
اهمیت اتوماسیون پایپلاین داده در مدیریت حجمهای بزرگ داده
اتوماسیون پایپلاین داده نحوه مدیریت حجمهای رو به رشد داده توسط سازمانها را متحول کرده است، با بسیاری از شرکتها که ترابایتهای اطلاعات را روزانه در چندین سیستم پردازش میکنند. چالش نه تنها در مدیریت این دادهها، بلکه در تبدیل آنها از فرمتهای پراکنده و ناسازگار به هوش تجاری عملیاتی است. پردازش دستی داده گلوگاههایی ایجاد میکند که تصمیمگیری را کند میکند و خطاهای پرهزینه معرفی میکند و اتوماسیون را برای مزیت رقابتی ضروری میسازد.
اتوماسیون پایپلاین داده مدرن از هوش مصنوعی، قابلیتهای پردازش واقعیزمان و معماریهای بومی ابر برای ایجاد سیستمهای خودبهینهسازی استفاده میکند که با نیازهای تجاری در حال تغییر سازگار میشوند. شرکتهایی که خطوط لوله خودکار را پیادهسازی میکنند، زمان پردازش داده خود را از هفتهها به ساعتها کاهش میدهند در حالی که کیفیت و ثبات داده را در عملیات خود به طور قابل توجهی بهبود میبخشند.
ابزارهای مختلفی از ساخت و اتوماسیون خطوط لوله داده مختلف پشتیبانی میکنند، از جمله دستهای، استخراج-بارگذاری-تحول، استخراج-تحول-بارگذاری و جریانی. در میان اینها، ابزارهای پایپلاین استخراج-بارگذاری-تحول پیشبینی میشود تا سال ۲۰۳۱ بازار را رهبری کنند به دلیل توانایی آنها در مدیریت مجموعههای داده بزرگ.
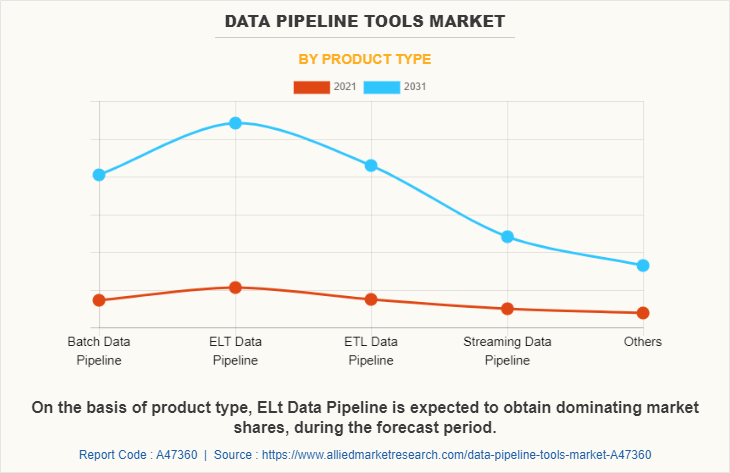
با انتخاب ابزار پایپلاین داده که با مورد استفاده شما سازگار است، میتوانید پایپلاین خود را پیکربندی و اتوماتیک کنید تا پردازش داده را ساده کنید. با اتوماسیون در جای خود، میتوانید کاملاً بر بهرهبرداری از داده تمرکز کنید نه مدیریت فرآیندهای جریان داده پیچیده.
در این مقاله، ابزارها و تکنیکهای مختلف برای اتوماسیون پایپلاین داده را خواهید آموخت و اهمیت و مزایای اتوماسیون خطوط لوله داده را کاوش خواهید کرد.
پایپلاین داده خودکار چیست؟
پایپلاین داده خودکار مجموعهای پیکربندیشده از فرآیندهایی است که به شما کمک میکند داده را در سراسر منابع مختلف حرکت دهید و آماده کنید. این تضمین میکند استخراج، تحول و بارگذاری کارآمد (استخراج-تحول-بارگذاری/استخراج-بارگذاری-تحول) داده برای تحلیل دقیق یا سایر موارد استفاده. با اتوماتیک کردن این مراحل، پایپلاین به حفظ ثبات و دقت در سراسر جریان کاری کمک میکند. در نتیجه، میتوانید به دادههای با کیفیت بالا برای تصمیمگیری هوشمند و دقیق دسترسی داشته باشید.
علاوه بر این قابلیتها، میتوانید وظایف تکراری را ساده کنید، خطاها را به حداقل برسانید و تلاش انسانی را با پایپلاین داده خودکار کاهش دهید. این به شما امکان میدهد حجمهای بزرگ داده را به طور روان مدیریت کنید.
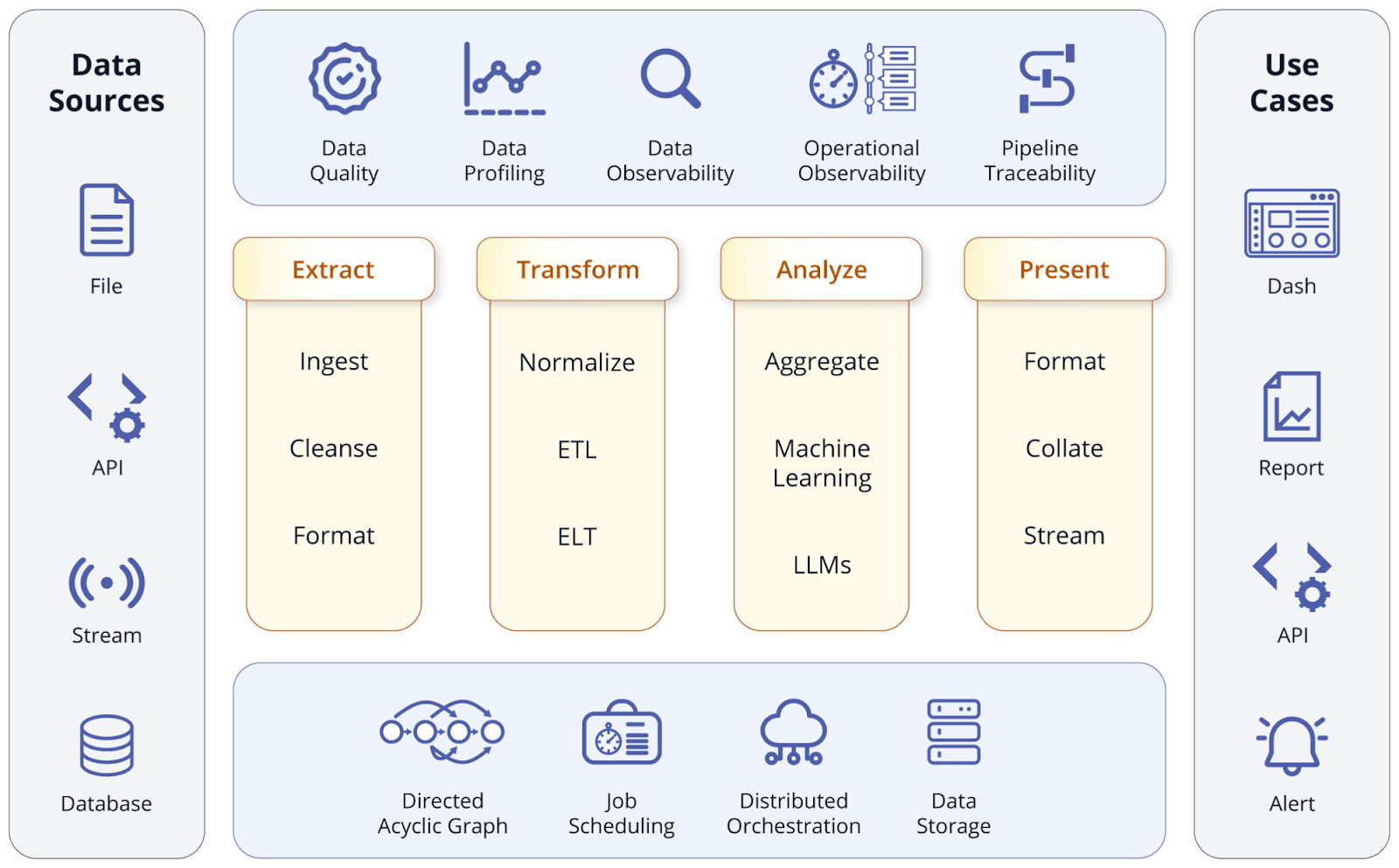
مراحل کلیدی اطوماسیون پایپلاین داده شامل:
- جمعآوری داده: داده خام از منابع متنوع، از جمله پایگاههای داده، رابطهای برنامهنویسی کاربردی، مدیریت ارتباط با مشتریها یا برنامههای سازمانی جمعآوری میشود.
- ورود داده: داده جمعآوریشده به پایپلاین آورده میشود و در یک منطقه موقت برای پردازش بیشتر بارگذاری میشود.
- تحول داده: داده واردشده پاکسازی، نرمالسازی و ساختاربندی برای تحلیل مناسب میشود. فرآیند تحول شامل وظایفی مانند حذف تکراریها، مدیریت مقادیر گمشده و استانداردسازی فرمتها است. هر منطق تجاری لازم برای تحلیل در این مرحله اعمال میشود.
- هماهنگی و اتوماسیون جریان کاری: جریانهای کاری داده با استفاده از ابزارهای اتوماسیون مانند Prefect یا Dagster زمانبندی، نظارت و مدیریت میشوند. این مرحله تضمین میکند که هر وظیفه به ترتیب صحیح و به موقع اجرا شود.
- ذخیره داده: داده پردازششده در مقصد ترجیحی، مانند انبار داده، دریاچه داده یا هر پایگاه داده دیگری ذخیره میشود. میتوانید سیستمهای داده را با ابزارهای تحلیلی برای تحلیل دقیق ادغام کنید.
- ارائه داده: پس از تحلیل، بینشها از طریق داشبوردها یا ابزارهای گزارشگیری به صورت بصری نمایش داده میشوند تا تصمیمات تجاری استراتژیک گرفته شود.
- نظارت و ثبت وقایع: مکانیسمهای نظارت و ثبت وقایع برای پیگیری جریان داده، شناسایی خطاها و حفظ سلامت پایپلاین پیادهسازی میشوند.
با اتوماتیک کردن این مراحل، میتوانید مجموعههای داده حجیم را به طور کارآمد مدیریت کنید، خطاها را به حداقل برسانید و تصمیمگیری را بهبود ببخشید.
پایپلاین داده خودکار چگونه طبقهبندی میشوند؟
برای درک بهتر رویکردهای مختلف برای اتوماسیون پایپلاین داده، مهم است که طبقهبندی آنها را بر اساس عوامل کلیدی مانند معماری، عملکرد و قابلیت ادغام کاوش کنید. این دیدگاه روشنی در مورد اینکه کدام پایپلاین برای نیازهای خاص بهترین است، ارائه میدهد.
پایپلاین ETL در مقابل ELT
پایپلاین استخراج-تحول-بارگذاری شامل استخراج داده از منابع متنوع، غنیسازی آن به فرمت استاندارد و بارگذاری آن به سیستم هدف است. این خطوط لوله معمولاً زمانی استفاده میشوند که تحولات قبل از ذخیره داده لازم است.
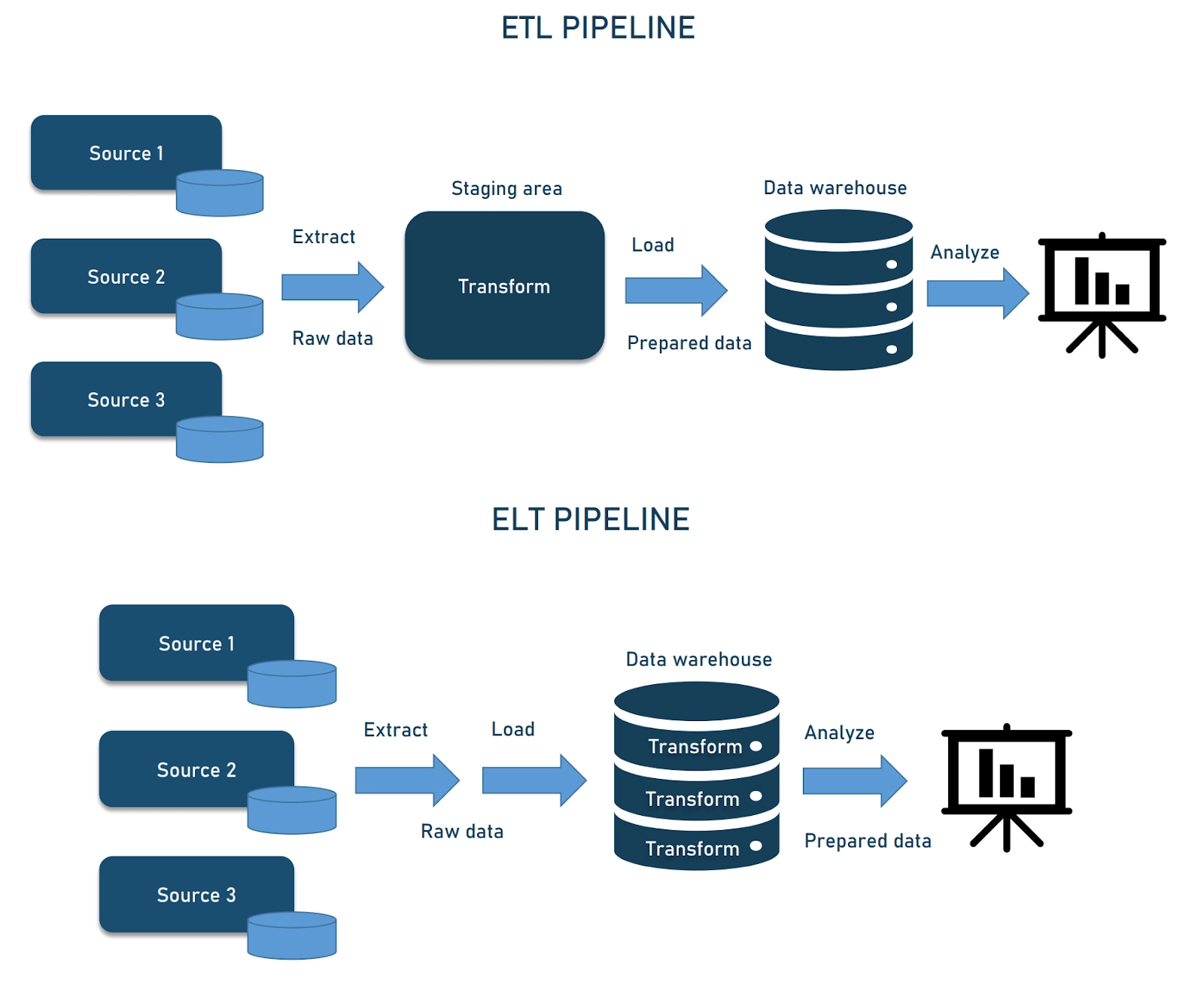
در مقابل، پایپلاین استخراج-بارگذاری-تحول به شما اجازه میدهند داده را از منبع جمعآوری کنید، آن را به مقصد منتقل کنید و سپس تحولات را زمانی که لازم است انجام دهید. این رویکرد به شما امکان میدهد از قابلیتهای انبار داده مدرن بهره ببرید و تحولات سریعتر و تحلیل واقعیزمان را امکانپذیر سازد در حالی که بار سیستم منبع را کاهش میدهد.
پایپلاین دستهای در مقابل واقعیزمان
پایپلاین دستهای به شما امکان میدهند داده را در قطعات بزرگ در فواصل زمانبندیشده پردازش کنید. چنین خطوط لولهای برای تحلیل دادههای تاریخی و موقعیتهایی که میتوانید تأخیر در ارائه بینشها را تحمل کنید، مناسب است.
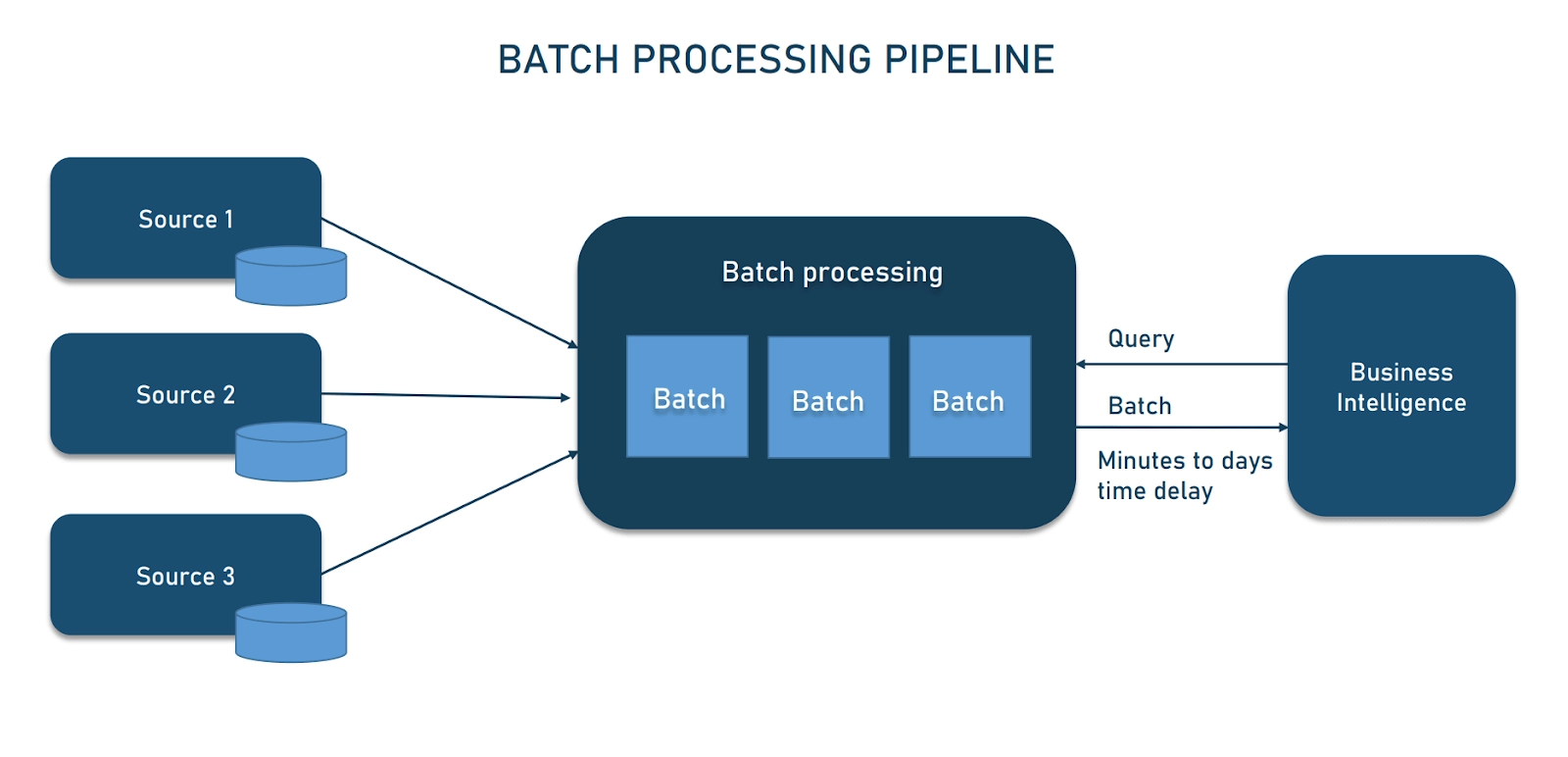
پایپلاین داده واقعیزمان یا جریانی، از سوی دیگر، به شما کمک میکنند داده را به طور مداوم در حالی که تولید میشود مدیریت کنید. اگر مورد استفاده شما نیاز به اقدامات فوری مانند نظارت بر بازارهای مالی دارد، خطوط لوله واقعیزمان انتخاب درستی است. معماریهای جریانی مدرن از پلتفرمهایی مانند Apache Kafka و AWS Kinesis برای امکانپذیر کردن پردازش مبتنی بر رویداد استفاده میکنند که به تغییرات داده در میلیثانیه پاسخ میدهد و سناریوهای محاسبات لبه را پشتیبانی میکند که تحلیل محلی تصمیمات عملیاتی فوری را هدایت میکند.
پایپلاین محلی در مقابل بومی ابری
با خطوط لوله محلی، سازمان شما میتواند داده را در مراکز داده فیزیکی خود ذخیره و پردازش کند. این تنظیم کنترل بیشتری بر داده ارائه میدهد اما میتواند از نظر زمان و هزینه پرمصرف باشد.
برعکس، خطوط لوله بومی ابری برای اجرا کاملاً در پلتفرمهای ابری مانند AWS، Google Cloud یا Microsoft Azure طراحی شدهاند. مزیت اصلی این است که خطوط لوله بومی ابری مقیاسپذیری و ادغام آسان با ابزارهای ابری دیگر را ارائه میدهند. نیازی به نگرانی در مورد مدیریت زیرساخت فیزیکی ندارید، زیرا ارائهدهنده ابر آن را مدیریت میکند. خطوط لوله بومی ابری گزینه عالی است اگر به دنبال کارایی هزینه و میخواهید هزینههای اضافی را به حداقل برسانید. معماریهای بدون سرور مدرن در خطوط لوله بومی ابری منابع را بر اساس تقاضاهای بار کاری به طور خودکار مقیاس میدهند و نیاز به برنامهریزی ظرفیت دستی را حذف میکنند.
چگونه میتوانید اجرای کیفیت داده خودکار و حاکمیت پیشگیرانه را پیادهسازی کنید؟
اتوماسیون پایپلاین داده مدرن فراتر از حرکت داده پایه به شامل اجرای کیفیت جامع و چارچوبهای حاکمیت میرود که یکپارچگی داده را در سراسر جریان کاری تضمین میکند. این رویکرد مدیریت داده واکنشی سنتی را به سیستمهای پیشگیرانه تبدیل میکند که مسائل کیفیت را قبل از تأثیر بر عملیات تجاری جلوگیری میکنند.
اجرای طرح و اعتبارسنجی
اجرای طرح خودکار تغییرات ساختار داده را در واقعیزمان نظارت میکند و تغییرات غیرمنتظره را قبل از انتشار در پایپلاین شما علامتگذاری میکند. ابزارها مدلهای یادگیری ماشین را ادغام میکنند که الگوهای داده تاریخی را تحلیل میکنند تا ناهنجاریها در حجم داده، توزیع یا تازگی را شناسایی کنند که ممکن است مسائل کیفیت را نشان دهد. هنگامی که انحراف طرح رخ میدهد، سیستمهای خودکار میتوانند جریانهای داده آسیبدیده را قرنطینه کنند در حالی که هشدارها را به تیمهای مهندسی فعال میکنند و از دریافت اطلاعات خراب توسط تحلیلهای پاییندستی جلوگیری میکنند.
سیستمهای اعتبارسنجی مدرن فراتر از بررسی نوع پایه به شامل اجرای قوانین تجاری میروند، مانند تضمین اینکه شناسههای مشتری با رکوردهای موجود مطابقت دارند یا تأیید اینکه تراکنشهای مالی در محدودههای مورد انتظار قرار دارند. این اعتبارسنجیها در چندین مرحله پایپلاین رخ میدهند و نقاط بررسی ایجاد میکنند که یکپارچگی داده را از منبع تا مقصد حفظ میکنند.
تشخیص ناهنجاری پیشگیرانه
سیستمهای تشخیص ناهنجاری مبتنی بر یادگیری ماشین به طور مداوم جریانهای داده را تحلیل میکنند تا الگوهایی را شناسایی کنند که از پایههای برقرارشده منحرف میشوند. این سیستمها از دادههای تاریخی یاد میگیرند تا الگوهای عملیاتی عادی را بشناسند و موارد غیرعادی را که ممکن است مسائل کیفیت داده، شکستهای سیستم یا رویدادهای تجاری غیرعادی نیاز به توجه داشته باشند، به طور خودکار علامتگذاری میکنند.
تشخیص ناهنجاری پیشرفته فراتر از آستانههای آماری ساده به درک روابط زمینهای در دادههای شما میرود. برای مثال، سیستم ممکن است بشناسد که حجم سفارشات مشتری معمولاً در دورههای تبلیغاتی افزایش مییابد اما افزایشهای مشابه خارج از زمانهای مورد انتظار را به عنوان مسائل کیفیت داده بالقوه که نیاز به تحقیق دارند، علامتگذاری کند.
اصلاح خودکار و مدیریت خطا
قابلیتهای خودترمیم به خطوط لوله امکان میدهند به مسائل کیفیت داده رایج بدون مداخله دستی پاسخ دهند. هنگامی که سیستم مشکلاتی مانند مقادیر گمشده یا ناسازگاری فرمت را تشخیص میدهد، فرآیندهای اصلاح خودکار میتوانند قوانین تصحیح از پیش تعریفشده را اعمال کنند، دادههای مشکلدار را به مناطق قرنطینه هدایت کنند یا جریانهای کاری پردازش جایگزین را فعال کنند که عملیات پایپلاین را در حالی که مسائل حل میشوند، حفظ میکنند.
این سیستمها ثبت وقایع دقیق از تمام تصحیحهای خودکار را حفظ میکنند و مسیرهای حسابرسی ارائه میدهند که الزامات انطباق را پشتیبانی میکنند در حالی که بهبود مداوم قوانین کیفیت داده را امکانپذیر میسازند. رویههای تشدید خودکار تضمین میکنند که مسائل نیاز به توجه انسانی به طور سریع به اعضای تیم مناسب با زمینه کافی برای حل سریع هدایت شوند.
نسب داده و تحلیل تأثیر
ردیابی نسب داده جامع به طور خودکار سفر کامل عناصر داده از طریق پایپلاین شما را مستند میکند و نقشههای دقیق ایجاد میکند که نشان میدهد چگونه داده منبع به خروجیهای تحلیلی نهایی تحول مییابد. این مستندسازی برای عیبیابی مسائل کیفیت، پشتیبانی از حسابرسیهای انطباق و درک تأثیر بالقوه تغییرات بالادستی بر فرآیندهای تجاری پاییندستی بسیار ارزشمند است.
هنگامی که مسائل کیفیت تشخیص داده میشوند، اطلاعات نسب ارزیابی تأثیر سریع را امکانپذیر میسازد و دقیقاً نشان میدهد که کدام گزارشها، داشبوردها یا فرآیندهای خودکار ممکن است تحت تأثیر قرار گیرند. این دید به تیمها اجازه میدهد تلاشهای اصلاح را اولویتبندی کنند و تأثیرات بالقوه را به ذینفعان تجاری قبل از تأثیر بر عملیات حیاتی ارتباط دهند.
نقش هماهنگی پویای پایپلاین مبتنی بر هوش مصنوعی در اتوماسیون مدرن چیست؟
هوش مصنوعی از یک ابزار کمکی به یک مؤلفه اساسی اتوماسیون پایپلاین داده مدرن تکامل یافته است و سیستمهایی را امکانپذیر میسازد که خودبهینهسازی میکنند، شکستها را پیشبینی میکنند و بدون مداخله دستی با الزامات تجاری در حال تغییر سازگار میشوند. این نشاندهنده تغییر اساسی از خطوط لوله ایستا مبتنی بر قانون به سیستمهای هوشمند است که عملکرد خود را به طور مداوم بهبود میبخشند.
نگهداری پیشبینیکننده و جلوگیری از شکست
نگهداری پیشبینیکننده مبتنی بر هوش مصنوعی دادههای عملکرد پایپلاین تاریخی، معیارهای سیستم و عوامل خارجی را تحلیل میکند تا شکستهای بالقوه را قبل از وقوع پیشبینی کند. مدلهای یادگیری ماشین الگوهایی را شناسایی میکنند که قبل از مسائل رایج مانند گلوگاههای منابع، زمانهای انقضای اتصال یا کاهش کیفیت داده رخ میدهند و مداخلات پیشگیرانه را امکانپذیر میسازند که اختلالات پایپلاین را جلوگیری میکنند.
این سیستمها فراتر از نظارت آستانه ساده به درک روابط پیچیده بین مؤلفههای سیستم، الگوهای بار کاری و وابستگیهای خارجی میروند. برای مثال، مدلهای پیشبینیکننده ممکن است بشناسند که منابع رابط برنامهنویسی کاربردی خاص در دورههای زمانی خاص غیرقابل اعتماد میشوند و منطق تلاش مجدد را به طور خودکار تنظیم کنند یا به منابع داده جایگزین سوئیچ کنند تا قابلیت اعتماد پایپلاین را حفظ کنند.
نگهداری پیشبینیکننده پیشرفته همچنین تخصیص منابع را با پیشبینی الزامات محاسباتی و ذخیرهسازی بر اساس الگوهای تاریخی و رویدادهای تجاری پیشرو بهینه میکند. این قابلیت تضمین میکند که منابع کافی در دورههای پردازش اوج در دسترس باشد در حالی که از تأمین بیش از حد در فواصل تقاضای پایین اجتناب میکند.
هوش مصنوعی تولیدی برای توسعه پایپلاین
ابزارهای هوش مصنوعی تولیدی اکنون بخشهای قابل توجهی از توسعه پایپلاین را اتوماتیک میکنند و کد بهینهشده برای وظایف استخراج-تحول-بارگذاری رایج ایجاد میکنند و بهبودهایی را به جریانهای کاری موجود پیشنهاد میدهند. این سیستمها الزامات تجاری بیانشده در زبان طبیعی را تحلیل میکنند و پیکربندیهای پایپلاین مناسب، منطق تحول و رویههای مدیریت خطا را تولید میکنند که به طور سنتی نیاز به کدگذاری دستی گسترده دارند.
تولید کد مبتنی بر هوش مصنوعی به توسعه اتصالدهنده گسترش مییابد، جایی که سیستمها میتوانند مستندات رابط برنامهنویسی کاربردی و دادههای نمونه را تحلیل کنند تا منطق ادغام را برای منابع داده جدید به طور خودکار ایجاد کنند. این قابلیت زمان لازم برای وارد کردن منابع داده جدید را به طور چشمگیری کاهش میدهد در حالی که کیفیت مداوم و مدیریت خطا در تمام مؤلفههای پایپلاین را تضمین میکند.
مدیریت عملکرد خودبهینهسازی
الگوریتمهای یادگیری ماشین به طور مداوم معیارهای عملکرد پایپلاین را نظارت میکنند تا فرصتهای بهینهسازی را شناسایی کنند و بهبودها را به طور خودکار پیادهسازی کنند. این سیستمها عواملی مانند الگوهای حجم داده، پیچیدگی تحول و استفاده از منابع را تحلیل میکنند تا پارامترهای پردازش را برای عملکرد بهینه به طور پویا تنظیم کنند.
سیستمهای خودبهینهسازی میتوانند وظایف پردازش داده را به طور خودکار دوباره تقسیم کنند، تنظیمات موازیسازی را تنظیم کنند و تخصیص منابع را بر اساس بازخورد عملکرد واقعیزمان تغییر دهند. این بهینهسازی مداوم تضمین میکند که خطوط لوله کارایی اوج را با رشد حجمهای داده و تکامل الزامات تجاری حفظ کنند و نیاز به تنظیم عملکرد دستی را کاهش دهند.
حل خطای هوشمند و تحلیل علت ریشهای
سیستمهای حل خطای مبتنی بر هوش مصنوعی شکستهای پایپلاین را با استفاده از پردازش زبان طبیعی برای تفسیر پیامهای خطا، ثبت وقایع سیستم و زمینه عملیاتی تحلیل میکنند. این سیستمها میتوانند مسائل رایج را به طور خودکار تشخیص دهند و استراتژیهای اصلاح مناسب را اعمال کنند، مانند تنظیم تنظیمات زمان انقضا، تلاش مجدد عملیات شکستخورده با پارامترهای تغییر یافته یا هدایت داده از طریق مسیرهای پردازش جایگزین.
تحلیل علت ریشهای پیشرفته چندین منبع داده را ترکیب میکند تا عوامل زیربنایی مؤثر بر مسائل پایپلاین را درک کند. سیستم ممکن است شکستهای پایپلاین را با رویدادهای خارجی مانند تغییرات رابط برنامهنویسی کاربردی، بهروزرسانیهای زیرساخت یا الگوهای داده غیرعادی همبسته کند تا توضیحات جامع ارائه دهد که راهحلهای بلندمدت مؤثرتر را امکانپذیر سازد.
چرا باید پایپلاین داده را اتوماتیک کنید؟
انتقال داده به طور دستی در سراسر سیستمها نه تنها پرزحمت است بلکه احتمال اشتباهات را افزایش میدهد. با رشد کسبوکار شما، مقدار داده نیز افزایش مییابد و وظیفه مدیریت آن میتواند چالشبرانگیزتر باشد. تلاش برای مدیریت این فرآیند پیچیده ممکن است به ناسازگاریها، تأخیرها و خطاها در داده منجر شود.
اتوماتیک کردن خطوط لوله داده شما جمعآوری، پاکسازی و حرکت داده از منبع تا مقصد نهایی را ساده میکند. با اتوماتیک کردن جریانهای کاری، زمان صرفشده بر وظایف مدیریت داده را کاهش میدهید و بر فعالیتهای استراتژیکتر تمرکز میکنید. این کارایی عملیاتی را بهبود میبخشد و دقت و قابلیت اعتماد داده را تضمین میکند.
اتوماسیون مدرن از هوش مصنوعی و یادگیری ماشین برای ایجاد سیستمهای خودبهینهسازی استفاده میکند که با الگوهای داده در حال تغییر و الزامات تجاری سازگار میشوند. این خطوط لوله هوشمند میتوانند مسائل بالقوه را پیشبینی کنند، منابع را بر اساس تقاضا به طور خودکار مقیاس کنند و اقدامات اصلاحی را بدون مداخله انسانی پیادهسازی کنند و زیرساخت داده را از یک بار نگهداری به یک مزیت رقابتی تبدیل کنند.
مزایای کلیدی اتوماسیون پایپلاین داده چیست؟
- بهبود کیفیت داده: اتوماسیون خطر خطاهای انسانی ذاتی در پردازش دستی را کاهش میدهد و تضمین میکند که داده به طور مداوم پاکسازی، قالببندی و اعتبارسنجی شود. سیستمهای خودکار پیشرفته نظارت و قوانین اعتبارسنجی مداوم را پیادهسازی میکنند که مسائل کیفیت داده را قبل از تأثیر بر تحلیلهای پاییندستی یا فرآیندهای تجاری شناسایی میکنند.
- اجازه تصمیمگیری سریعتر: خطوط لوله خودکار داده را به طور بیدردسر از منبع به برنامههای پاییندستی حرکت میدهند و تصمیمات تجاری بهموقع را امکانپذیر میسازند. قابلیتهای پردازش واقعیزمان تضمین میکنند که سیستمهای هوش تجاری اطلاعات بهروز را در دقیقهها یا ثانیههای تولید داده دریافت کنند و پاسخ سریع به تغییرات بازار یا مسائل عملیاتی را پشتیبانی کنند.
- گرفتن تغییرات داده: ادغام فناوری گرفتن تغییرات داده در پایپلاین خودکار داده را در چندین پایگاه داده همگام نگه میدارد. این قابلیت تضمین میکند که بهروزرسانیها، درجها و حذفها در سیستمهای منبع به طور دقیق در سیستمهای مقصد منعکس شوند و ثبات داده را در معماریهای توزیعشده حفظ کنند.
- مقیاسپذیری: خطوط لوله خودکار با مقیاس افقی یا عمودی به بارهای کاری رو به رشد سازگار میشوند و استفاده از منابع را بهینه میکنند. راهحلهای بومی ابری مدرن میتوانند منابع محاسباتی اضافی را در دورههای پردازش اوج به طور خودکار تأمین کنند و در فواصل تقاضای پایین کاهش دهند و عملیات مقرون enduring به صرفه را صرفنظر از نوسانات حجم داده تضمین کنند.
- کاهش هزینه: اتوماسیون وابستگی به کار دستی را به حداقل میرساند، هزینههای نیروی کار را کاهش میدهد و خطر خطاهای گران را کم میکند. با حذف وظایف دستی تکراری و کاهش نیاز به نگهداری فنی تخصصی، سازمانها میتوانند منابع انسانی را به سمت فعالیتهای با ارزش بالاتر مانند تحلیل پیشرفته و ابتکارات داده استراتژیک هدایت کنند.
کدام ابزارها برای اتوماسیون پایپلاین داده بهترین هستند؟
۱. Airbyte
Airbyte به عنوان یک پلتفرم ادغام داده جامع برجسته است که انعطافپذیری منبعباز را با قابلیتهای درجه سازمانی ترکیب میکند. پلتفرم بیش از ۲ پتابایت داده را روزانه در استقرارهای مشتری پردازش میکند و سازمانها را از استارتاپهای رو به رشد سریع تا شرکتهای ۵۰۰ Fortune در ابتکارات مدرنسازی زیرساختشان پشتیبانی میکند.
ویژگیهای کلیدی شامل:
- ساخت اتصالدهندههای سفارشی: از سازنده اتصالدهنده بدون کد یا کیتهای توسعه اتصالدهنده کمکد/زبانمحور برای توسعه اتصالدهندههای سفارشی استفاده کنید، با کمک پیشنهادهای هوش مصنوعی. کیت توسعه اتصالدهنده پلتفرم ایجاد سریع ادغامهای سفارشی را در حالی که قابلیت اعتماد و استانداردهای عملکرد درجه سازمانی را حفظ میکند، امکانپذیر میسازد.
- سادهسازی جریانهای کاری هوش مصنوعی: دادههای نیمهساختیافته یا بدون ساختار را به پایگاههای داده برداری محبوب مانند Chroma، Pinecone یا Qdrant با قطعهبندی، جاسازی و نمایهسازی خودکار حرکت دهید. این قابلیت برنامههای هوش مصنوعی و یادگیری ماشین مدرن را که نیاز به پردازش داده ساختیافته همراه با تحلیل محتوای بدون ساختار دارند، پشتیبانی میکند.
- پایپلاین دوستانه توسعهدهنده: PyAirbyte، یک کتابخانه پایتون منبعباز، به شما اجازه میدهد داده را با اتصالدهندههای Airbyte استخراج کنید و آن را به حافظههای موقت مانند Snowflake، DuckDB یا BigQuery بارگذاری کنید. این ابزار برای برنامههای تحلیلی و مدلهای زبان بزرگ ایدهآل است و به توسعهدهندگان اجازه میدهد برنامههای مبتنی بر داده را به سرعت بسازند در حالی که سازگاری با زیرساخت داده سازمانی را حفظ میکنند.
- استقرار چندمنطقهای: مشتریان سازمانی میتوانند صفحات داده را در چندین منطقه مستقر کنند در حالی که حاکمیت متمرکز را از طریق یک صفحه کنترل واحد حفظ میکنند و انطباق با الزامات حاکمیت داده را تضمین میکنند در حالی که برای عملکرد و هزینه بهینهسازی میکنند.
- مدیریت پیشرفته فایل: پشتیبانی از انتقال دادههای بدون ساختار تا ۱ گیگابایت با تولید متاداده خودکار، امکانپذیر کردن خطوط لوله ترکیبی که تحلیل ساختیافته را با جریانهای کاری پردازش سند و رسانه ترکیب میکنند.
۲. Google Cloud Dataflow
Google Cloud Dataflow قابلیتهای پردازش دستهای و جریانی بدون سرور ارائه میدهد که بر اساس تقاضاهای بار کاری به طور خودکار مقیاس میکنند. پلتفرم در مدیریت هر دو جریانهای داده واقعیزمان و عملیات دستهای در مقیاس بزرگ در اکوسیستم Google Cloud برتری دارد.
- قابل حمل: بر اساس Apache Beam ساخته شده، بنابراین خطوط لوله توسعهیافته برای Dataflow میتوانند روی اجراکنندههای دیگر مانند Apache Flink یا Spark اجرا شوند. این قابلیت حمل تضمین میکند که سرمایهگذاریها در توسعه پایپلاین حتی اگر الزامات زیرساخت زیربنایی در طول زمان تغییر کند، ارزشمند باقی بماند.
- پردازش دقیقاً یکبار: تضمین میکند که هر رکورد یک بار پردازش شود به طور پیشفرض و دقت را تضمین میکند؛ معناشناسی حداقل یکبار نیز برای نیازهای تأخیر کمتر و مقرون به صرفه در دسترس است. این ویژگی قابلیت اعتماد برای تراکنشهای مالی، مدیریت موجودی و سایر سناریوهای پردازش داده حیاتی تجاری ضروری است.
۳. Apache Airflow
Apache Airflow به عنوان یک پلتفرم هماهنگی جریان کاری قدرتمند عمل میکند که مدیریت پیچیده پایپلاین داده را از طریق تعریف برنامهریزیشده جریان کاری و نظارت امکانپذیر میسازد. پلتفرم در هماهنگی وابستگیها بین چندین وظیفه پردازش داده و سیستمهای خارجی برتری دارد.
- گرافهای جهتدار بدون چرخه: جریانهای کاری را به عنوان گرافهای جهتدار بدون چرخه تعریف کنید و وابستگیهای وظیفه و زمانبندی را واضح کنید. این رویکرد نمای بصری از جریانهای کاری داده پیچیده ارائه میدهد در حالی که تضمین میکند مراحل پردازش به ترتیب صحیح اجرا شوند و شکستها را به طور ظریف مدیریت کنند.
- انتزاع ذخیرهسازی شیء: پشتیبانی یکپارچه برای S3، GCS، Azure Blob Storage و بیشتر بدون نیاز به تغییرات کد برای هر سرویس. این انتزاع استقرارهای چندابری را ساده میکند و قابلیت حمل پایپلاین را در محیطهای زیرساختی مختلف امکانپذیر میسازد.
پرسشهای متداول
پایپلاین داده خودکار چگونه پردازش داده واقعیزمان را مدیریت میکنند؟
پایپلاین داده خودکار از معماریهای جریانی و ابزارهایی مانند Apache Kafka، Flink یا AWS Kinesis برای ورود، تحول و تحویل داده در واقعیزمان استفاده میکنند. این تحلیل و پاسخ فوری را برای موارد استفاده مانند تشخیص تقلب، قیمتگذاری پویا و نظارت عملیاتی امکانپذیر میسازد.
ملاحظات امنیتی اصلی برای پایپلاین داده خودکار چیست؟
پایپلاین خودکار را با رمزنگاری انتها به انتها، دسترسی مبتنی بر نقش، ثبت وقایع حسابرسی و پنهانسازی داده ایمن کنید. امنیت شبکه، مدیریت اعتبارنامه ایمن، انطباق با مقررات مانند GDPR/HIPAA، اسکنهای امنیتی خودکار و ارزیابیهای منظم را پیادهسازی کنید تا داده را در سراسر ورود، پردازش و ذخیره محافظت کنید.
چگونه موفقیت اتوماسیون پایپلاین داده را اندازهگیری میکنید؟
موفقیت پایپلاین خودکار را با استفاده از قابلیت اعتماد، نرخ خطا، کیفیت داده، سرعت پردازش، توان عملیاتی و کارایی هزینه اندازهگیری کنید. همچنین تأثیر تجاری، از جمله تصمیمگیری سریعتر، دسترسی بهبودیافته به داده و بهرهوری تیم را پیگیری کنید. نظارت و بررسیهای منظم بهینهسازی مداوم و همراستایی با اهداف را تضمین میکنند.
چه چالشهایی باید هنگام پیادهسازی خطوط لوله داده خودکار انتظار داشته باشید؟
چالشهای پایپلاین خودکار شامل مسائل کیفیت داده، تغییرات طرح، ادغام سیستمهای قدیمی، مقیاسبندی در بارهای اوج و شکافهای مهارتی است. سازمانها همچنین باید مقاومت در برابر تغییر و تعادل حاکمیت را مدیریت کنند و اینها را از طریق برنامهریزی، آموزش ذینفعان، پیادهسازی مرحلهای و نظارت قوی برطرف کنند.
پایپلاین داده خودکار چگونه الزامات انطباق و حاکمیت را پشتیبانی میکنند؟
پایپلاین خودکار با نسب داده داخلی، ثبت وقایع حسابرسی و اجرای سیاست انطباق را بهبود میبخشند. آنها پنهانسازی، نگهداری و کنترلهای دسترسی را بر اساس مقررات به طور خودکار اعمال میکنند، در حالی که پلتفرمهای مدرن نظارت و گزارشدهی را برای اثبات انطباق و حفظ رکوردهای آماده حسابرسی ارائه میدهند.
نتیجهگیری
اتوماسیون پایپلاین داده برای کسبوکارهایی که به دنبال سادهسازی پردازش داده، بهبود کارایی عملیاتی و حفظ ثبات داده هستند، حیاتی است. اتوماسیون وظایف دستی را کاهش میدهد، با حجمهای داده رو به رشد مقیاس میکند و ادغام، تحول و حرکت کارآمد داده در سراسر سیستمها را تضمین میکند. خطوط لوله خودکار مدرن از هوش مصنوعی برای نگهداری پیشبینیکننده استفاده میکنند، اجرای کیفیت داده جامع را پیادهسازی میکنند و انعطافپذیری لازم برای سازگاری با الزامات تجاری در حال تغییر را ارائه میدهند.
با انتخاب ابزارهای مناسب و پیکربندی خطوط لوله برای نیازهای خاص، سازمانها میتوانند بر استخراج بینش و ایجاد ارزش از دادههایشان تمرکز کنند. ترکیب اجرای کیفیت خودکار، هماهنگی مبتنی بر هوش مصنوعی و قابلیتهای نظارت قوی، زیرساخت داده را از بار نگهداری به مزیت رقابتی تبدیل میکند که تصمیمگیری سریعتر و نتایج تجاری بهبودیافته را امکانپذیر میسازد.