
پایتون یکی از محبوبترین زبانهای برنامهنویسی مدرن برای workflowهای مهندسی داده است. نحوه نوشتاری شهودی، اکوسیستم گسترده کتابخانهها و انطباقپذیری قابل توجه آن را انتخاب ترجیحی برای مهندسان داده در سراسر جهان میکند، به ویژه هنگام ساخت پایپلاین ادغام داده قوی. یکی از کاربردهای قدرتمند، ETL در پایتون است که workflowهای پیچیده دادههای سختاستفاده یا بدون ساختار را استخراج و به فرمتهای پاک و ساختارمند آماده تحلیل تبدیل میکند.
استفاده از پایتون برای ETL میتواند زمان توسعه را به طور چشمگیری کاهش دهد با امکان اجرای موازی مراحل استخراج، تبدیل و بارگذاری. کتابخانههای مدرن پایتون دسترسی به منابع داده متنوع و APIها را سادهسازی میکنند و کل فرآیند را کارآمدتر میسازند. علاوه بر این، این کتابخانهها با توابع داخلی همراهند که استخراج، تبدیل و تحلیل داده را بدون نیاز به کد سفارشی گسترده یا راهاندازی زیرساخت پیچیده تسهیل میکنند.
ETL چیست؟
برای درک ETL پایتون، ابتدا اصول ETL را کاوش کنیم. ETL یا استخراج، تبدیل، بارگذاری روش جامع ادغام داده بین سیستمهای متعدد است. ابتدا برای راهحلهای سرور محلی توسعه یافته، ETL به طور قابل توجهی تکامل یافته اما اصول اصلی خود را حفظ کرده است. منابع داده مختلف را با مقاصد مرکزی مانند انبارهای داده همگامسازی میکند و قابلیتهای هوش تجاری را در سراسر سازمانها افزایش میدهد.
پایپلاین ETL شامل سه مرحله اساسی است:
استخراج: سیستماتیک داده را از منابع متعدد مانند APIها، فایلهای تخت، پایگاههای داده، پلتفرمهای جریانی یا خدمات ابری کشیدن. تبدیل: داده خام را از طریق پاکسازی جامع، تجمیع، اعتبارسنجی و غنیسازی به داده ساختارمند تبدیل کنید و یکپارچگی داده را در طول فرآیند تضمین کنید. بارگذاری: داده تبدیلشده را به سیستمهای هدف مانند انبارهای داده، دریاچههای داده یا پلتفرمهای تحلیلی به طور کارآمد فشار دهید.
ETL پایتون کل این فرآیند را با استفاده از اکوسیستم غنی کتابخانهها و چارچوبهای پایتون انجام میدهد. ادغام با خدمات ابری مدرن مقیاسپذیری را افزایش میدهد و مدیریت کارآمد datasetهای عظیم را با بهرهگیری از فناوریهای محاسبات توزیعشده و قابلیتهای پردازش بلادرنگ امکانپذیر میسازد.
مزایای کلیدی استفاده از پایتون برای ETL چیست؟
اکوسیستم گسترده کتابخانهها و چارچوبها
اکوسیستم گسترده پایتون شامل کتابخانههای قدرتمند مانند pandas برای دستکاری داده، NumPy برای محاسبات عددی، SQLAlchemy برای عملیات پایگاه داده، Beautiful Soup برای web scraping و ابزارهای نوظهور مانند Polars برای پردازش داده با عملکرد بالا است. این کتابخانهها تحولات پیچیده را سادهسازی میکنند و دسترسی seamless به داده در پلتفرمهای متنوع فراهم میکنند.
قابلیتهای ادغام
پایتون به پایگاههای داده، فرمتهای فایل، APIها و ابزارهای big-data مانند Apache Spark از طریق PySpark، سیستمهای پیامرسانی مانند Apache Kafka و RabbitMQ و پلتفرمهای ابری شامل AWS، Google Cloud و Azure به راحتی متصل میشود. این انعطافپذیری سازمانها را قادر میسازد پایپلاین داده یکپارچه در محیطهای hybrid و multi-cloud بسازند.
انعطافپذیری پایپلاین ETL
با پشتیبانی از پارادایمهای برنامهنویسی شیءگرا، تابعی و روندگرا، پایتون امکان طراحی پایپلاین سفارشی متناسب با الزامات تجاری خاص را فراهم میکند. چه بارگذاری داده به Amazon S3 با کتابخانه boto3، پردازش داده جریانی با PyFlink یا پیادهسازی تحولات بلادرنگ، پایتون با نیازهای معماری شما تطبیق مییابد.
نوآوری جامعهمحور
جامعه منبعباز فعال پایتون به طور مداوم ابزارها و چارچوبهای جدید توسعه میدهد که چالشهای نوظهور مهندسی داده را حل میکنند. این اکوسیستم مشارکتی دسترسی به راهحلهای cutting-edge برای الزامات مدرن مانند ادغام هوش مصنوعی، پردازش بلادرنگ و معماریهای بومی ابر را تضمین میکند.
چگونه پایپلاین ETL با پایتون بسازیم؟
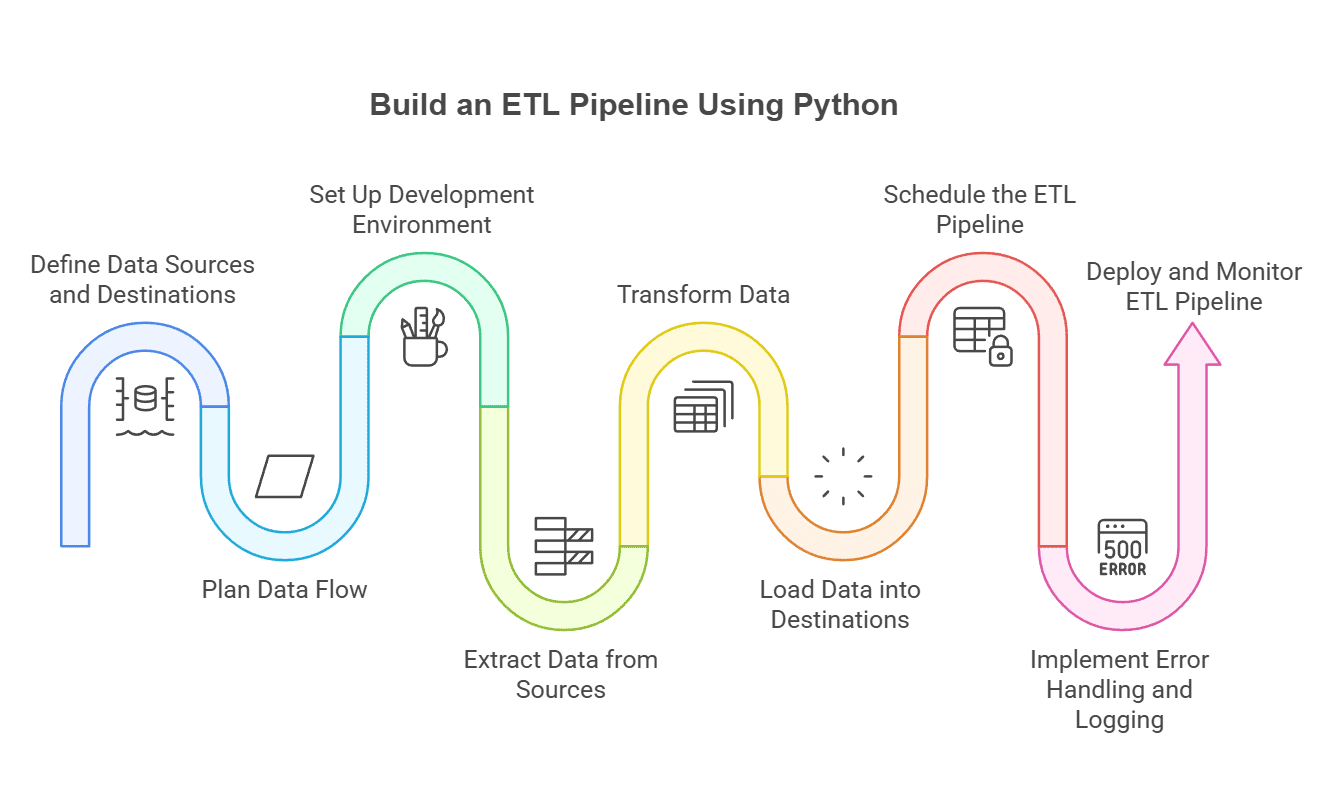
۱. منابع و مقاصد داده را تعریف کنید
تمام منابع داده شامل پایگاههای داده SQL، فایلهای تخت، APIها، پلتفرمهای جریانی و سیستمهای ذخیرهسازی ابری را شناسایی کنید. سیستمهای هدف مناسب مانند انبارهای داده، پایگاههای داده، دریاچههای داده یا پلتفرمهای تحلیلی را بر اساس الزامات استفاده downstream انتخاب کنید.
۲. جریان داده را برنامهریزی کنید
جریان داده کامل و دنباله تحول را نقشهبرداری کنید، شامل ردیابی داده، بررسیهای کیفیت، مدیریت خطا و مکانیسمهای بازیابی. هم پردازش batch و بلادرنگ را بر اساس نیازهای تجاری در نظر بگیرید.
۳. محیط توسعه را راهاندازی کنید
پایتون و کتابخانههای ETL ضروری مانند pandas برای دستکاری داده، NumPy برای عملیات عددی، SQLAlchemy برای اتصال پایگاه داده و ابزارهای مدرن مانند Polars برای پردازش با عملکرد بالا را نصب کنید.
۴. داده را استخراج کنید
به منابع مختلف متصل شوید و داده خام را با استفاده از کانکتورها و پروتکلهای مناسب بکشید. احراز هویت مناسب، مدیریت خطا و مکانیسمهای retry را برای استخراج قابل اعتماد پیادهسازی کنید.
۵. داده را تبدیل کنید
داده را با استفاده از کتابخانههایی مانند pandas یا Polars پاکسازی، فیلتر، پیوند، تجمیع و اعتبارسنجی کنید. قوانین تجاری، بررسیهای کیفیت داده و فرآیندهای غنیسازی را اعمال کنید تا اطمینان حاصل شود داده الزامات downstream را برآورده میکند.
۶. داده را بارگذاری کنید
داده تبدیلشده را به سیستمهای مقصد به طور کارآمد بنویسید. از کتابخانههایی مانند dlt برای workflowهای ELT یا SQLAlchemy برای عملیات پایگاه داده برای سادهسازی فرآیند بارگذاری بهره ببرید.
۷. پایپلاین ETL را زمانبندی کنید
از ابزارهای ارکستراسیون مدرن مانند Apache Airflow، Prefect یا Dagster برای اتوماسیون اجرای پایپلاین، مدیریت وابستگیها و مدیریت الزامات زمانبندی workflow پیچیده استفاده کنید.
۸. مدیریت خطا و ثبت لاگ را پیادهسازی کنید
از ماژول logging پایتون در کنار ابزارهای نظارت برای ضبط استثناها، حفظ ردپای جامع audit و امکان حل مسائل فعال بهره ببرید.
۹. نشر و نظارت کنید
پایپلاین را به محیطهای تولیدی منتقل کنید و نظارت مداوم برای معیارهای عملکرد، شاخصهای کیفیت داده و خطاهای سیستم پیادهسازی کنید. مکانیسمهای هشدار برای مسائل حیاتی برقرار کنید.
چگونه ETL پایه پایتون راهاندازی کنیم؟
در این مثال، داده را از فایل CSV به MongoDB منتقل میکنیم و مفاهیم اساسی ETL را نشان میدهیم.
پیشنیازها
- پایتون
- PowerShell ویندوز (یا ترمینال)
- نمونه MongoDB در حال اجرا
۱. نصب و وارد کردن بستههای مورد نیاز
pip install pandas pymongo۲. استخراج داده
import pandas as pd
data = pd.read_csv('your_csv_file.csv')۳. تبدیل داده
# مرتبسازی بر اساس نام
sorted_data = data.sort_values(by=['name'])
# نگهداشتن ستونهای انتخابشده
filtered_data = data.filter(['name', 'is_student', 'target'])
# حذف موارد تکراری
clean_data = data.drop_duplicates()
# اعمال بررسیهای کیفیت داده
clean_data = clean_data.dropna() # حذف مقادیر null۴. بارگذاری داده به MongoDB
from pymongo import MongoClient
client = MongoClient('MONGODB_ATLAS_URL')
db = client['your_database']
collection = db['your_collection']
json_data = clean_data.to_dict(orient='records')
collection.insert_many(json_data)اسکریپت کامل
import pandas as pd
from pymongo import MongoClient
# استخراج
data = pd.read_csv('your_csv_file.csv')
# تبدیل
data = data.drop_duplicates()
data = data.dropna()
# بارگذاری
client = MongoClient('MONGODB_ATLAS_URL')
db = client['your_database']
collection = db['your_collection']
collection.insert_many(data.to_dict(orient='records'))کدام کتابخانههای پایتون برای پایپلاین ETL ضروری هستند؟
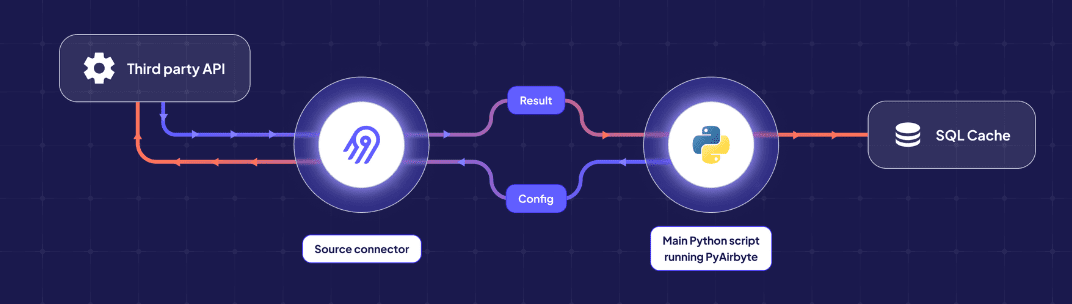
PyAirbyte
کانکتورهای pre-built برای استخراج و بارگذاری خودکار با کمک هوش مصنوعی.

Pandas
دستکاری و تحلیل جامع داده با قابلیتهای تحول غنی

SQLAlchemy
ORM و toolkit SQL قدرتمند برای عملیات پایگاه داده seamless

Requests
کلاینت HTTP/1.1 قوی برای استخراج و ادغام API قابل اعتماد


Beautiful Soup
آخرین تکنیکهای بهینهسازی عملکرد برای ETL پایتون چیست؟
workflowهای ETL پایتون مدرن نیازمند قابلیتهای پردازش با عملکرد بالا برای مدیریت datasetهای بزرگتر و الزامات بلادرنگ هستند. چندین تکنیک و کتابخانه breakthrough برای مقابله با این چالشهای عملکردی ظهور کردهاند:
کتابخانههای DataFrame با عملکرد بالا
Polars پیشرفت قابل توجه در پردازش داده پایتون است و بهبود عملکرد ۱۰-۱۰۰ برابری نسبت به عملیات pandas سنتی برای بسیاری از use caseها ارائه میدهد. ساختهشده بر پایه Rust، Polars lazy evaluation ارائه میدهد که عملیات گران را تا materialization به تعویق میاندازد و overhead حافظه را به طور قابل توجهی کاهش میدهد. مدل اجرای ستونی آن در پردازش سری زمانی، تجمیعهای پیچیده برتر است بدون نیاز به زیرساخت محاسبات توزیعشده.
DuckDB پردازش OLAP مبتنی بر SQL را مستقیماً در کاربردهای پایتون امکانپذیر میسازد و نیاز به انتقال داده به پایگاههای داده تحلیلی خارجی را حذف میکند. این رویکرد پرسوجوی in-process overhead انتقال داده را کاهش میدهد در حالی که عملکرد نزدیک به پایگاه داده برای workloadهای تحلیلی فراهم میکند.
کامپایل JIT و شتابدهی
Numba توابع پایتون را به کد ماشین بهینه با استفاده از کامپایل Just-In-Time تبدیل میکند و عملکرد نزدیک به C را برای محاسبات عددی بدون نیاز به بازنویسی کد دستیابی میکند.
استراتژیهای پردازش کارآمد حافظه
چارچوبهای ETL مدرن کارایی حافظه را از طریق پردازش streaming و الگوهای lazy evaluation تأکید میکنند. Dask پردازش out-of-core را برای datasetهای بزرگتر از RAM موجود امکانپذیر میسازد.
بهینهسازی پردازش موازی
ETL پایتون معاصر از multiprocessing و محاسبات توزیعشده از طریق PySpark برای پردازش موازی و Dask برای محاسبات توزیعشده بومی پایتون بهره میبرد.
چگونه پردازش ETL بلادرنگ در پایتون پیادهسازی کنیم؟
پردازش ETL بلادرنگ برای سازمانهایی که بینشهای فوری از منابع داده جریانی نیاز دارند ضروری شده است.
چارچوبهای پردازش جریان
Bytewax قابلیتهای پردازش جریان stateful بومی پایتون را برای تحولات داده بلادرنگ ارائه میدهد. PyFlink موتور پردازش جریان توزیعشده Apache Flink را از طریق APIهای پایتون leverage میکند.
الگوهای معماری رویدادمحور
پیادهسازیهای ETL بلادرنگ مدرن معماریهای رویدادمحور را اتخاذ میکنند که تحولات داده بر اساس رویدادهای ورودی خودکار trigger میشوند.
ادغام داده جریانی
dltHub ادغام داده بلادرنگ را با ارائه قابلیتهای بارگذاری incremental برای APIها و پایگاههای داده سادهسازی میکند.
بهترین ابزارها و چارچوبهای ETL پایتون چیست؟
| دسته | ابزار | توضیح |
|---|---|---|
| پلتفرمهای ارکستراسیون مدرن | Dagster | workflowهای asset-centric با ردیابی و observability جامع داده |
| Prefect | ارکستراسیون workflow پویا با مدیریت خطای پیشرفته | |
| Apache Airflow | زمانبندی و اتوماسیون workflow بالغ | |
| چارچوبهای پردازش داده | PyAirbyte | ادغام داده منبعباز مدرن |
| Polars | پردازش داده با عملکرد بالا | |
| PySpark | پردازش داده توزیعشده | |
| راهحلهای ETL سبک | Bonobo | چارچوب ETL مدولار برای پروتوتایپ سریع |
| Luigi | مدیریت وابستگی برای workflowهای پیچیده | |
| پردازش جریانی و بلادرنگ | Bytewax | پردازش جریان بومی پایتون |
نتیجهگیری
پایتون اکوسیستم قدرتمند برای ساخت پایپلاین ETL مدرن ارائه میدهد با کتابخانههایی مانند pandas، PyAirbyte و Polars که زمان توسعه را به طور چشمگیری کاهش میدهند در حالی که الزامات تحول داده پیچیده را مدیریت میکنند. از workflowهای CSV-to-database پایه تا معماریهای streaming بلادرنگ، انعطافپذیری پایتون نیازهای ادغام داده متنوع را در سازمانهای تمام اندازهها برآورده میکند.
سؤالات متداول
آیا پایتون برای ETL خوب است؟
بله، پایتون در ETL برتر است به دلیل اکوسیستم گسترده کتابخانه، پارادایمهای برنامهنویسی انعطافپذیر و قابلیتهای ادغام قوی. کتابخانههای مدرن مانند Polars و چارچوبهایی مانند Dagster قابلیتهای ETL پایتون را افزایش دادهاند.
آیا میتوان از pandas برای ETL استفاده کرد؟
قطعاً. Pandas قابلیتهای دستکاری داده جامع شامل پاکسازی، تبدیل، ادغام و تحلیل datasetها را فراهم میکند.
آیا از pandas یا SQL برای ETL استفاده کنم؟
SQL را برای پرسوجوهای ساختارمند و عملیات set-based در پایگاههای داده استفاده کنید؛ pandas را برای تحولات in-memory انعطافپذیر و منطق دستکاری داده پیچیده انتخاب کنید.
بهترین IDE برای ETL با پایتون چیست؟
PyCharm برای محیطهای توسعه جامع، Jupyter Notebook برای تحلیل داده تعاملی و VS Code برای توسعه سبک محبوب هستند.
پایتون یا SQL برای ETL؟ یا هر دو؟
هر دو نقاط قوت متمایز دارند که مکمل یکدیگرند. پایتون منطق تحول پیچیده و ادغام API را مدیریت میکند، در حالی که SQL در عملیات set-based و تعاملات پایگاه داده برتر است.