
برنامههای هوش مصنوعی مولد در حوزههای مالی، مراقبتهای بهداشتی، حقوقی، تجارت الکترونیک و غیره به محبوبیت چشمگیری دست یافتهاند. مدلهای زبانی بزرگ (LLMs) جزء اصلی این برنامهها هستند، زیرا میتوانند محتوای قابلفهم برای انسان را درک کرده و تولید کنند. با این حال، مدلهای از پیش آموزشدیده ممکن است در حوزههای تخصصی مانند مالی یا حقوقی عملکرد ضعیفی داشته باشند. راهحل این است که مدلهای زبانی بزرگ را با دادههای خود آموزش دهید یا بهینهسازی (fine-tune) کنید.
پیشرفتهای اخیر در آموزش مدلهای زبانی بزرگ، نحوه رویکرد سازمانها به توسعه مدلهای سفارشی را متحول کرده است. پذیرش سازمانی بهطور چشمگیری شتاب گرفته و اکثریت سازمانها اکنون بهطور منظم از هوش مصنوعی مولد مبتنی بر مدلهای زبانی بزرگ استفاده میکنند. روشهای آموزشی مدرن اکنون بر تنظیم دقیق دادهها، تکنیکهای پیشپردازش پیشرفته و رویکردهای پارامتر-کارآمد که نیازهای محاسباتی را کاهش میدهند و در عین حال عملکرد را حفظ میکنند، تأکید دارند. سازمانهایی که از این روشهای معاصر استفاده میکنند، گزارش میدهند که در وظایف خاص حوزه، بهبودهای قابلتوجهی در دقت نسبت به گزینههای عمومی به دست آوردهاند.
در ادامه، راهنمای گامبهگام توضیح میدهد که چرا و چگونه باید این کار را انجام دهید.
آموزش مدل زبانی بزرگ چیست و چگونه کار میکند؟
مدلهای زبانی بزرگ از طریق یک فرآیند آموزشی ساختاریافته به نام «آموزش» یاد میگیرند. در طول آموزش، مدل میلیاردها نمونه متنی را میخواند، الگوها را شناسایی میکند و بارها سعی میکند کلمه بعدی در یک جمله را پیشبینی کند و هر بار که اشتباه میکند، خود را اصلاح میکند. پس از این مرحله پیشآموزش، مدلها میتوانند برای وظایف خاصی مانند کمکرسانی یا ایمنی بهینهسازی شوند. آموزش از نظر محاسباتی بسیار سنگین است و اغلب به هزاران پردازنده تخصصی نیاز دارد که ماهها اجرا شوند—یکی از دلایلی که ساخت مدلهای پیشرفته بسیار پرهزینه است.
بازار مدلهای زبانی بزرگ رشد بیسابقهای را تجربه کرده است، با ارزشگذاریهای بازار کنونی که افزایش قابلتوجهی را سال به سال نشان میدهند. آموزش مدلهای زبانی بزرگ با معرفی معماریهای پیشرفتهای که شامل مکانیزمهای توجه پراکنده و پنجرههای زمینهای گسترده هستند، بهطور قابلتوجهی تکامل یافته است. این نوآوریها بار محاسباتی را کاهش میدهند و در عین حال درک زمینهای را بهبود میبخشند. رویکردهای معاصر همچنین ادغام چندوجهی را شامل میشوند که به مدلها امکان میدهد متن، تصاویر و صدا را بهطور همزمان در طول آموزش پردازش کنند. فرآیند آموزش اکنون بر کارایی از طریق تکنیکهایی مانند فشردهسازی مدل از طریق کوانتیزاسیون و تقطیر دانش تأکید دارد که میتواند اندازه مدل را بهطور قابلتوجهی کاهش دهد و در عین حال عملکرد را حفظ کند.
روشهای آموزشی همچنین رویکردهای مدیریت داده سیستماتیک را پذیرفتهاند. چارچوبهای مدرن بر حذف تکرار معنایی و مستندسازی مجموعه دادهها مطابق با اصول FAIR تأکید دارند تا یکپارچگی و قابلیت بازتولید دادههای آموزشی را تضمین کنند. سازمانها اکنون استراتژیهای حذف تکرار سهلایه را پیادهسازی میکنند: تطبیق دقیق از طریق هش MD5، تطبیق فازی با استفاده از الگوریتمهای MinHash و خوشهبندی معنایی برای حذف محتوای اضافی که ممکن است منجر به بیشبرازش (overfitting) شود.
چرا باید یک مدل زبانی هوش مصنوعی را با دادههای خود آموزش دهید؟
مدلهای زبانی بزرگ مانند ChatGPT، Gemini، Llama، Bing Chat و Copilot وظایفی مانند تولید متن، ترجمه، خلاصهسازی و تشخیص گفتار را خودکار میکنند. با این حال، ممکن است خروجیهای نادرست، مغرضانه یا ناامنی تولید کنند، بهویژه برای موضوعات تخصصی. آموزش با دادههای حوزه خاص به شما کمک میکند:
- دقت بیسابقهای در زمینههای تخصصی (مالی، مراقبتهای بهداشتی، حقوقی و غیره) به دست آورید.
- روشها و چارچوبهای استدلال اختصاصی را جاسازی کنید.
- الزامات انطباق را با کنترل دقیق بر خروجیها برآورده کنید.
- بهبودهای ۲۰-۳۰ درصدی در دقت نسبت به مدلهای عمومی به دست آورید.
پذیرش خاص صنعت بهطور قابلتوجهی متفاوت است، با خردهفروشی و تجارت الکترونیک که سهم بازار قوی دارند، و پس از آن خدمات مالی و مراقبتهای بهداشتی که پذیرش سریعی در برنامههای رو به بیمار نشان میدهند.
پیشنیازهای آموزش یک مدل زبانی بزرگ با دادههای خود چیست؟
الزامات داده
هزاران تا میلیونها نمونه باکیفیت، متنوع و دارای حقوق پاکشده (جفتهای درخواست/پاسخ برای تنظیم دستورالعمل). رویکردهای مدرن بر اهمیت دادهها به جای حجم تأکید دارند.
زیرساخت فنی
خوشههای GPU/TPU، ذخیرهسازی کافی، RAM و چارچوبهایی مانند PyTorch یا TensorFlow. قیمتگذاری بازار کنونی برای GPUهای پیشرفته نیاز به سرمایهگذاری قابلتوجهی دارد؛ تنظیمات کامل چند-GPU میتواند پرهزینه باشد.
انتخاب مدل
یک مدل پایه منبعباز یا دارای مجوز انتخاب کنید و بین تنظیم کامل یا روشهای پارامتر-کارآمد مانند LoRA تصمیم بگیرید.
استراتژی آموزش
تنظیمهایپرپارامتر، معیارهای واضح، خطوط لوله تست و کنترل نسخه. رویکردهای بهینهسازی بیزی اکنون نرخهای یادگیری بهینه را بهطور قابلتوجهی سریعتر از جستجوی شبکهای شناسایی میکنند.
ملاحظات عملیاتی
بودجهبندی، زمانبندی، نیروی انسانی، برنامهریزی استقرار. هزینههای آموزش برای مدلهای پیشرفته میتواند بسته به دامنه و الزامات بهطور قابلتوجهی متفاوت باشد.
ارزیابی
از معیارها و بازخورد انسانی استفاده کنید؛ بر اساس ضعفها تکرار کنید.
استقرار
مدل را بهینهسازی، ارائه و نظارت کنید بهصورت امن و کارآمد.
چارچوبهای ضروری مدیریت داده و تضمین کیفیت
مستندسازی مجموعه داده مطابق با FAIR
اصول FAIR شفافیت و قابلیت استفاده مجدد مجموعه داده را تضمین میکنند.
پیشگیری از آلودگی و یکپارچگی داده
استراتژیهای پیشگیری از آلودگی شامل حذف تکرار دقیق، فازی و معنایی است.
کنترل کیفیت و کاهش تعصب
نظارت انسانی در حلقه و ابزارهایی مانند Snorkel نظارت ضعیف را فراهم میکنند؛ حسابرسیهای تعصب با AI Fairness 360 به تضمین عدالت کمک میکنند.
مؤثرترین روشهای تنظیم پارامتر-کارآمد
تطبیق رتبه پایین (LoRA) و انواع آن
- LoRA: ماتریسهای رتبه پایین قابل آموزش را وارد میکند در حالی که پارامترهای پایه را ثابت نگه میدارد.
- QLoRA: کوانتیزاسیون ۴ بیتی را اضافه میکند و امکان تنظیم مدلهای بزرگ پارامتری را روی یک GPU واحد فراهم میکند.
- انواع مانند DoRA و AdaLoRA: کارایی را بیشتر بهینه میکنند.
تنظیم پارامتر-کارآمد (PEFT) به سازمانها امکان میدهد درصد کمی از پارامترهای کل مدل را آموزش دهند و در عین حال اکثر عملکرد تنظیم کامل را حفظ کنند.
بهترین روشهای پیادهسازی
- مقادیر رتبه بین ۸-۶۴ معمول هستند.
- مقادیر آلفا بین ۱۶-۳۲ تعادل بین پایداری و انعطافپذیری برقرار میکنند.
- گسترش LoRA به لایههای FFN و جاسازیها برای نتایج بهتر.
چگونه پلتفرمهای ادغام داده مدرن پایپلاین LLM را ساده میکنند
- تکامل ETL منبعباز کانکتورهای بومی ابری و کانتینری (مانند Airbyte) را به ارمغان آورده است.
- پایگاههای داده برداری مانند Weaviate، Qdrant، Milvus از ذخیرهسازی جاسازی مقیاسپذیر پشتیبانی میکنند.
- ابزارهای ارکستراسیون (Dagster، Airflow) و سیستمهای نسخهبندی داده قابلیت بازتولید را حفظ میکنند.
قیمتگذاری GPU ابری بین ارائهدهندگان بهطور قابلتوجهی متفاوت است و نمونههای GPU پیشرفته نیاز به استراتژیهای بهینهسازی هزینه دقیق برای عملیات آموزشی پایدار دارند.
معماریهای حفظ حریم خصوصی برای دادههای اختصاصی
- رمزنگاری همومورفیک: امکان محاسبه روی دادههای رمزنگاریشده را فراهم میکند.
- یادگیری فدرال با حریم خصوصی تفاضلی: همکاری بین مؤسسات را بدون اشتراک دادههای خام امکانپذیر میکند.
- سختافزار محاسبات محرمانه (Intel SGX، AMD SEV): فرآیندهای آموزشی را ایزوله میکند.
حریم خصوصی تفاضلی تضمینهای ریاضی ارائه میدهد که نقاط داده فردی نمیتوانند بهطور قابلاعتماد از مدلهای آموزشدیده استخراج شوند.
چگونه یک مدل زبانی هوش مصنوعی را در ۸ مرحله ساده آموزش دهیم
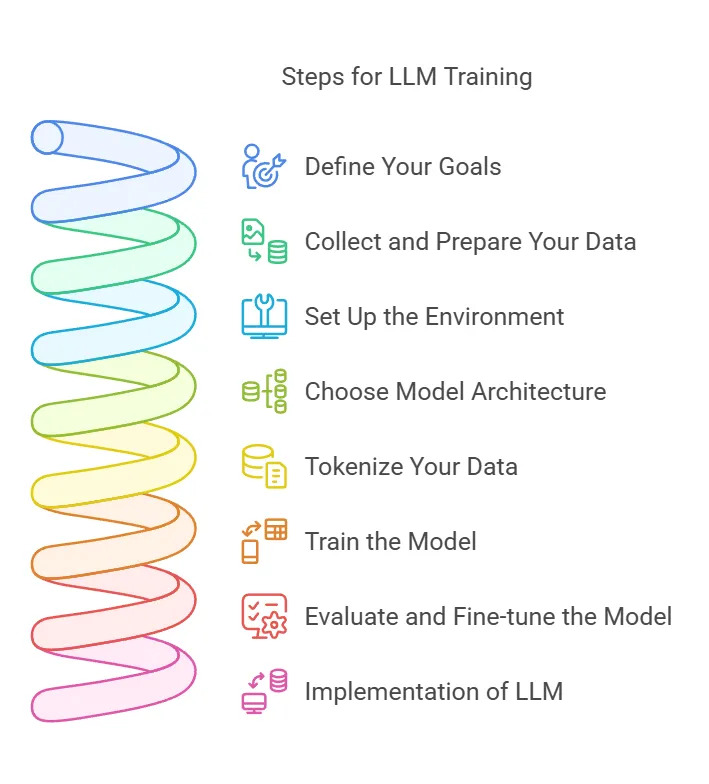
۱. اهداف خود را تعریف کنید – شاخصهای کلیدی عملکرد (KPIها)، نیازهای انطباق و معیارهای موفقیت را تعیین کنید.
۲. جمعآوری و آمادهسازی داده – پلتفرمهایی مانند Airbyte با بیش از ۶۰۰ کانکتور، ورود داده را ساده میکنند.
۳. محیط را تنظیم کنید – GPU/TPUها را تهیه کنید، چارچوبها را نصب کنید، نظارت را پیکربندی کنید.
۴. معماری مدل را انتخاب کنید – GPT، BERT، T5 و غیره؛ LoRA/QLoRA را در نظر بگیرید.
۵. دادههای خود را توکنیزه کنید – به راهنمای توکنیزهسازی LLM مراجعه کنید.
۶. مدل را آموزش دهید – از دقت مختلط، نقاط بررسی گرادیان، جستجوی هایپرپارامتر بیزی استفاده کنید.
۷. ارزیابی و تنظیم – با استفاده از معیارها، بازخورد انسانی و روشهای PEFT تکرار کنید.
۸. مدل زبانی را پیادهسازی کنید – از طریق API مستقر کنید، نظارت کنید، در صورت رانش داده دوباره آموزش دهید.
چگونه باید یک مدل زبانی را پس از آموزش ارزیابی کنید؟
- آزمایش معیار – MMLU، GSM8K، HumanEval و غیره.
- ارزیابی خاص وظیفه – سناریوهای مرتبط با حوزه (مالی، مراقبتهای بهداشتی، حقوقی…).
- ایمنی و استحکام – آزمایشهای خصمانه، ارزیابی تعصب، تیمسازی قرمز.
- ارزیابی انسانی – کارشناسان حوزه خروجیها را بررسی میکنند.
- معیارهای عملکرد – تأخیر، توان، حافظه، هزینه.
- نظارت مستمر – تشخیص رانش، برنامهریزی آموزش مجدد.
چالشهای کلیدی و راهحلها در آموزش دادههای اختصاصی
هزینههای آمادهسازی داده میتواند بسته به دامنه آموزش بهطور قابلتوجهی متفاوت باشد، از سرمایهگذاریهای متوسط برای تنظیم تا هزینههای قابلتوجه برای پیشآموزش از ابتدا.
| چالش | راهحل |
| دادههای ناسازگار یا مغرضانه | پاکسازی خودکار، حاشیهنویسی سهگانه کور، تقویت داده مصنوعی |
| هزینه محاسباتی بالا | LoRA/QLoRA، مقیاسبندی ابری الاستیک، نمونههای نقطهای |
| امنیت و انطباق | حریم خصوصی تفاضلی، یادگیری فدرال، لاگهای حسابرسی رمزنگاریشده |
| ادغام با سیستمهای قدیمی | ماژولار بودن آداپتور، انتزاع API، خطوط لوله CI/CD خودکار |
نتیجهگیری
آموزش یک مدل زبانی بزرگ با دادههای خود، استفاده هدفمند، دقت بالاتر، کاهش تعصب و کنترل بیشتر داده را امکانپذیر میکند. با دنبال کردن فرآیند هشتمرحلهای که در اینجا شرح داده شده است—و با استفاده از تنظیم پارامتر-کارآمد، رمزنگاری همومورفیک و یادگیری فدرال—میتوانید راهحلهای هوش مصنوعی قدرتمند و خاص حوزه را بسازید و در عین حال امنیت، انطباق و کارایی عملیاتی را حفظ کنید.
با رشد سریع در پذیرش هوش مصنوعی سازمانی و افزایش تعداد موارد استفاده تولیدی، سازمانهایی که جریانهای کاری آموزش مدل زبانی سفارشی را تسلط یابند، مزایای رقابتی قابلتوجهی به دست خواهند آورد. کلید در ایجاد خطوط لوله داده قوی است که میتوانند دادههای آموزشی با کیفیت بالا و خاص حوزه را بهطور قابلاعتماد ارائه دهند و در عین حال استانداردهای امنیتی و مدیریتی را حفظ کنند.
سؤالات متداول
چرا باید یک مدل زبانی را با دادههای اختصاصی آموزش داد به جای استفاده از یک مدل عمومی؟ مدلهای عمومی با nuances خاص حوزه مشکل دارند. آموزش سفارشی معمولاً بهبودهای ۲۰-۳۰ درصدی در دقت به دست میدهد.
فرآیند آموزش اخیراً چگونه تکامل یافته است؟ پیشرفتهایی مانند LoRA/QLoRA، یادگیری چندوجهی و پنجرههای زمینهای طولانیتر، تنظیم را سریعتر، ارزانتر و قدرتمندتر میکنند.
چه دادهها و زیرساختی مورد نیاز است؟ حجم زیادی از دادههای با کیفیت بالا و پاکشده حقوقی به علاوه خوشههای GPU/TPU و چارچوبهای ML (PyTorch، TensorFlow و غیره).
چگونه میتوان اطمینان حاصل کرد که دادهها با کیفیت بالا، امن و مطابق هستند؟ مستندسازی FAIR، حذف تکرار چندسطحی، حسابرسیهای تعصب، حریم خصوصی تفاضلی و محاسبات محرمانه.
مؤثرترین روشهای تنظیم چیست؟ روشهای پارامتر-کارآمد (LoRA، QLoRA) اکثر پارامترها را ثابت نگه میدارند و آداپتورهای سبک را آموزش میدهند، که تنظیم مدلهای بسیار بزرگ را روی یک GPU واحد امکانپذیر میکند.