
چه در حال ساخت یک برنامه وب، یک پلتفرم تجارت الکترونیک، یا یک سیستم داخلی باشید، طراحی طرح پایگاه داده مناسب تعیین میکند که آیا زیرساخت دادههای شما به یک مزیت رقابتی تبدیل شود یا یک مسئولیت پرهزینه. شما باید به مجموعه دادههایی که نیاز دارید و نحوه استفاده از آنها فکر کنید تا جریانهای کاری را بهینهسازی کنید در حالی که از انحراف طرح (schema drift) که منجر به شکستهای فاجعهبار میشود، اجتناب ورزید.
بسته به نوع برنامهای که توسعه میدهید، رویکرد شما به طرح پایگاه داده نیز تغییر میکند.
طرح پایگاه داده چیست؟
طرحهای پایگاه داده، نقشههای ساختمانی پایگاه داده شما هستند. آنها ساختار و روابط بین عناصر داده را تعریف میکنند. یک طرح خوب برنامهریزیشده:
- یکپارچگی داده را حفظ میکند
- پرسوجوهای کارآمد را امکانپذیر میسازد
- مقیاسپذیری را پشتیبانی میکند
با طرحها، میتوانید جداول، وابستگیها، و انواع داده را نگاشت کنید، و معماری داده برنامه خود را به وضوح به ذینفعان منتقل کنید. این کار به شناسایی زودهنگام مسائل، تشخیص افزونگی، و کاهش هدررفت ذخیرهسازی یا محاسباتی در آینده کمک میکند.
انواع مختلف طرحهای پایگاه داده چیست؟
طرحهای پایگاه داده به سه لایه گسترده انتزاع تقسیم میشوند:

۱. طرح مفهومی
یک نمای کلی سطح بالا که در مراحل اولیه پروژه ایجاد میشود. این طرح قوانین کسبوکار و الزامات سیستم را بدون نگرانی در مورد پایگاههای داده یا نحو (syntax) ثبت میکند.
۲. طرح منطقی
نمای مفهومی را به جداول، ستونها، انواع داده، و محدودیتها ترجمه میکند. این طرح پلی بین زبان کسبوکار و جزئیات فنی است.
۳. طرح فیزیکی
توصیف میکند که چگونه دادهها روی دیسک ذخیره میشوند—ساختارهای فایل، شاخصها، پارتیشنبندی، و ویژگیهای خاص فروشنده—با بهینهسازی برای عملکرد و ذخیرهسازی.
برخی از طرحهای رایج پایگاه داده چیست؟
در زیر طرحهای رایج آورده شده است که میتوانید بر اساس ساختار داده و الگوهای پرسوجو انتخاب کنید.
طرح تخت (Flat Schema)
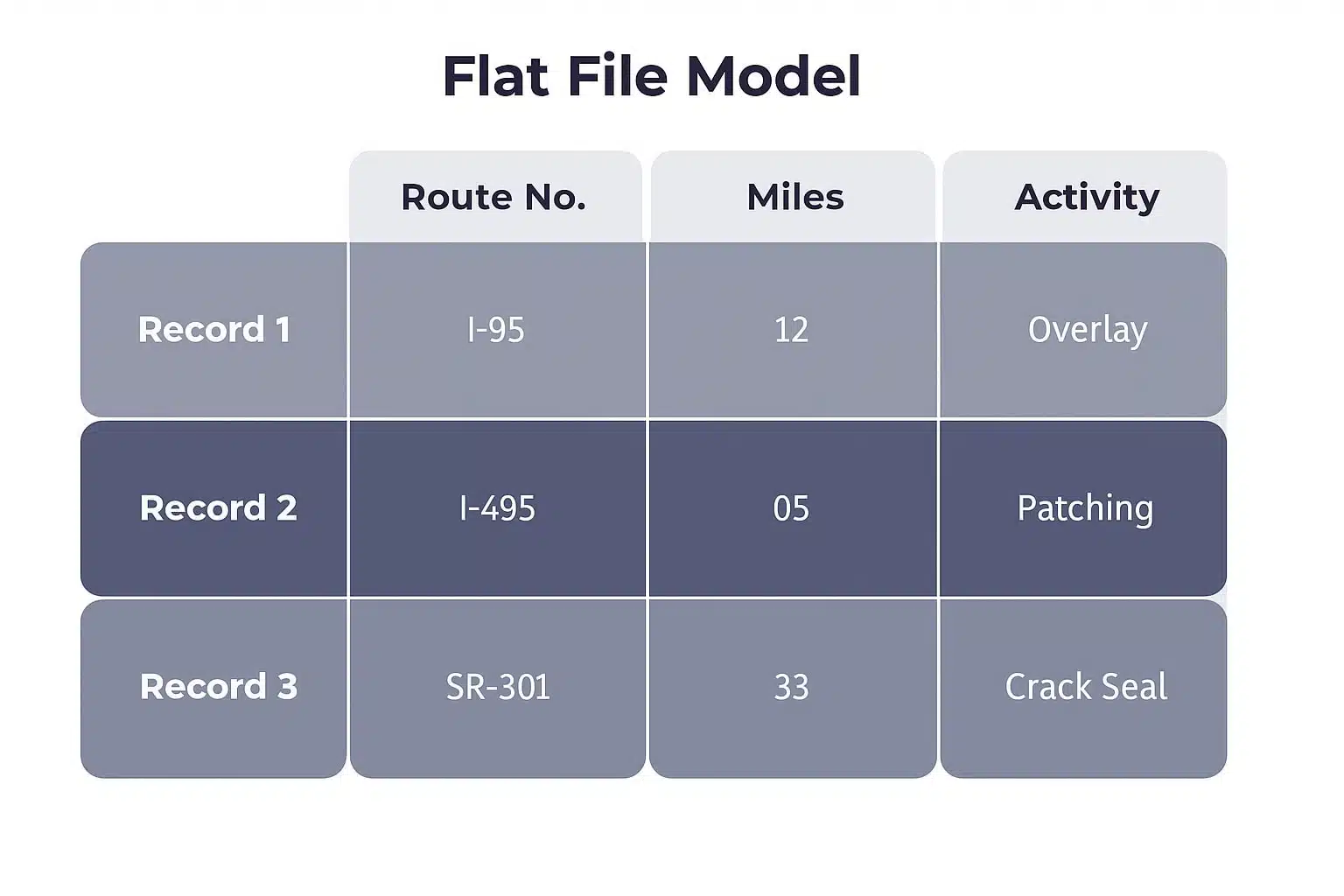
یک جدول دوبعدی ساده. فقط برای بارهای کاری جزئی یا موقت مناسب است؛ در مقیاس بزرگ غیرقابل مدیریت میشود.
طرح ستارهای (Star Schema)
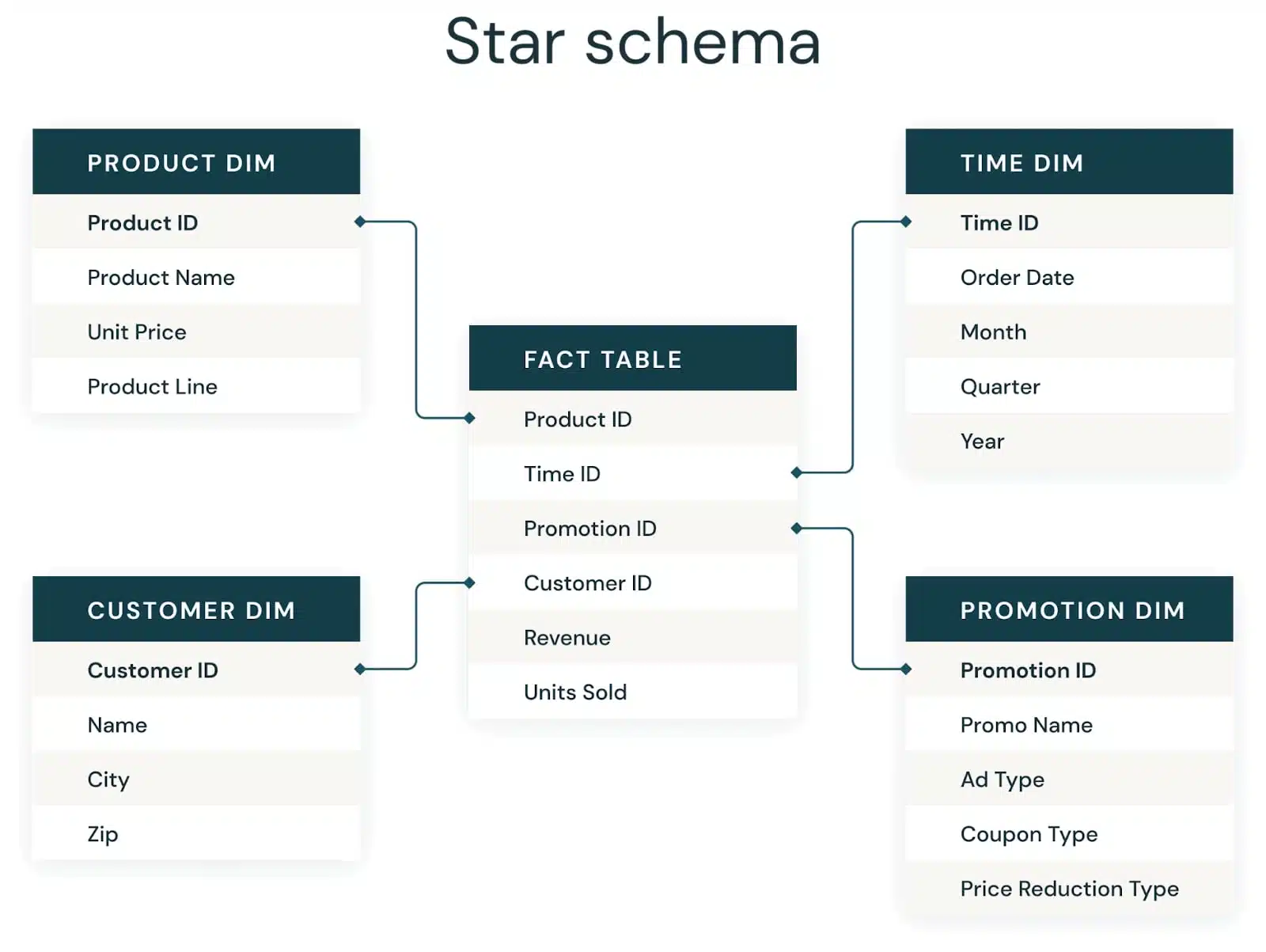
یک جدول واقعیت مرکزی مستقیماً به جداول بعد (dimension tables) متصل میشود—کلاسیک برای تحلیلهای انبار داده.
طرح دانهبرفی (Snowflake Schema)
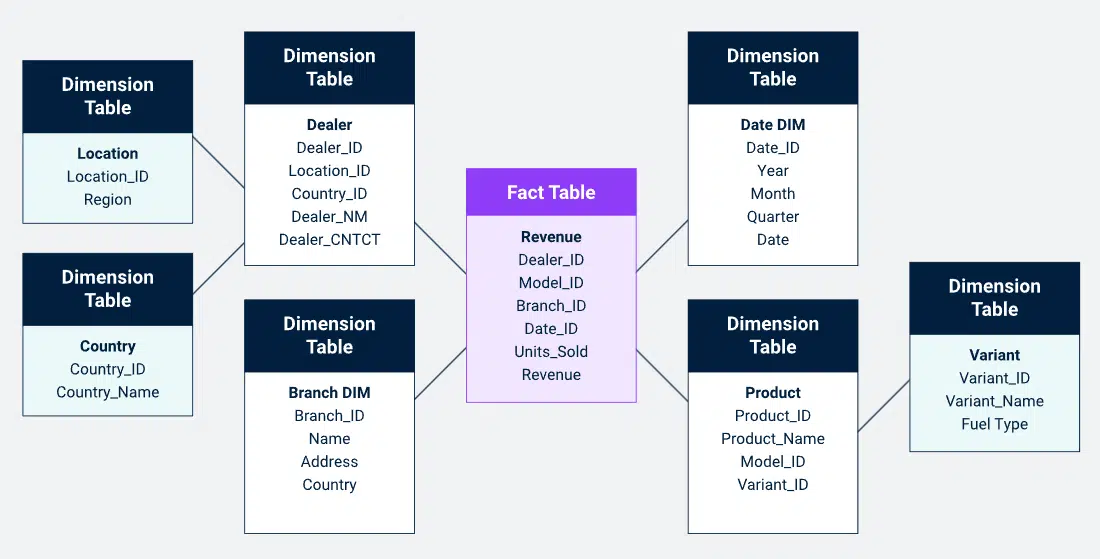
یک گسترش نرمالشده از طرح ستارهای؛ جداول بعد به زیربعدهای تقسیم میشوند برای بهبود یکپارچگی.
طرح کهکشانی (Galaxy Schema)
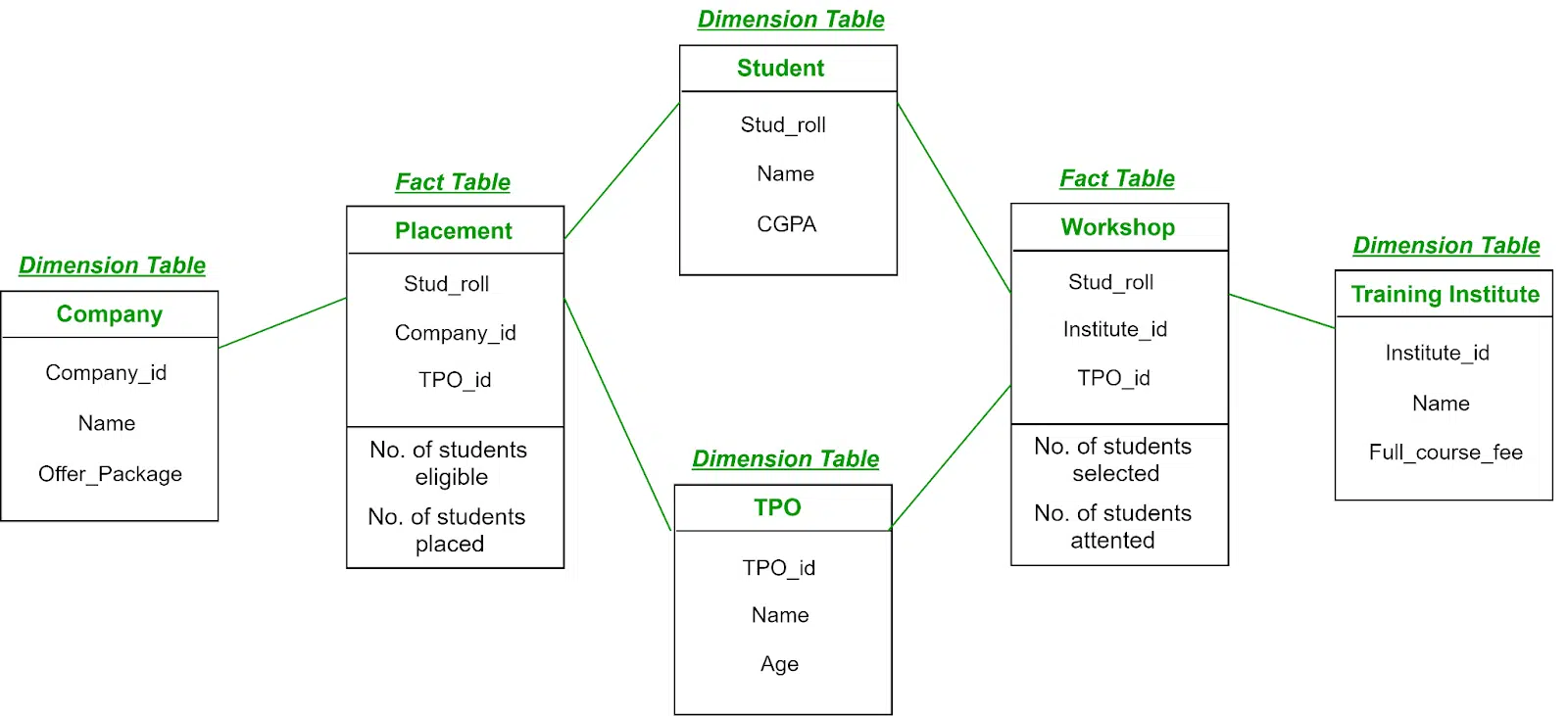
چند جدول واقعیت ابعاد سازگار (conformed dimensions) را به اشتراک میگذارند—ایدهآل برای تحلیلهای سازمانی گسترده.
طرح یکبهچند (One-to-Many Schema)
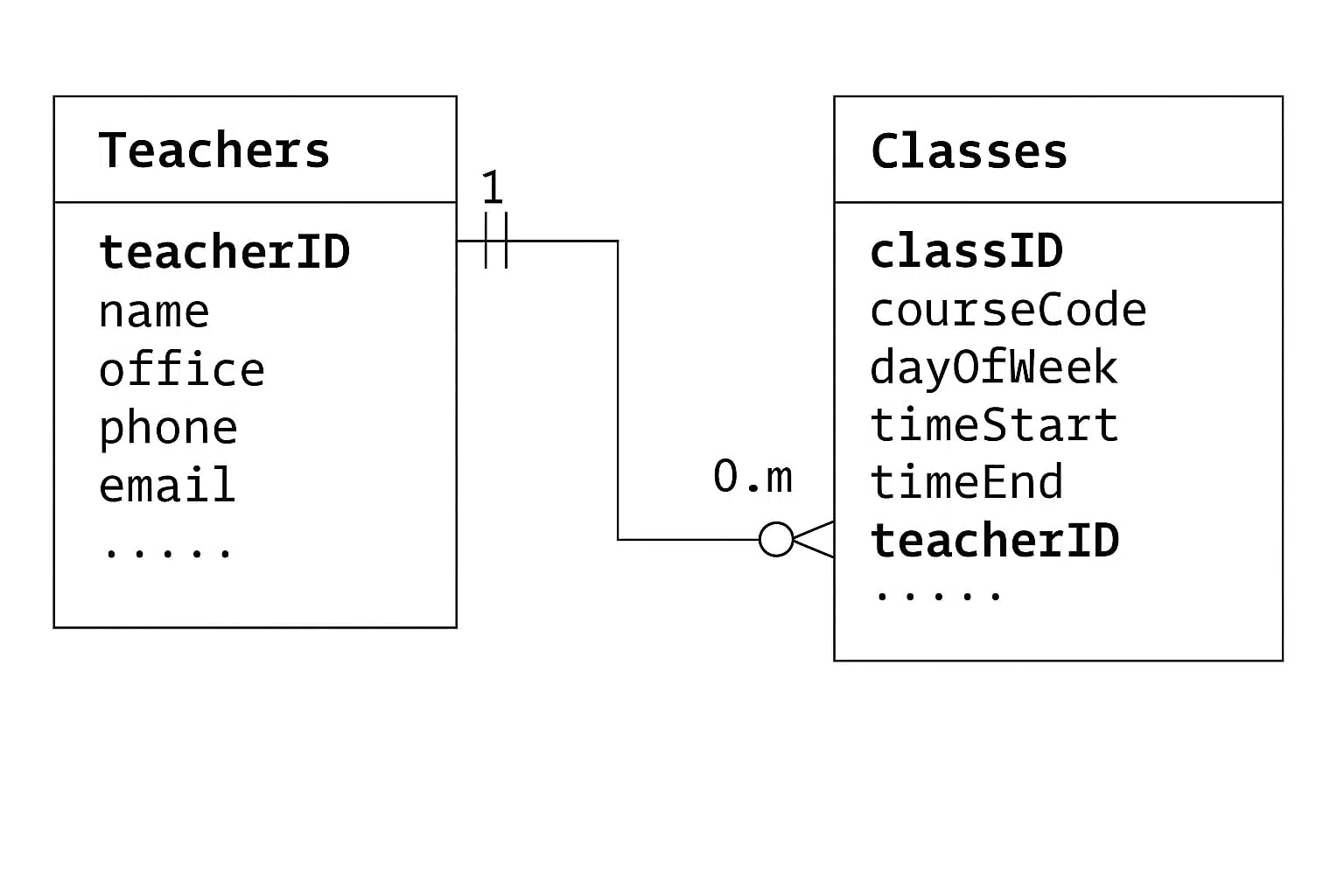
یک رکورد والد به چندین رکورد فرزند مرتبط است—هسته مدلهای رابطهای نرمالشده.
طرح شبکهای (Network Schema)
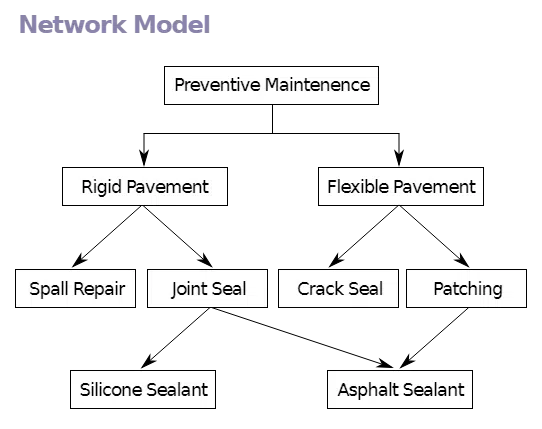
روابط چندبهچند را پشتیبانی میکند، که برای شبکههای اجتماعی، زنجیرههای تأمین، یا سیستمهای توصیهگر مفید است.
مثالهای مؤثرترین طرحها برای کاربردهای مختلف چیست؟
در اینجا چهار مثال عملی طرح آورده شده است که سناریوهای رایج صنعتی را پوشش میدهد و نشان میدهد چگونه پایگاههای داده را برای موارد استفاده خاص ساختاربندی کنید.
۱. مثال طرح تجارت الکترونیک
- موجودیتهای کلیدی: مشتریان (Customers)، محصولات (Products)، سفارشها (Orders)، اقلام سفارش (Order_Items)

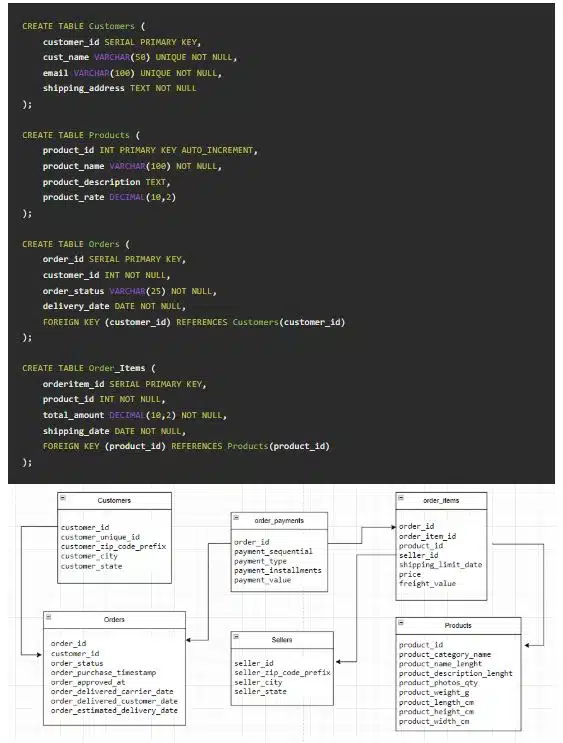
نسخههای مدرن اغلب ستونهای JSONB برای ویژگیهای متغیر محصول اضافه میکنند، جداول سری زمانی برای موجودی، و جداول حسابرسی برای رعایت مقررات.
۲. مثال طرح سیستم بهداشت و درمان
- موجودیتها: بیمار (Patient)، نوبت (Appointment)، پزشک (Doctor)


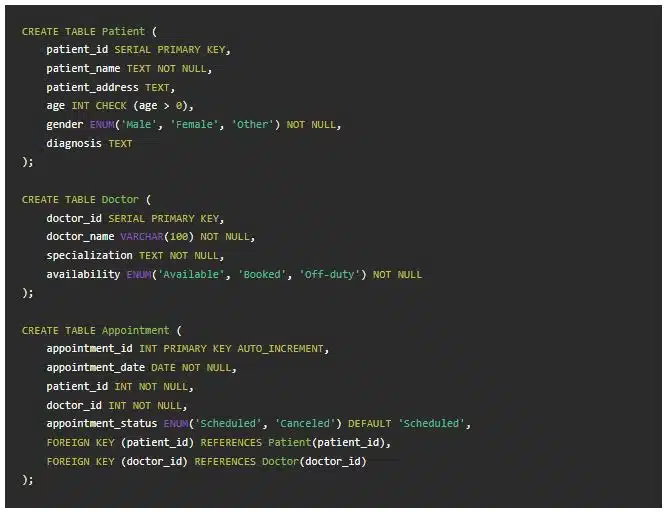
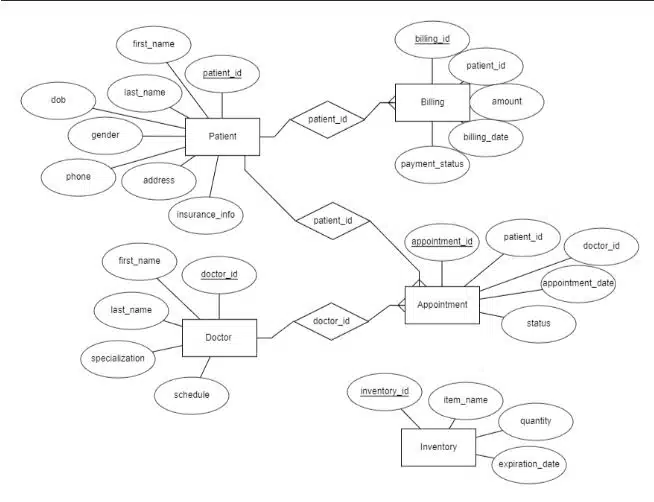
الزامات اضافی اغلب شامل رمزنگاری، ردپاهای حسابرسی (HIPAA)، و ادغام با سیستمهای رکورد سلامت الکترونیکی است.
۳. مثال طرح CMS (سیستم مدیریت محتوا)
- موجودیتها: کاربران (Users)، نقشها (Roles)، محتوای دیجیتال (Digital_Content)، دستهبندیها (Categories)


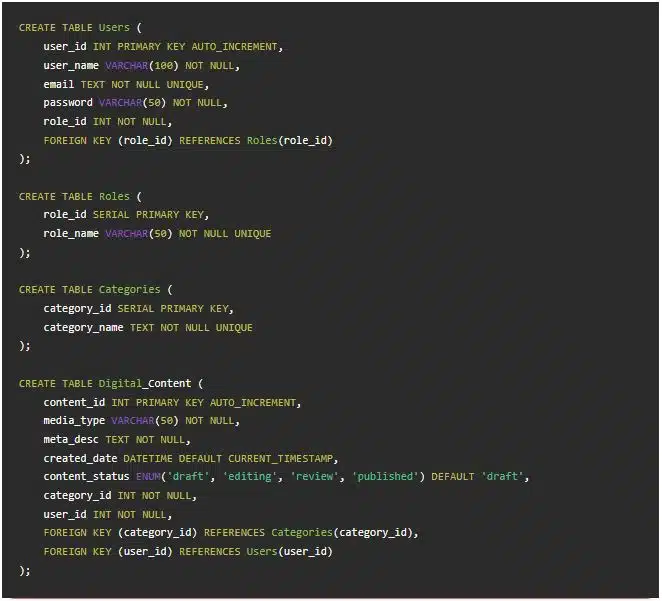
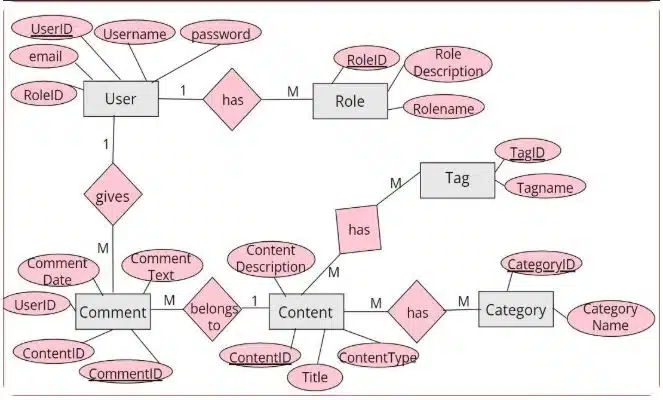
طراحیهای مدرن CMS نسخهبندی محتوا، جداول محلیسازی، و ادغام CDN اضافه میکنند.
۴. مثال طرح جهتدار به شبکه/گراف
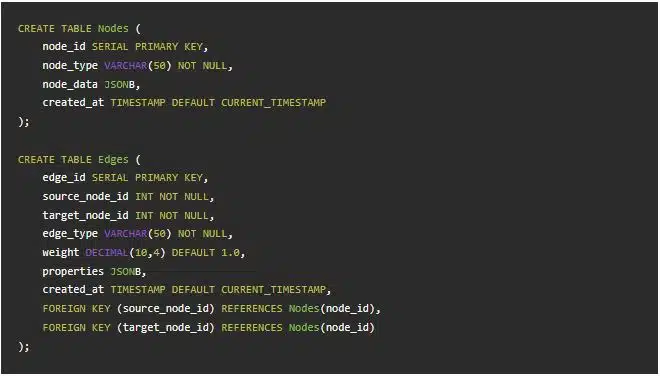
در رسانههای اجتماعی، لجستیک، یا موتورهای توصیهگر استفاده میشود تا روابط چندبهچند را مدلسازی کند.
الگوهای طراحی طرح مدرن برای برنامههای مقیاسپذیر چیست؟
معماری طرح پایگاه داده مدرن فراتر از مدلهای رابطهای سنتی تکامل یافته است تا الزامات ادغام تخصصی و چالشهای مقیاسپذیری را برطرف کند. الگوهای طراحی طرح معاصر تعادل بین یکپارچگی ساختاری و بهینهسازی عملکرد را برقرار میکنند در حالی که انواع دادههای متنوع و الگوهای دسترسی را تطبیق میدهند.
معماریهای طرح چندمدلی
پایگاههای داده چندمدلی مدیریت یکپارچه طرح را در سراسر دادههای رابطهای، سندمحور، و گراف در یک پلتفرم واحد امکانپذیر میسازند. PostgreSQL این رویکرد را از طریق نوع داده JSONB نمونهسازی میکند، که ذخیرهسازی بدون وابستگی به طرح (schema-agnostic) دادههای نیمهساختاریافته را در حالی که قابلیتهای پرسوجوی SQL را حفظ میکند، اجازه میدهد. این رویکرد ترکیبی سختی سنتی طرح را بدون قربانی کردن عملکرد تحلیلی حذف میکند.
الگوهای طرحبرخواندن در مقابل طرحبرنوشتن
پیادهسازیهای طرحبرخواندن (schema-on-read) در محیطهای داده بزرگ برجسته شدهاند، که اجازه میدهند دادههای خام بدون تحول اولیه جذب شوند در حالی که تفسیر ساختاری در حین اجرای پرسوجو اعمال میشود. این رویکرد تکامل طرح را به طور ذاتی تطبیق میدهد، و آن را به ویژه برای دریاچههای داده (data lakes) و بارهای کاری تحلیلی ارزشمند میکند جایی که سیستمهای منبع به طور مستقل تکامل مییابند.
نوآوریهای طرح بومی ابر
پلتفرمهای داده ابری امکانات طراحی طرح را از طریق معماریهای بدون سرور و مدیریت متاداده پویا به طور اساسی تحول بخشیدهاند. نوع داده VARIANT Snowflake ذخیرهسازی بدون وابستگی به طرح را در حالی که عملکرد SQL را حفظ میکند، امکانپذیر میسازد، و “فلج طراحی طرح”—تمایل به مهندسی بیش از حد طرحهای اولیه برای اجتناب از تغییرات آینده—را که محققان آن را اصطلاح میکنند، کاهش میدهد.
استانداردهای صنعتی و الزامات رعایت مقررات چگونه طراحی طرح را شکل میدهند؟
طراحی طرح پایگاه داده در چارچوبهای استانداردهای صنعتی و الزامات نظارتی عمل میکند که تضمینکننده interoperability، امنیت، و رعایت مقررات در سیستمها و حوزههای قضایی مختلف است.
استانداردهای SQL و چارچوبهای مشخصات
- استاندارد ISO/IEC 9075 SQL همچنان مشخصات بنیادی برای تعریف طرح پایگاه داده فراهم میکند، با بهروزرسانیهای اخیر که به طور خاص الزامات ادغام مدرن را مورد توجه قرار میدهند.
- مشخصات SQL/Schemata INFORMATION_SCHEMA را تعریف میکند که دسترسی به متاداده را در سراسر سیستمهای سازگار استانداردسازی میکند، و نمایهای سازگار از اشیاء پایگاه داده، محدودیتها، و امتیازها فراهم میکند.
- استاندارد SQL/Persistent Stored Modules کپسولهسازی منطق رویهای را استانداردسازی میکند، و پیادهسازی منطق کسبوکار قابل حمل را در لایه پایگاه داده به جای کد برنامه امکانپذیر میسازد. این امر به ویژه برای سیستمهای ادغامشده که نیاز به قوانین اعتبارسنجی مشترک در سراسر چندین برنامه دارند، مفید است.
- مشخصات SQL/XML مدلهای داده رابطهای-XML ترکیبی را تسهیل میکند که دادههای نیمهساختاریافته را در طرحهای رابطهای سنتی تطبیق میدهد، و رویکردهای استاندارد برای ذخیرهسازی، نمایهسازی، و پرسوجوی XML فراهم میکند.
استانداردهای طرح خاص دامنه
فراتر از استانداردهای اصلی SQL، چارچوبهای طرح خاص صنعتی چالشهای ادغام خاص دامنه را برطرف میکنند.
- سیستمهای بهداشت و درمان به طور گسترده استانداردهای HL7 FHIR را برای طرحهای داده بالینی اتخاذ میکنند که تبادل داده بینسازمانی را با مدلهای منبع تعریفشده و مکانیسمهای گسترشپذیری امکانپذیر میسازد. این استانداردها تضمین میکنند که دادههای بیمار بتوانند بدون مشکل بین بیمارستانها، کلینیکها، و سیستمهای بیمه جریان یابند در حالی که الزامات حریم خصوصی و امنیت حفظ شود.
- خدمات مالی از طرحهای FINARCH و پروتکل FIX برای ادغام دادههای تراکنشی بهره میبرند، و نمایهای استاندارد برای ابزارها، تراکنشها، و دادههای بازار فراهم میکنند. این چارچوبها به طور مکمل با استانداردهای اصلی پایگاه داده عمل میکنند، و تعاریف ساختاری خاص عمودی را در حالی که از زبان تعریف داده SQL زیربنایی برای سازگاری پیادهسازی بهره میبرند، فراهم میکنند.
- سیستمهای اطلاعات جغرافیایی مشخصات OGC Simple Features را برای طرحهای داده فضایی پیادهسازی میکنند که interoperability را در سراسر پلتفرمهای نقشهبرداری تضمین میکند. این استانداردها تعریف میکنند که چگونه مختصات جغرافیایی، مرزها، و روابط فضایی باید ذخیره و پرسوجو شوند، و به برنامهها اجازه میدهند دادههای مبتنی بر مکان را در سراسر سیستمها و فروشندگان مختلف به اشتراک بگذارند.
ملاحظات طرح مبتنی بر رعایت مقررات
رعایت مقررات محدودیتهایی بر تکامل طرح، به ویژه در مورد حفظ دادههای تاریخی و ردپاهای حسابرسی، معرفی میکند.
- الزامات GDPR ردیابی رضایت صریح و قابلیتهای حذف داده را تقاضا میکنند، و طراحیهای طرحی را ضروری میسازد که بتوانند درخواستهای “حق فراموشی” را بدون به خطر انداختن یکپارچگی ارجاعی تطبیق دهند.
- رعایت HIPAA در سیستمهای بهداشت و درمان نیاز به رمزنگاری، کنترلهای دسترسی، و ردپاهای حسابرسی جامع دارد که مستقیماً در طراحیهای طرح ساخته شوند.
- رعایت SOX در خدمات مالی نیاز به حفظ غیرقابل تغییر تاریخچههای تراکنش و پشتیبانی از گزارشدهی نظارتی از طریق طراحی طرح دارد.
ابزارهای مبتنی بر هوش مصنوعی چگونه طراحی و مدیریت طرح پایگاه داده را تحول میبخشند؟
تولید و بهینهسازی طرح مبتنی بر هوش مصنوعی
تولیدکنندههای طرح مبتنی بر هوش مصنوعی اکنون از یادگیری ماشین برای تحلیل ساختارهای داده موجود، الزامات برنامه، و سیاستهای حاکمیت استفاده میکنند تا طرحهای پایگاه داده بهینهشده را به طور خودکار تولید کنند. این ابزارها از تولید افزودهشده با بازیابی (retrieval-augmented generation) برای تحلیل هزاران الگوی طرح استفاده میکنند، و روابط جدول بهینه و استراتژیهای نمایهسازی را بر اساس دادههای عملکرد تاریخی پیشبینی میکنند. ابزارهایی مانند تولیدکننده طرح هوش مصنوعی GigaSpaces میتوانند اسناد JSON را به طور خودکار به جداول SQL نرمالشده تبدیل کنند، مستندسازی طرح جامع تولید کنند، و بهینهسازیهای عملکرد را پیشنهاد دهند. هنگامی که با دادههای JSON کاتالوگ محصول ارائه شود، این سیستمها SQL کاملاً حاشیهنویسیشده با محدودیتها، شاخصها، و روابط مناسب تولید میکنند. این خودکارسازی زمان طراحی طرح را به طور قابل توجهی کاهش میدهد در حالی که بهترین شیوههایی را که ممکن است در فرآیندهای طراحی دستی نادیده گرفته شوند، شامل میشود.
تبدیل و مهاجرت طرح هوشمند
هوش مصنوعی generative مدرنیزاسیون پایگاههای داده legacy را با ترجمه گویشهای SQL اختصاصی به معادلهای منبعباز با دقت بالا متحول کرده است. سرویس مهاجرت داده AWS اکنون از یادگیری ماشین برای خودکارسازی تبدیلهای رویههای ذخیرهشده و محرکها استفاده میکند، و نرخهای خودکارسازی بالا را برای مهاجرتهای پایگاه داده پیچیده دستیابی میکند. این ابزارهای تبدیل مبتنی بر هوش مصنوعی نگاشت آگاه از زمینه را فراهم میکنند که توابع خاص پایگاه داده را در حالی که معادل معنایی را حفظ میکند، ترجمه میکند. توابع NVL() Oracle به COALESCE() PostgreSQL با نظرات جاسازیشده که تغییرات منطق را توضیح میدهند، تبدیل میشوند. استنباط نوع داده به طور خودکار انواع اختصاصی را به معادلهای استاندارد با اعتبارسنجیهای اندازه مناسب و محدودیتها تبدیل میکند. این تبدیل هوشمند زمانبندیهای مهاجرت را از ماهها به هفتهها کاهش میدهد در حالی که خطر خطاهای عملکردی در کد تبدیلشده را به حداقل میرساند.
تکامل و نگهداری طرح پیشبینیکننده
مدلهای یادگیری ماشین اکنون فرصتهای بهینهسازی طرح را با تحلیل الگوهای پرسوجو و معیارهای عملکرد پیشبینی میکنند. مشاوران شاخص مبتنی بر هوش مصنوعی شاخصهای بهینه را بر اساس لاگهای پرسوجوی کند و الگوهای دسترسی پیشنهاد میدهند، در حالی که پیشبینیکنندههای شاردینگ (sharding) نیازهای پارتیشنبندی را از طریق تحلیل الگوهای دسترسی پیشبینی میکنند. سیستمهای پیشرفته تکامل طرح پیشبینیکننده را پیادهسازی میکنند جایی که الگوریتمها الزامات ساختاری آینده را بر اساس روندهای استفاده پیشبینی میکنند، و تطبیق پیشفعال را قبل از وقوع گلوگاههای ادغام امکانپذیر میسازد. این مدلها تغییرات طرح تاریخی، روندهای عملکرد پرسوجو، و الگوهای استفاده برنامه را تحلیل میکنند تا تغییرات ساختاری را توصیه کنند که عملکرد را بهبود بخشد و رشد آینده را تطبیق دهد.
استراتژیهای فدراسیون GraphQL برای مدیریت طرح توزیعشده چیست؟
- طرحهای تکتکه (monolithic) را به زیرگرافهای خاص دامنه تجزیه کنید.
- از یک روتر برای ترکیب یک ابرگراف (supergraph) استفاده کنید در حالی که تیمها بخشهای خود را به طور مستقل مالک هستند.
- بررسیهای سازگاری را قبل از استقرار برای اجتناب از تغییرات شکستدهنده اعمال کنید.
این رویکرد انتشارها را تسریع میکند و با اصول data-mesh همخوانی دارد.
چگونه میتوانید استراتژیهای مؤثر تکامل و مهاجرت طرح را پیادهسازی کنید؟
۱. مهاجرتهای بدون قطعی (Zero-Downtime Migrations): ابزارهایی مانند gh-ost جداول سایه ایجاد میکنند، از طریق محرکها همگامسازی میکنند، سپس به طور اتمی (atomically) تغییر میدهند.
۲. طرحبهکد (Schema-as-Code): راهحلهایی مانند Atlas یا Liquibase حالت مورد نظر را در سیستمهای کنترل نسخه ذخیره میکنند و مهاجرتها را به طور خودکار تولید میکنند.
۳. مهندسی تابآوری (Resilience Engineering): پشتیبانگیریها، استقرارهای کاناری (canary deployments)، و تشخیص انحراف خطر را در حین تغییرات کاهش میدهند.
ملاحظات کلیدی برای پیادهسازی موفق طرح چیست؟
۱. الزامات و مدلسازی: ذینفعان را زود درگیر کنید و تعادل بین نرمالسازی و غیرنرمالسازی را برقرار کنید.
۲. عملکرد و مقیاسپذیری: به طور هوشمند نمایهگذاری کنید، جداول بزرگ را پارتیشنبندی کنید، و مدالیتههای داده جدید را پیشبینی کنید.
۳. امنیت و رعایت مقررات: فیلدهای حساس را رمزنگاری کنید، کنترل دسترسی مبتنی بر نقش را اعمال کنید، و لاگهای حسابرسی برای GDPR/HIPAA حفظ کنید.
۴. خودکارسازی و ابزارها: طرحبهکد، اعتبارسنجی CI/CD، و نظارت بر انحراف را بپذیرید.
۵. تکامل مداوم: برای تغییر طراحی کنید، تستهای کامل را پیادهسازی کنید، و بازخورد را برای بهینهسازیهای آینده جمعآوری کنید.
ملاحظات کلیدی برای پیادهسازی موفق طرح
پیادهسازی موفق طرح نیاز به تعادل بین نرمالسازی با بهینهسازی عملکرد دارد در حالی که برای رشد آینده و رعایت مقررات برنامهریزی میکند. طرحهایی طراحی کنید که بتوانند با الزامات کسبوکار در حال تغییر از طریق ابزارهای خودکار و نظارت مداوم تکامل یابند. بر ایجاد ساختارهای قابل نگهداری تمرکز کنید که عملیات فعلی و فناوریهای نوظهور مانند بارهای کاری هوش مصنوعی و تحلیلهای بلادرنگ را پشتیبانی کنند.
سؤالات متداول
چقدر باید طرح پایگاه داده خود را بررسی و بهروزرسانی کنید؟
بررسی طرح باید با چرخه انتشار شما همخوانی داشته باشد، به ویژه پس از بهروزرسانیهای عمده ویژگی یا ادغامهای جدید. ابزارهایی که طرحبهکد و نظارت بر انحراف را پشتیبانی میکنند، تغییرات ناخواسته را زود تشخیص میدهند.
انحراف طرح چیست، و چرا خطرناک است؟
انحراف طرح زمانی رخ میدهد که پایگاه داده زنده از طراحی یا طرح کنترلشده نسخهای مورد نظر منحرف شود. با گذشت زمان، این عدم همخوانی منجر به باگها، از دست رفتن داده، و قطعیها میشود.