گوشیهای هوشمند، تبلتها، کامپیوترها، ساعتهای هوشمند و بیشتر هر روز حجم عظیمی از دادهها تولید میکنند. تحلیل این دادهها میتواند برای کسبوکار شما حیاتی باشد زیرا بینشهایی در مورد ترجیحات مشتریانتان فراهم میکند. شما میتوانید از این بینشها بهره ببرید و فرآیند توسعه محصول یا کمپینهای بازاریابیتان را بهبود بخشید.
چالش اصلی در تجمیع دادهها از منابع متعدد و تبدیل آنها به فرمت قابل استفاده برای استخراج بینشها و پیشبرد رشد تجاری نهفته است. داشتن فرآیند استخراج-تبدیل-بارگذاری (ETL) تثبیتشده در سازمانتان زمان و منابع زیادی صرفهجویی میکند. این مقاله مروری بر معماری استخراج-تبدیل-بارگذاری و چگونگی بهبود مدیریت داده و تصمیمگیری ارائه میدهد.
معماری ETL چیست؟
استخراج-تبدیل-بارگذاری مخفف ETL است، مفهومی کلیدی در یکپارچهسازی داده مدرن و تحلیل. این رویکرد ساختاریافتهای برای جابجایی داده از منابع متعدد، تبدیل آن به فرمت مطلوب و بارگذاری به سیستم مقصد برای تحلیل فراهم میکند.
اجزای کلیدی معماری ETL
فرآیند ETL شامل عبور داده از ماژولهای مختلف است. هر ماژول در تضمین پردازش دقیق داده از منبع تا مقصد حیاتی است.
۱. منابع داده
گام اولیه در فرآیند ETL، شناسایی منابع داده است که داده از آنها استخراج میشود، مانند پایگاههای داده، رابطهای برنامهنویسی کاربردی یا دادههای حسگر در دستگاههای اینترنت اشیاء. دادهها در فرمتهای مختلفی مانند CSV، JSON یا XML قرار دارند.
۲. منطقه لودینگ (Loading Area)
یک فضای ذخیرهسازی موقت است که دادههای استخراجشده از منابع را قبل از انجام هر تبدیلی ذخیره میکند. ممکن است چندین دسته داده را قبل از جابجایی از طریق پایپلاین ETL ذخیره کند.
۳. منطقه آمادهسازی
آمادهسازی داده یک فرآیند خودکار برای تبدیل کارآمد داده است. این فرآیند حذف مقادیر NA یا NULL را تسهیل میکند و ذخیرهسازی و منابع محاسباتی را صرفهجویی مینماید. همچنین میتوانید قوانین پاکسازی و فیلتر تنظیم کنید تا دادههای نامربوط یا ناخواسته حذف شوند. دادههای پاکشده غنیسازی میشوند و بررسیهای اعتبارسنجی نهایی را طی میکنند تا هرگونه ناسازگاری حذف گردد.
۴. مقصد
دادههای تبدیلشده در مقصد یا سیستم ذخیرهسازی متمرکز ذخیره میشود، اغلب یک دریاچه داده یا انبار داده. این دادهها سپس با استفاده از ابزارهای تجسم یا ابزارهای هوش تجاری برای تحلیل استفاده میشوند تا بینشهای ارزشمند به دست آید و تصمیمگیریهای آگاهانه انجام شود.
فرآیند ETL در عمل چگونه کار میکند؟
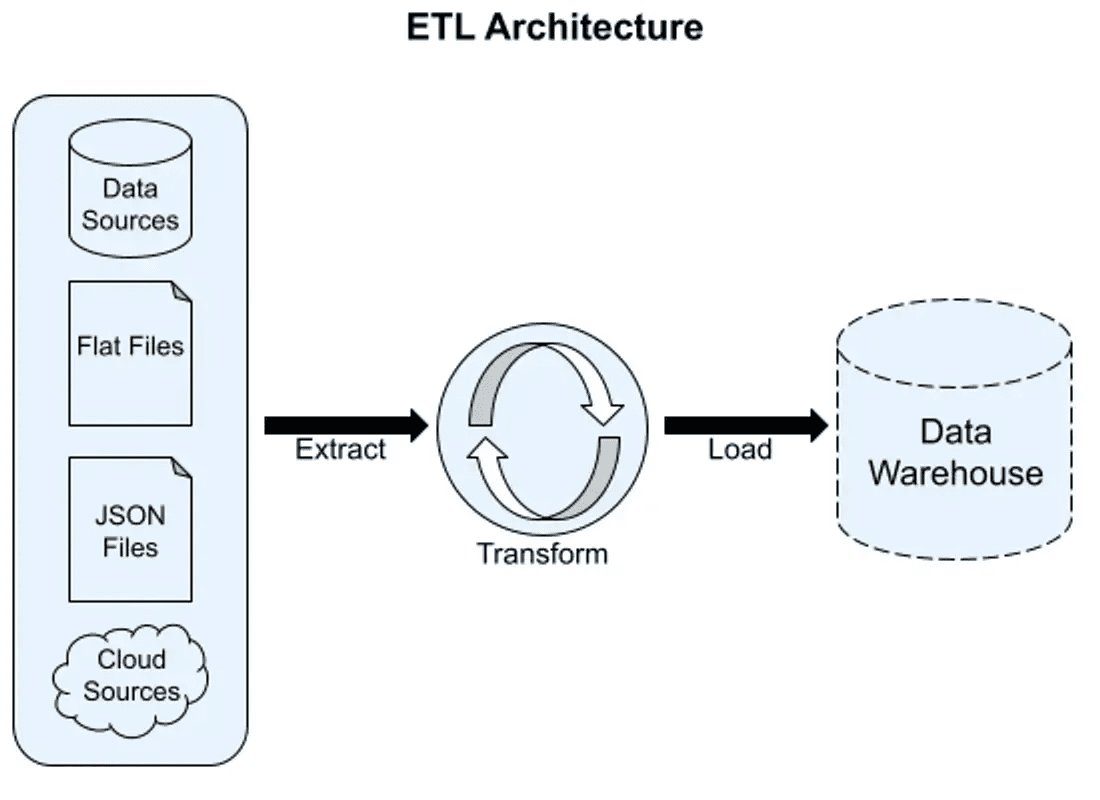
یک فرآیند ETL به خوبی تعریفشده، جریان داده یکپارچه را بدون اختلال در جریانهای کاری موجود امکانپذیر میسازد. در اینجا توصیف دقیقی از مراحل ETL آورده شده است:
۱. تبدیل
دومین فرآیند شامل تبدیل داده به فرمت سازگار و دقیق بر اساس سازگاری سیستم مقصد و نیازهای تحلیلی است. تکنیکهای تبدیل داده شامل موارد زیر است:
- پاکسازی داده – شناسایی و مدیریت رکوردهای نادرست با حذف تکراریها، مدیریت مقادیر گمشده و تشخیص نقاط پرت.
- غنیسازی داده – بهبود دادههای موجود با افزودن اطلاعات اضافی (مانند دادههای توصیفی یا دادههای خارجی).
- فرمتبندی داده – تبدیل داده به فرمت خاص مناسب برای تحلیل، ذخیرهسازی و گزارشگیری کارآمد.
- فیلتر داده – انتخاب زیرمجموعه داده بر اساس معیارهای خاص برای تمرکز بر اطلاعات مرتبط.
- اعتبارسنجی داده – تضمین اینکه دادههای تبدیلشده استانداردهای کیفی خاصی را برآورده کنند و آماده تحلیل باشند.
۲. بارگذاری
مرحله نهایی فرآیند ETL، بارگذاری است. این شامل بارگذاری دادههای تبدیلشده به سیستم مقصد مانند انبار داده، دریاچه داده یا ابزار هوش تجاری است.
روشهای بارگذاری رایج:
- بارگذاری کامل – انتقال تمام دادهها به سیستم مقصد (اغلب برای بارگذاریهای اولیه استفاده میشود).
- بارگذاری افزایشی – بارگذاری فقط دادههای جدید یا بهروزرسانیشده برای همگامسازی با بهروزرسانیهای مداوم.
چه عوامل کلیدی باید هنگام طراحی معماری ETL در نظر گرفته شوند؟
درک الزامات تجاریتان اهداف پروژه و محدودیتها را به وضوح شناسایی کنید تا معماری ETL طراحی کنید که منابع داده، مقصدها و الزامات تبدیل را تعریف کند، در حالی که استانداردهای کیفیت داده را برقرار مینماید.
شناسایی منشأ و مقصد داده دانستن اینکه داده از کجا منشأ میگیرد و کجا قرار میگیرد تضمین میکند داده بدون ناسازگاری جمعآوری، پردازش و بارگذاری شود.
حجم داده با رشد نمایی حجم دادهها، پردازش افزایشی یا زمان واقعی را برای کسب بینشهای فوری، کاهش تأخیر و بهینهسازی هزینهها در نظر بگیرید.
تعیین ETL دستهای در مقابل جریانی ETL دستهای – پردازش داده در دستههای زمانبندیشده؛ ایدهآل برای حجمهای بزرگ که حساس به زمان نیستند. ETL جریانی – پردازش داده به محض ورود؛ ایدهآل برای موارد استفاده زمان واقعی مانند تحلیل بازار سهام.
معماریهای بدون ETL چگونه یکپارچهسازی داده را تحول میدهند؟
معماریهای بدون ETL تغییر پارادایمی در یکپارچهسازی داده ایجاد میکنند و پیچیدگی خط لوله سنتی را با امکان اتصال مستقیم بین سیستمهای عملیاتی و تحلیلی حذف میکنند. این رویکرد از یکپارچهسازیهای بومی ابری و همگامسازی زمان واقعی برای جابجایی فوری داده بدون مراحل تبدیل میانی بهره میبرد.
درک پیادهسازی بدون ETL بدون ETL با جاسازی منطق تبدیل در پلتفرمهای مقصد به جای نیاز به زیرساخت خط لوله جداگانه کار میکند. انبارهای داده ابری مانند آمازون ردشفت و اسنوفلیک اکنون پرسوجوی مستقیم پایگاههای داده عملیاتی را از طریق یکپارچهسازیهای بومی پشتیبانی میکنند و از ضبط تغییرات داده برای همگامسازی مداوم داده استفاده مینمایند. این امر مراحل استخراج و بارگذاری سنتی را کاملاً حذف میکند، تأخیر را از ساعتها به میلیثانیهها کاهش میدهد و هزینههای زیرساختی را به طور قابل توجهی کم میکند.
مزایای استراتژیک و ملاحظات سازمانهایی که بدون ETL را اتخاذ میکنند، کاهش هزینههای قابل توجه از طریق حداقل زیرساخت و بار مهندسی گزارش میدهند. شرکتهای خدمات مالی از این رویکرد برای تشخیص تقلب زمان واقعی استفاده میکنند، جایی که زمانهای پاسخ میلیثانیهای مستقیماً بر نتایج تجاری تأثیر میگذارد. با این حال، بدون ETL چالشهای جدیدی در عیبیابی ناسازگاریهای داده بدون مراحل خط لوله مجزا ایجاد میکند که نیازمند ردیابی متاداده پیشرفته و قابلیتهای نظارت است.
یکپارچهسازی با پلتفرمهای داده مدرن قابلیت بدون ETL به پلتفرمهای بومی ابری وابسته است که بارهای کاری تراکنشی و تحلیلی را همزمان پشتیبانی میکنند. فناوریهایی مانند آپاچی آیسبرگ فرمتهای جدول را امکانپذیر میسازند که دادههای دستهای و جریانی را یکپارچه میکنند و پیادهسازیهای بدون ETL را قادر میسازند انواع داده متنوع را به طور بومی مدیریت کنند. این همگرایی زمان تا بینش را از روزها به دقیقهها تبدیل میکند، هرچند نیازمند بازطراحی مدلهای حاکمیت سنتی برای تطبیق با جریانهای مستقیم عملیاتی به تحلیلی است.
بهترین شیوهها برای طراحی معماری ETL چیست؟
میکروسرویسهای مستقل معماری ETL را به مراحل مدولار مستقل (استخراج، تبدیل، بارگذاری) تجزیه کنید تا پردازش موازی و جداسازی خطاها امکانپذیر شود.
همگامسازیهای افزایشی داده پس از استخراج اولیه بزرگ، تضمین کنید استخراجهای بعدی فقط دادههای جدید یا بهروزرسانیشده را ضبط کنند تا منابع محاسباتی صرفهجویی شود.
انتخاب ابزار ETL مناسب در نظر بگیرید:
اتصال و یکپارچهسازی – اتصالدهندههای از پیش ساخته و یکپارچهسازی یکپارچه. سهولت استفاده – کاربرپسند برای تیمهای فنی و غیرفنی. امنیت و تطبیق – رمزنگاری داده، کنترل دسترسی و حسابرسی. هزینه و مقیاسپذیری – توانایی مدیریت حجمهای داده در حال رشد در بودجه. پشتیبانی مشتری – کمک سریع و آگاهانه و منابع آموزشی.
امنیت داده به مقررات مرتبط (مانند مقررات عمومی حفاظت از دادهها، قانون قابل حمل بودن بیمه سلامت) پایبند باشید با تنظیم سیاستهایی که داده را در سراسر چرخه عمرش محافظت میکنند.
ثبت لاگ و نظارت مشاهدهپذیری داده را با ثبت لاگ هر زیرفرآیند ETL برای حسابرسی فعالیتها و ردیابی ناهنجاریها تمرین کنید.
اتوماسیون مبتنی بر هوش مصنوعی چگونه معماری ETL را بهبود میبخشد؟
هوش مصنوعی فرآیندهای ETL را با خودکارسازی وظایف دستی سنتی و بهینهسازی عملکرد خط لوله از طریق یادگیری ماشینی متحول میکند. سیستمهای ETL مبتنی بر هوش مصنوعی مدرن میتوانند کد تبدیل تولید کنند، ناهنجاریهای داده را پیشبینی و اصلاح نمایند و تخصیص منابع را به طور پویا بدون مداخله انسانی بهینهسازی کنند.
هوش مصنوعی generative برای توسعه خط لوله پلتفرمهای مبتنی بر هوش مصنوعی اکنون ایجاد خط لوله با زبان طبیعی را امکانپذیر میسازند، جایی که مهندسان تبدیلها را به انگلیسی ساده توصیف میکنند و سیستم کد قابل اجرا تولید میکند. این ابزارها متاداده خط لوله تاریخی را تحلیل میکنند تا منطق تبدیل بهینه پیشنهاد دهند، نیاز به کدگذاری دستی را کاهش میدهند در حالی که خروجیهای داده با کیفیت بالا را حفظ مینمایند. مدلهای یادگیری ماشینی همچنین میتوانند نگاشت فیلدها و قوانین کیفیت داده را بر اساس الگوهای یکپارچهسازی مشابه به طور خودکار پیشنهاد دهند و چرخههای توسعه را به طور قابل توجهی تسریع کنند.
مدیریت کیفیت داده خودکار ابزارهای ETL مبتنی بر هوش مصنوعی الگوریتمهای یادگیری ماشینی را برای اعتبارسنجی داده پویا که با الگوهای داده در حال تغییر تطبیق مییابد، شامل میشوند. این سیستمها بر روی مجموعههای داده تاریخی آموزش میبینند تا ناهنجاریها را در حین دریافت پیشبینی و اصلاح کنند، مانند جایگزینی مقادیر گمشده یا پرچمگذاری خطاهای تبدیل ارز در تراکنشهای مالی. به جای استفاده از قوانین اعتبارسنجی ایستا، مدلهای یادگیری ماشینی خطوط پایه سلامت داده را برقرار میکنند و هشدارها را به طور خودکار زمانی که خروجیهای خط لوله از الگوهای مورد انتظار منحرف میشوند، فعال مینمایند و نظارت کیفیت را از واکنشی به پیشگیرانه تغییر میدهند.
بهینهسازی خط لوله شناختی سیستمهای هوش مصنوعی پیشرفته اکنون عملکرد خط لوله کلی را از طریق مقیاسپذیری پیشبینیکننده و قابلیتهای خودترمیم مدیریت میکنند. عاملهای یادگیری تقویتی توان عملیاتی، تأخیر و نرخهای خطا را نظارت میکنند تا منابع محاسباتی را در حین افزایش ترافیک به طور پویا تنظیم کنند در حالی که توافقنامههای سطح خدمات را حفظ مینمایند. این سیستمهای خودمختار میتوانند قطعی خط لوله را به طور قابل توجهی کاهش دهند و استفاده از منابع ابری را برای صرفهجویی هزینه قابل توجه در مقیاس سازمانی بهینهسازی کنند و پارچههای داده خودمدیریتی ایجاد نمایند که مداخله انسانی فراتر از تعریف سیاست سطح بالا را حداقل کنند.
نتیجهگیری
معماری ETL نقش حیاتی در تبدیل داده خام از منابع متنوع به فرمت تمیز و قابل تحلیل ایفا میکند. با درک اجزای آن، عوامل طراحی کلیدی و بهترین شیوهها—و با بهرهبرداری از ابزارهای قوی—میتوانید پایپلاین ETL قابل اعتماد برقرار کنید که بینشهای ارزشمند را برای تصمیمگیریهای دادهمحور آزاد میسازد.
سوالات متداول
معماری ETL چیست؟
معماری ETL رویکرد ساختاریافتهای برای جابجایی داده از منابع متعدد، تبدیل آن به فرمت مطلوب و بارگذاری به سیستم مقصد برای تحلیل فراهم میکند.
چگونه کیفیت داده را در فرآیندهای ETL تضمین کنید؟
تضمین کیفیت داده شامل پاکسازی داده، اعتبارسنجی، حسابرسی و ثبت لاگ برای تحلیل داده منبع به منظور ناسازگاریها و بررسی آنها در برابر قوانین از پیش تعریفشده است.