
تصمیمگیریهای پردازش داده به طور فزایندهای پیچیده شده است زیرا سازمانها نیاز به تحلیل جامع را با تقاضا برای بینشهای واقعیزمان متعادل میکنند. رشد نمایی تولید داده به این معناست که کسبوکارها دیگر نمیتوانند تنها به رویکردهای سنتی تکیه کنند، بلکه باید به طور استراتژیک بین پردازش دستهای و پردازش جریانی انتخاب کنند یا معماریهای ترکیبی پیچیدهای را پیادهسازی کنند که هر دو پارادایم را به طور مؤثر بهرهبرداری میکنند.
در این راهنمای جامع، تفاوتهای اساسی بین پردازش دستهای در مقابل پردازش جریانی را کاوش خواهید کرد، درک خواهید کرد که هر رویکرد چه زمانی ارزش بهینه ارائه میدهد و کشف خواهید کرد که چگونه پلتفرمهای مدرن چالشهای منحصر به فرد سازمانها را هنگام پیادهسازی این استراتژیهای پردازش داده در مقیاس حل میکنند.
پردازش دستهای چیست؟
پردازش دستهای به شما اجازه میدهد داده را در دورههای خاص جمعآوری کنید و آن را به صورت عمده در فواصل زمانبندیشده پردازش کنید. این رویکرد مجموعههای داده بزرگ را به دستهها گروهبندی میکند و آنها را در پنجرههای زمانی از پیش تعیینشده مدیریت میکند، معمولاً در ساعات غیراوج زمانی که منابع سیستم به راحتی در دسترس هستند و سیستمهای عملیاتی بار کمی تجربه میکنند.
روششناسی پردازش دستهای به ویژه برای سناریوهایی که نیاز به تحلیل جامع داده، تحولات پیچیده و پردازش داده با حجم بالا دارند، ارزشمند است، جایی که تأخیرهای جزئی در ازای کارایی پردازش و بهینهسازی منابع قابل قبول است. سازمانها اغلب از پردازش دستهای برای گزارشگیری نظارتی، عملیات انبار داده و بارهای کاری تحلیلی که از دسترسی به مجموعههای داده کامل بهره میبرند، استفاده میکنند.
پردازش دستهای چگونه کار میکند؟
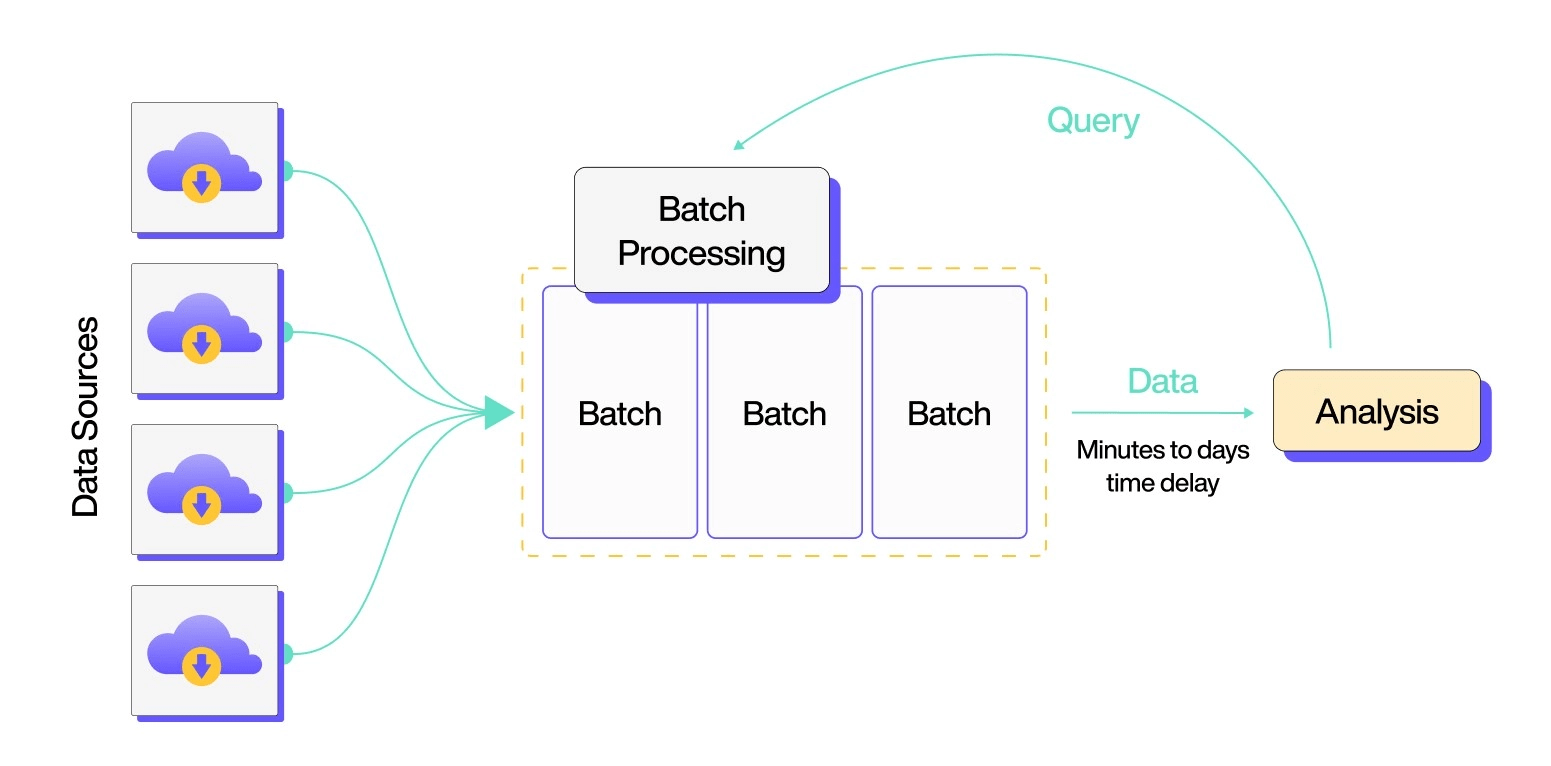
۱. جمعآوری داده: مجموعههای داده بزرگ را از منابع متنوع مانند پایگاههای داده، ثبت وقایع، حسگرها یا تراکنشها جمعآوری کنید و آنها را در یک سیستم موقت ذخیره کنید.
۲. گروهبندی: تعیین کنید چگونه و چه زمانی داده را پردازش کنید با گروهبندی وظایف یا شغلهای مرتبط به دستهها بر اساس منطق تجاری یا الزامات پردازش.
۳. زمانبندی: این دستهها را برای اجرا در زمانهای تعریفشده، مانند شبانه یا در ساعات ترافیک پایین، زمانبندی کنید تا استفاده از منابع را بهینه کنید و تأثیر بر سیستمهای عملیاتی را به حداقل برسانید.
۴. پردازش: بسته به ظرفیت سیستم، دستهها به صورت متوالی یا موازی با استفاده از چارچوبهای محاسباتی توزیعشده که میتوانند تحولات داده در مقیاس بزرگ را مدیریت کنند، پردازش میشوند.
۵. نتایج: پس از پردازش، نتایج در پایگاههای داده یا انبارهای داده ذخیره میشوند و میتوانند در داشبوردها، ابزارهای هوش تجاری یا برنامههای پاییندستی برای تحلیل و تصمیمگیری ظاهر شوند.
مزایای پردازش دستهای چیست؟
پردازش دستهای کیفیت داده را با اجازه دادن به فرآیندهای اعتبارسنجی جامع، از جمله حذف تکراریها، بررسی مقادیر گمشده و تأیید ثبات داده در منطقه موقت قبل از اجرا، بهبود میبخشد. این اعتبارسنجی کامل تضمین میکند که سیستمهای پاییندستی داده پاک، قابل اعتماد و مطابق با استانداردهای کیفیت سازمانی دریافت کنند.
شغلها میتوانند در پسزمینه یا در ساعات غیراوج اجرا شوند و اختلالات در فعالیتهای تجاری واقعیزمان را جلوگیری کنند در حالی که هزینههای منابع را بهینه میکنند. این قابلیت پردازش آفلاین به سازمانها اجازه میدهد منابع محاسباتی موجود را به طور کارآمد بهرهبرداری کنند در حالی که عملکرد سیستم عملیاتی را در ساعات تجاری حیاتی حفظ میکنند.
بهینهسازی منابع از طریق پردازش عمده، توان عملیاتی بالاتر و استفاده کارآمدتر از منابع محاسباتی در مقایسه با پردازش رکوردهای فردی را امکانپذیر میسازد. رویکرد دستهای به سیستمها اجازه میدهد استفاده از حافظه، عملیات ورودی/خروجی دیسک و استفاده از شبکه را با پردازش حجمهای بزرگ داده به طور همزمان بهینه کنند.
محدودیتهای پردازش دستهای چیست؟
پردازش دستهای برای تغییرات کوچک کارآمد نیست زیرا اگر تنها چند رکورد نیاز به تغییر داشته باشند، کل دسته همچنان اجرا میشود و ممکن است منابع محاسباتی را هدر دهد و هزینههای پردازش را به طور غیرضروری افزایش دهد.
پس از شروع یک شغل دستهای، تغییر یا متوقف کردن آن در میانه راه دشوار است و منجر به عدم انعطافپذیری برای بهروزرسانیهای سریع یا مدیریت خطا میشود. این عدم انعطافپذیری میتواند چالشهایی ایجاد کند زمانی که الزامات تجاری تغییر میکنند یا خطاهای پردازش نیاز به اصلاح فوری دارند.
تأخیر ذاتی در پردازش دستهای به این معناست که بینشها و نتایج تنها پس از تکمیل دسته در دسترس هستند، که ممکن است الزامات برنامههای تجاری حساس به زمان یا سناریوهای تصمیمگیری واقعیزمان را برآورده نکند.
پردازش جریانی چیست؟
پردازش جریانی به پردازش داده در واقعیزمان به محض ایجاد اشاره دارد و بینشهای فوری و پاسخ سریع به شرایط تجاری در حال تغییر را امکانپذیر میسازد. این رویکرد داده را به طور مداوم از طریق معماریهای مبتنی بر رویداد مدیریت میکند که نقاط داده فردی یا دستههای کوچک را به محض ورود به سیستم پردازش میکند.
میتوانید از پردازش جریانی برای برنامههایی که نیاز به بهروزرسانیهای فوری دارند، مانند تحلیل واقعیزمان، سیستمهای تجارت مالی، تشخیص تقلب و موتورهای توصیه زنده استفاده کنید. پردازش جریانی روی جریانهای داده مداوم کار میکند و به سیستمهای تأخیر پایین وابسته است تا جریانهای داده با سرعت بالا را مدیریت کند در حالی که عملکرد ثابتی در محیطهای پردازش توزیعشده حفظ میکند.
قابلیتهای پردازش واقعیزمان میتواند از میلیثانیه تا دقیقه متغیر باشد، بسته به الزامات برنامه و معماری سیستم. چارچوبهای پردازش جریانی مدرن ویژگیهای پیچیدهای از جمله عملیات پنجرهای، مدیریت حالت و تضمینهای پردازش دقیقاً یکبار ارائه میدهند که سناریوهای پردازش رویداد پیچیده را امکانپذیر میسازند.
پردازش جریانی چگونه کار میکند؟
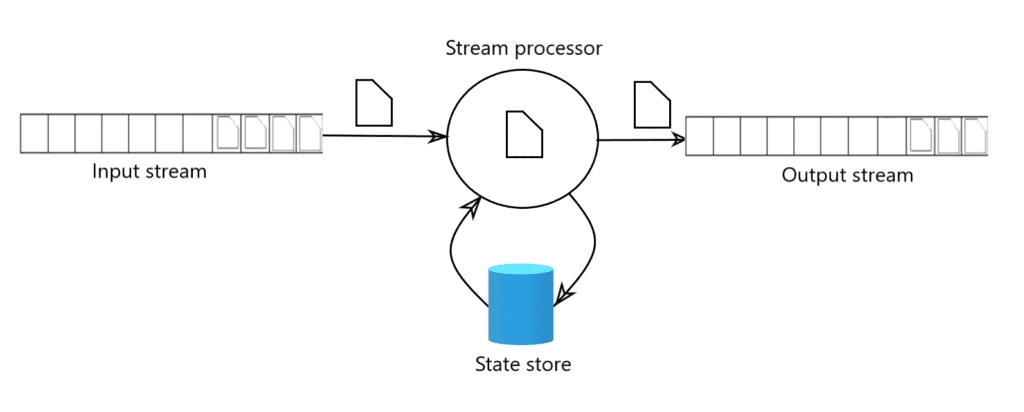
۱. جریان ورودی: داده به طور مداوم از چندین منبع، از جمله حسگرها، ثبت وقایع برنامه، فیدهای رسانههای اجتماعی و سیستمهای تراکنش تولید میشود و مستقیماً به موتورهای پردازش جریانی بدون ذخیره میانی جریان مییابد.
۲. پردازش جریانی: به محض ورود داده، در واقعیزمان با استفاده از الگوریتمهای پیچیده که میتوانند تجمیعها، جوینها و تحولات را انجام دهند در حالی که تأخیر پایین و توان عملیاتی بالا را حفظ میکنند، پردازش میشود.
۳. جریان خروجی: پس از پردازش، داده بلافاصله به مقاصدی مانند پایگاههای داده، انبارهای داده، سیستمهای پیامرسانی یا پلتفرمهای تحلیلی ارسال میشود، جایی که میتواند اقدامات یا بهروزرسانیهای فوری را trigger کند.
مزایای پردازش جریانی چیست؟
پردازش حالتدار زمینهای مانند الگوهای فعالیت کاربر و تحلیل روند را از طریق فروشگاههای حالت حفظ میکند و تصمیمگیریهای واقعیزمان پیچیدهتر را که الگوهای تاریخی و رویدادهای فعلی را همزمان در نظر میگیرند، امکانپذیر میسازد.
معماری مبتنی بر رویداد تضمین میکند که رویدادها به محض وقوع پردازش میشوند و پاسخهای تأخیر پایین را ارائه میدهند که واکنشهای تجاری فوری به شرایط در حال تغییر را امکانپذیر میسازند. این پاسخگویی برای برنامههایی مانند تشخیص تقلب، سیستمهای توصیه و نظارت عملیاتی حیاتی است.
پردازش مداوم بینشها و اقدامات فوری بر اساس داده فعلی را امکانپذیر میسازد و موارد استفاده را پشتیبانی میکند که در آن پاسخهای تأخیری میتواند منجر به فرصتهای از دست رفته یا تأثیر تجاری منفی شود. قابلیتهای پردازش واقعیزمان به سازمانها اجازه میدهد به تغییرات بازار، رفتار مشتری و شرایط عملیاتی به محض وقوع پاسخ دهند.
محدودیتهای پردازش جریانی چیست؟
پذیرش پردازش جریانی نیاز به تخصص در معماری سیستمهای توزیعشده واقعیزمان دارد و بدون دانش کافی، تیمها با مدیریت ثبات، بهینهسازی مقیاس و تنظیم عملکرد در محیطهای توزیعشده پیچیده مبارزه میکنند.
پردازش مداوم منابع محاسباتی ثابت را تقاضا میکند و منجر به استفاده بالاتر از پردازنده مرکزی و حافظه در مقایسه با پردازش دستهای میشود. طبیعت همیشه روشن سیستمهای جریانی میتواند منجر به هزینههای زیرساخت افزایشیافته شود، به ویژه در دورههای حجم داده پایین.
پیچیدگی در مدیریت خطا و تحمل خطا به طور قابل توجهی در محیطهای جریانی افزایش مییابد جایی که شکستها باید بدون جریانهای داده مداوم مدیریت شوند. سازمانها باید مکانیسمهای بازیابی پیچیده و استراتژیهای تشخیص تکراری را پیادهسازی کنند تا یکپارچگی داده را حفظ کنند.
تفاوتهای کلیدی بین پردازش دستهای و پردازش جریانی چیست؟
| جنبه | پردازش دستهای | پردازش جریانی |
|---|---|---|
| حالت پردازش داده | مجموعههای داده بزرگ در فواصل از پیش تعریفشده پردازش میشوند | نقاط داده فردی به محض ورود مدیریت میشوند |
| سرعت خروجی | نتایج پس از تکمیل دسته در دسترس هستند | خروجیها در واقعیزمان تولید میشوند |
| استفاده از حافظه | وابسته به ذخیره دیسک؛ نیاز به رم کمتر | استفاده بالا از حافظه برای پردازش فوری |
| ذخیره | داده تا زمان اجرای دسته ذخیره میشود | تنها پنجرههای کوچک در حین پردازش ذخیره میشوند |
| انواع داده پشتیبانیشده | ساختیافته، نیمهساختیافته و بدون ساختار (بسته به قابلیتهای چارچوب) | ساختیافته، نیمهساختیافته (مستقیم)؛ بدون ساختار (با پیشپردازش یا تحول) |
| پیچیدگی سیستم | معماری سادهتر؛ پردازش مجموعههای داده ایستا | پیچیدهتر به دلیل محدودیتهای واقعیزمان |
| مدیریت خطا | خطاها پس از پردازش یافت میشوند؛ ممکن است نیاز به اجرای مجدد داشته باشد | خطاها فوراً مدیریت میشوند تا اختلال جلوگیری شود |
| کیفیت داده | کامل و دقیق در زمان پردازش | ممکن است رویدادهای خارج از ترتیب یا ناقص داشته باشد |
| مناسب برای هوش تجاری | ایدهآل برای گزارشهای دورهای و داشبوردها | بهترین برای تحلیل پویا نیاز به بینشهای سریع |
چگونه بین پردازش دستهای و پردازش جریانی انتخاب کنید؟
فراتر از این تفاوتهای اساسی، چندین عامل اضافی بر انتخاب بین رویکردهای پردازش دستهای و جریانی تأثیر میگذارد:
معماری ورود داده
پردازش دستهای از رویکردهای ورود زمانبندیشده استفاده میکند، اغلب با ابزارهایی مانند Airbyte یا AWS Batch پیادهسازی میشود تا حجمهای بالا داده را در فواصل خاص جمعآوری کند. این رویکرد بهینهسازی پهنای باند شبکه و منابع سیستم را امکانپذیر میسازد در حالی که فرآیندهای اعتبارسنجی و تحول داده پیچیده را پشتیبانی میکند.
پردازش جریانی به صفهای رویداد واقعیزمان و کارگزاران پیام وابسته است و الگوهای معماری ورود داده را با چارچوبهایی مانند Apache Flink، Apache Kafka یا Spark Streaming پیادهسازی میکند. این سیستمها باید جریانهای داده مداوم را مدیریت کنند در حالی که تأخیر پایین و دسترسی بالا را در محیطهای پردازش توزیعشده حفظ میکنند.
مکانیسمهای تحمل خطا
شغلهای دستهای میتوانند از آخرین حالت ذخیرهشده retry یا re-run شوند و مکانیسمهای بازیابی ساده ارائه میدهند که نیاز به هماهنگی واقعیزمان ندارند. قابلیتهای نقطه بررسی و restart به سیستمهای دستهای اجازه میدهد از شکستها بدون از دست دادن پیشرفت پردازش قابل توجه بازیابی کنند.
سیستمهای جریانی نیاز به تحمل خطا فوری از طریق نقطه بررسی توزیعشده، پردازش مجدد رویداد و تکثیر حالت در حالی که تأخیر پایین را حفظ میکنند، دارند. این سیستمها باید مکانیسمهای بازیابی پیچیدهای پیادهسازی کنند که شکستها را بدون جریانهای داده مداوم یا باعث از دست رفتن داده مدیریت کنند.
ویژگیهای توان عملیاتی
پردازش دستهای قابلیتهای توان عملیاتی بالا ارائه میدهد اما با تأخیرهای پردازش ذاتی که ممکن است از دقیقه تا ساعت متغیر باشد، بسته به اندازه دسته و زمانبندی. رویکرد پردازش عمده استفاده کارآمد از منابع و استراتژیهای بهینهسازی را امکانپذیر میسازد که نرخهای پردازش داده را حداکثر میکنند.
پردازش جریانی قطعات داده کوچکتر را به طور مداوم مدیریت میکند و حفظ توان عملیاتی بالا در حالی که الزامات تأخیر پایین را برآورده میکند، چالشبرانگیزتر است. طبیعت واقعیزمان نیاز به بهینهسازی دقیق الگوریتمهای پردازش و تخصیص منابع برای دستیابی به سطوح عملکرد قابل قبول دارد.
ملاحظات هزینه
پردازش دستهای پردازش عمده را در ساعات غیراوج امکانپذیر میسازد و هزینههای زیرساخت را از طریق استفاده کارآمد از منابع و بهینهسازی زمانبندی کاهش میدهد. سازمانها میتوانند از قیمتگذاری spot برای منابع ابری بهره ببرند و هزینههای محاسباتی را با پردازش در دورههای تقاضای پایین بهینه کنند.
پردازش جریانی منابع محاسباتی و شبکه مداوم را نیاز دارد و معمولاً منجر به هزینههای عملیاتی بالاتر به دلیل طبیعت همیشه روشن سیستمهای پردازش واقعیزمان میشود. با این حال، این هزینهها ممکن است با ارزش تجاری بینشهای فوری و قابلیتهای پاسخ سریع توجیه شود.
چه زمانی باید پردازش داده دستهای را انتخاب کنید؟
پردازش دستهای بیشترین اثربخشی را برای سناریوهایی که نیاز به تحلیل جامع داده، کارایی پردازش حجم بالا و موقعیتهایی که تأخیرهای پردازش جزئی در ازای دقت و بهینهسازی منابع قابل قبول است، ثابت میکند. درک این موارد استفاده خاص به سازمانها کمک میکند تصمیمات آگاهانهای در مورد زمانی که پردازش دستهای ارزش بهینه ارائه میدهد، بگیرند.
- گزارشگیری نظارتی و انطباق: مؤسسات مالی، سازمانهای مراقبتهای بهداشتی و سایر صنایع تنظیمشده از پردازش دستهای برای گزارشگیری انطباق جامع که نیاز به تحلیل مجموعه داده کامل، رویههای اعتبارسنجی پیچیده و تولید مسیر حسابرسی دارد، بهره میبرند. صورتهای مالی ماهانه، پروندههای نظارتی و نظارت انطباق معمولاً روی زمانبندیهای از پیش تعیینشده عمل میکنند که با قابلیتهای پردازش دستهای همراستا هستند.
- انبار داده و هوش تجاری: سازمانهایی که استراتژیهای هوش تجاری جامع پیادهسازی میکنند از پردازش دستهای برای بارگذاری انبار داده، محاسبات تحلیلی پیچیده و تحلیل روند تاریخی استفاده میکنند. این سناریوها از توانایی پردازش مجموعههای داده کامل با منطق تحول پیچیده در حالی که استفاده از منابع را در ساعات غیراوج بهینه میکنند، بهره میبرند.
- آموزش مدل یادگیری ماشین: آموزش مدلهای یادگیری ماشین پیچیده نیاز به دسترسی به مجموعههای داده تاریخی کامل و الگوریتمهای محاسباتی intensive دارد که از بهینهسازی پردازش دستهای بهره میبرند. سازمانها میتوانند از پردازش دستهای برای آموزش مدلها روی مجموعههای داده بزرگ در حالی که هزینههای محاسباتی را از طریق پردازش زمانبندیشده در دورههای کمهزینه مدیریت میکنند، استفاده کنند.
- پشتیبانگیری سیستم و نگهداری: عملیات پشتیبانگیری روتین، رویههای نگهداری پایگاه داده و وظایف بهینهسازی سیستم به طور مؤثر از طریق زمانبندیهای پردازش دستهای که با الزامات عملیاتی هماهنگ هستند و تأثیر بر عملیات تجاری را به حداقل میرسانند، عمل میکنند.
چه زمانی باید پردازش داده جریانی را انتخاب کنید؟
پردازش جریانی ارزش بهینه را برای برنامههایی که نیاز به پاسخ فوری به شرایط در حال تغییر، قابلیتهای تصمیمگیری واقعیزمان و سناریوهایی که تأخیرهای پردازش میتواند منجر به فرصتهای از دست رفته یا تأثیر تجاری منفی شود، ارائه میدهد.
- تشخیص تقلب و نظارت امنیتی: مؤسسات مالی و پردازشگرهای پرداخت از پردازش جریانی برای تحلیل تراکنش واقعیزمان که میتواند فعالیتهای تقلبآمیز را در میلیثانیههای وقوع شناسایی و جلوگیری کند، پیادهسازی میکنند. سیستمهای نظارت امنیتی به طور مشابه از تحلیل مداوم ثبت وقایع سیستم و فعالیتهای کاربر برای تشخیص تهدیدات بالقوه فوری بهره میبرند.
- شخصیسازی واقعیزمان و توصیهها: پلتفرمهای تجارت الکترونیک، خدمات جریانی محتوا و برنامههای بازاریابی دیجیتال از پردازش جریانی برای تحلیل الگوهای رفتار کاربر و ارائه تجربیات شخصیسازیشده فوری استفاده میکنند. این برنامهها نیاز به پردازش مداوم تعاملات کاربر برای حفظ engagement و بهینهسازی نرخهای تبدیل دارند.
- نظارت عملیاتی و هشداردهی: سیستمهای تولید، نظارت زیرساخت و برنامههای اینترنت اشیاء به پردازش جریانی برای تشخیص فوری ناهنجاریها، شکستهای تجهیزات یا کاهش عملکرد که نیاز به پاسخ سریع برای جلوگیری از downtime پرهزینه یا خطرات ایمنی دارد، وابسته هستند.
- تجارت مالی و تحلیل بازار: سیستمهای تجارت با فرکانس بالا و برنامههای تحلیل بازار واقعیزمان نیاز به قابلیتهای پردازش جریانی دارند که میتوانند داده بازار را تحلیل کنند و تصمیمات تجارت را در میکروثانیهها اجرا کنند تا از فرصتهای بازار بهرهبرداری کنند و مواجهه با ریسک را مدیریت کنند.
بهترین ابزارهای پردازش جریانی موجود چیست؟
Apache Kafka
Apache Kafka به عنوان یک پلتفرم جریانی رویداد توزیعشده عمل میکند که مدل تولیدکننده/مصرفکننده را با موضوعات و پارتیشنها برای بهبود تحمل خطا در شبکههای کارگزار توزیعشده پیادهسازی میکند. Kafka پایهای برای بسیاری از معماریهای جریانی سازمانی از طریق توانایی خود در مدیریت میلیونها پیام در ثانیه در حالی که دوام و تضمینهای سفارش را حفظ میکند، ارائه میدهد. معماری توزیعشده پلتفرم مقیاس افقی را امکانپذیر میسازد و مکانیسمهای تکثیر داخلی ارائه میدهد که دسترسی داده را حتی در شکستهای گره تضمین میکند. اکوسیستم Kafka شامل Kafka Streams برای برنامههای پردازش جریانی و Kafka Connect برای ادغام با سیستمهای خارجی است و یک پلتفرم جریانی جامع ایجاد میکند.
Google Cloud Dataflow
Google Cloud Dataflow یک سرویس جریانی کاملاً مدیریتشده ارائه میدهد که بر اساس Apache Beam ساخته شده و از کیتهای توسعه نرمافزاری جاوا، پایتون و گو پشتیبانی میکند در حالی که قابل حمل در چندین موتور اجرا باقی میماند. سرویس به طور خودکار مقیاس منابع، بهینهسازی و مدیریت عملیاتی را مدیریت میکند در حالی که مدلهای برنامهنویسی یکپارچه برای پردازش دستهای و جریانی ارائه میدهد. معماری بدون سرور Dataflow سربار مدیریت زیرساخت را حذف میکند در حالی که امنیت درجه سازمانی، نظارت و قابلیتهای ادغام با سایر خدمات Google Cloud ارائه میدهد. پلتفرم عملکرد را به طور خودکار بهینه میکند و قیمتگذاری شفاف بر اساس مصرف واقعی منابع ارائه میدهد.
Amazon Kinesis
ابزارهای مؤثرترین پردازش دستهای چیست؟
Airbyte
Airbyte قابلیتهای حرکت داده جامع با بیش از ۶۰۰ اتصالدهنده از پیشساخته که سیستمهای منبع و مقصد متنوع را پشتیبانی میکنند، ارائه میدهد. پلتفرم توسعه اتصالدهنده سفارشی را از طریق کیت توسعه اتصالدهنده خود، حالتهای همگامسازی متعدد از جمله بهروزرسانیهای افزایشی و گزینههای زمانبندی انعطافپذیر از جمله زمانبندیشده، مبتنی بر کرون و اجرای دستی پشتیبانی میکند. معماری پلتفرم گزینههای استقرار میزبانیشده ابری و خودمدیریتی را پشتیبانی میکند در حالی که امنیت، حاکمیت و قابلیتهای نظارت درجه سازمانی ارائه میدهد. رویکرد استخراج-بارگذاری-تحول Airbyte تحول را در سیستمهای مقصد امکانپذیر میسازد و عملکرد را بهینه میکند و سربار پردازش را در مقایسه با روششناسیهای استخراج-تحول-بارگذاری سنتی کاهش میدهد.
AWS Batch
AWS Batch به طور پویا منابع محاسباتی بهینه را برای اجرای بارهای کاری دستهای در هر مقیاسی تأمین میکند و به طور seamless با خدمات AWS از جمله Lambda، CloudWatch و EC2 ادغام میشود. سرویس به طور خودکار زمانبندی شغل، تخصیص منابع و مدیریت صف را مدیریت میکند در حالی که بهینهسازی هزینه از طریق استفاده از instances spot ارائه میدهد. پلتفرم برنامههای کانتینریشده را پشتیبانی میکند و قابلیتهای نظارت و ثبت وقایع جامع برای visibility عملیاتی ارائه میدهد. AWS Batch سربار مدیریت زیرساخت را حذف میکند در حالی که امنیت و قابلیتهای انطباق درجه سازمانی از طریق ادغام با سیستمهای مدیریت هویت و دسترسی AWS ارائه میدهد.
Azure Batch
Azure Batch ایجاد و مدیریت استخرهای محاسباتی برای شغلهای محاسباتی با عملکرد بالا در مقیاس بزرگ را بدون نیاز به نگهداری خوشه یا مدیریت زیرساخت اتوماتیک میکند. سرویس مقیاس خودکار، تعادل بار و تحمل خطا ارائه میدهد در حالی که با Azure Active Directory برای امنیت و حاکمیت ادغام میشود. پلتفرم انواع بار کاری متنوع، از جمله رندرینگ، شبیهسازی و برنامههای پردازش داده را پشتیبانی میکند در حالی که بهینهسازی هزینه از طریق ماشینهای مجازی اولویت پایین و سیاستهای مقیاس خودکار ارائه میدهد. Azure Batch شامل قابلیتهای نظارت و عیبیابی جامع برای مدیریت عملیاتی و بهینهسازی عملکرد است.
چگونه میتوانید پردازش دستهای و جریانی را به طور مؤثر ترکیب کنید؟
رویکردهای پردازش ترکیبی به سازمانها اجازه میدهد نقاط قوت هر دو پردازش دستهای و جریانی را بهرهبرداری کنند در حالی که محدودیتهای مربوطه را کاهش دهند. این معماریها نیاز به طراحی دقیق برای تضمین ثبات بین مسیرهای پردازش در حالی که برای پاسخگویی واقعیزمان و قابلیتهای تحلیلی جامع بهینهسازی میکنند، دارند.
- پیادهسازی معماری لامبدا: سازمانها میتوانند معماریهای لامبدا را پیادهسازی کنند که مسیرهای پردازش دستهای و جریانی جداگانه را در لایه خدمت همگرا میکنند. لایه دستهای مجموعههای داده کامل را برای حداکثر دقت پردازش میکند، در حالی که لایه جریانی بینشهای واقعیزمان ارائه میدهد و لایه خدمت نتایج را از هر دو رویکرد پردازش reconcile میکند.
- سادهسازی معماری کاپا: معماری کاپا پردازش ترکیبی را با تمرکز انحصاری روی پردازش جریانی در حالی که توانایی پردازش مجدد داده تاریخی زمانی که لازم است را حفظ میکند، ساده میسازد. این رویکرد همه داده را به عنوان داده جریانی درمان میکند و از قابلیتهای replay برای مدیریت سناریوهایی که traditionally نیاز به پردازش دستهای دارند، استفاده میکند.
- جداسازی موارد استفاده: سازمانها میتوانند رویکردهای پردازش متفاوت را برای انواع داده و الزامات تجاری مختلف پیادهسازی کنند. برنامههای واقعیزمان حیاتی از پردازش جریانی برای پاسخ فوری استفاده میکنند، در حالی که بارهای کاری تحلیلی جامع از پردازش دستهای برای کارایی و دقت بهره میبرند.
- استراتژیهای مهاجرت مرحلهای: مهاجرت تدریجی از دستهای به جریانی به سازمانها اجازه میدهد به طور افزایشی انتقال دهند در حالی که continuity عملیاتی را حفظ میکنند. این رویکرد به سازمانها اجازه میدهد تخصص جریانی و اعتماد بسازند در حالی که اختلال در فرآیندهای تجاری موجود را به حداقل میرسانند.
نتیجهگیری
پردازش دستهای در سناریوهایی که نیاز به تحلیل جامع، کارایی حجم بالا و بهینهسازی هزینه دارند، برتری دارد، در حالی که پردازش جریانی ارزش را برای برنامههایی که تقاضای بینشهای فوری و قابلیتهای پاسخ سریع دارند، ارائه میدهد. معماریهای داده مدرن به طور فزایندهای فراتر از انتخابهای باینری به سمت چارچوبهای پردازش یکپارچه حرکت میکنند که مزایای هر دو رویکرد را ترکیب میکنند در حالی که پیچیدگی عملیاتی را به حداقل میرسانند.
کلید موفقیت در ارزیابی دقیق الزامات تجاری، درک trade-offها بین رویکردهای پردازش و انتخاب پلتفرمهایی که انعطافپذیری برای سازگاری با تکامل نیازهای سازمانی ارائه میدهند، نهفته است.
پرسشهای متداول
تفاوت اصلی بین پردازش دستهای در مقابل پردازش جریانی چیست؟
تفاوت اساسی در زمانبندی و مدیریت داده نهفته است: پردازش دستهای مجموعههای داده بزرگ را در فواصل زمانبندیشده جمعآوری و پردازش میکند، در حالی که پردازش جریانی داده را به طور مداوم به محض ورود در واقعیزمان مدیریت میکند. پردازش دستهای برای توان عملیاتی و دقت با تأخیر بالاتر بهینهسازی میشود، در حالی که پردازش جریانی تأخیر پایین و بینشهای فوری را اولویتبندی میکند.
چه زمانی باید پردازش دستهای را به جای پردازش جریانی انتخاب کنم؟
پردازش دستهای را برای سناریوهایی که نیاز به پردازش داده حجم بالا، محاسبات تحلیلی پیچیده، گزارشگیری نظارتی و موقعیتهایی که تأخیرهای پردازش قابل قبول است، انتخاب کنید. پردازش دستهای بیشترین اثربخشی را برای انبار داده، آموزش مدل یادگیری ماشین و برنامههای هوش تجاری جامع که مجموعههای داده کامل تحلیل دقیقتر را امکانپذیر میسازند، ثابت میکند.
آیا میتوانم هر دو پردازش دستهای و جریانی را با هم استفاده کنم؟
بله، معماریهای ترکیبی مانند لامبدا میتوانند هر دو رویکرد پردازش دستهای و جریانی را به طور مؤثر ترکیب کنند. سازمانها اغلب از پردازش جریانی برای برنامههای واقعیزمان مانند تشخیص تقلب استفاده میکنند در حالی که همزمان از پردازش دستهای برای تحلیل و گزارشگیری جامع بهره میبرند. پلتفرمهای مدرن به طور فزایندهای مدلهای پردازش یکپارچه را پشتیبانی میکنند که هر دو رویکرد را در سیستمهای تک امکانپذیر میسازند.
ملاحظات هزینه انتخاب پردازش جریانی به جای پردازش دستهای چیست؟
پردازش جریانی معمولاً هزینههای عملیاتی بالاتر به دلیل الزامات منابع مداوم، تخصص تخصصی و نیازهای زیرساخت پیچیده نیاز دارد. با این حال، ارزش تجاری بینشهای واقعیزمان ممکن است این هزینههای اضافی را برای برنامههایی که پاسخ فوری مزایای رقابتی ارائه میدهد یا از ضررهای قابل توجه جلوگیری میکند، توجیه کند.