام را پردازش خواهد کرد. |
| پروتکلها | Kafka از یک پروتکل باینری روی TCP استفاده میکند. |
استفاده از پروتکل صف پیام پیشرفته (AMQP) با پشتیبانی از طریق افزونهها: MQTT STOMP |